RDD(Resilient Distributed Dataset)弹性分布式数据集
Spark程序如何工作:
step1: 从外部数据创建输入RDD
step2: 使用诸如filter()这样的转换操作对RDD进行转换,以定义新的RDD
step3: 告诉Spark对需要重用的中间结果RDD执行persist()操作
step4: 使用行动操作(如count(), first()等)来触发一次并行计算,Spark会计算进行优化后再处理。
创建RDD
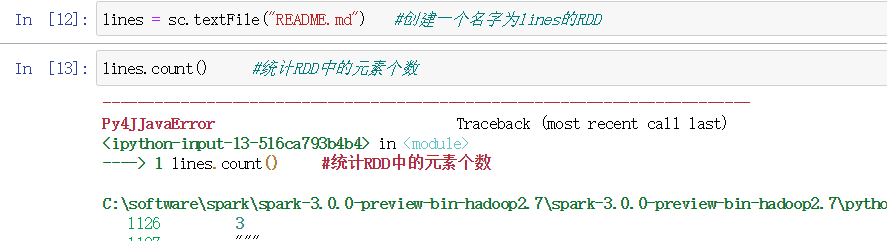
方式1 读取外部数据集
最常用的 之前学过使用textFile()创建RDD
常用的较简单的操作是:把程序中一个已有的集合传给SparkContext的parallelize()方法
这方法需要将整个数据集先放在一台机器的内存中
lines = sc.parallelize(["pandas", "i like pandas"])
方式2 再驱动器程序中对一个集合进行并行化
RDD操作