提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、键值对RDD数据分区
Spark目前支持Hash分区、Range分区和用户自定义分区。Hash分区为当前默认的分区。分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分区和Reduce的个数。
1、注意:
(1)只有Key-Value类型的RDD才有分区器,非Key-Value类型的RDD分区器的值是None。
(2)每个RDD的分区ID范围:0~(numPartitions-1),决定这个值是属于哪个分区的。
2、获取RDD分区
(1)创建包名com.zhm.spark.operator.partitioner
(2)代码实现
package com.zhm.spark.operator.partitioner;
import org.apache.spark.Partitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.Function2;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName Test01_partitioner
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 15:36
* @Version 1.0
*/
public class Test01_partitioner {
/**
* 刚刚转换来的key—value类型的RDD的分区是empty
*/
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaPairRDD<String, Integer> javaRDD = sparkContext.parallelizePairs(Arrays.asList(new Tuple2("a", 1),
new Tuple2("b", 2), new Tuple2("a", 3)), 2);
//4、获取javaRDD的分区器
Optional<Partitioner> partitioner = javaRDD.partitioner();
//5、输出分区器
System.out.println("javaRDD的分区器是:"+partitioner);
//6、对javaRDD根据key进行累加
JavaPairRDD<String, Integer> reduceByKey = javaRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//7、获取reduceByKey的分区器
Optional<Partitioner> partitioner1 = reduceByKey.partitioner();
System.out.println("reduceByKey的分区器:"+partitioner1);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:

1.1 Hash分区
HashPartitioner分区的原理:对于给定的key,计算其他hashcode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否者+0),最后返回的值就是这个key所属的分区ID。
按照当初首字母的hashcode值%分区个数
A 100万条数据 假设有三个分区(0、1、2)
B 1万条
C 1万条
D 100万条数据
E 一万条
F 一万条
G 100万条
可能的分区结果:
0号分区
A 100万条数据
B 100万条数据
C 100万条数据
1号分区
B 一万条
E 一万条
2号分区
C 1万条
F 1万条
以上展示的是HashPartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会·导致某些分区拥有RDD的全部数据。
代码实现:
package com.zhm.spark.operator.partitioner;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName Test02_hashPartitioner
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/29 15:47
* @Version 1.0
*/
public class Test02_hashPartitioner {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaPairRDD<String, String> pairRDD = sparkContext.parallelizePairs(Arrays.asList(new Tuple2<>("1", "1"),
new Tuple2<>("2", "1"), new Tuple2<>("3", "1"), new Tuple2<>("4", "1"),
new Tuple2<>("5", "1"), new Tuple2<>("6", "1"), new Tuple2<>("7", "1"),
new Tuple2<>("8", "1")),2);
//4、查看
pairRDD.saveAsTextFile("output/partition_hash01");
//5、重新分区
JavaPairRDD<String, String> partitionBy = pairRDD.partitionBy(new HashPartitioner(4));
//6、查看
partitionBy.saveAsTextFile("output/partition_hash02");
//x 关闭 sparkContext
sparkContext.stop();
}
}
1.2 Ranger分区
RangePartitioner作用:将一定范围内的数映射到某一分区内,尽量保证每个分区中数据量均匀,而且分区和分区之间是有序的,应该分区中的元肯定都是比另一个分区内的元素小或大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
实现的过程为:
第一步:先从整个RDD中采用水塘抽样算法,抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;
第二步:判断key在rangeBounds中所处的范围,给定该key值在下一个RDD的分区id下标;该分区器要求RDD的KEY类型必须是可以排序的
(1)我们假设有100万条数据要分4个区
(2)从100万条中抽100个数(1,2,3,…,100)
(3)对100个数进行排序,然后均匀的分为四段
(4)获取100万条数据,每个值与4个分区的范围比较,放入合适分区
二、累加器
1、累加器:分布式共享只写变量
2、原因:Executor和Executor之间不能读数据
3、原理:累加器用来把Executor端变量信息聚合到Driver端。在Driver中定义的一个变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本值后,传回Driver端进行合并计算。
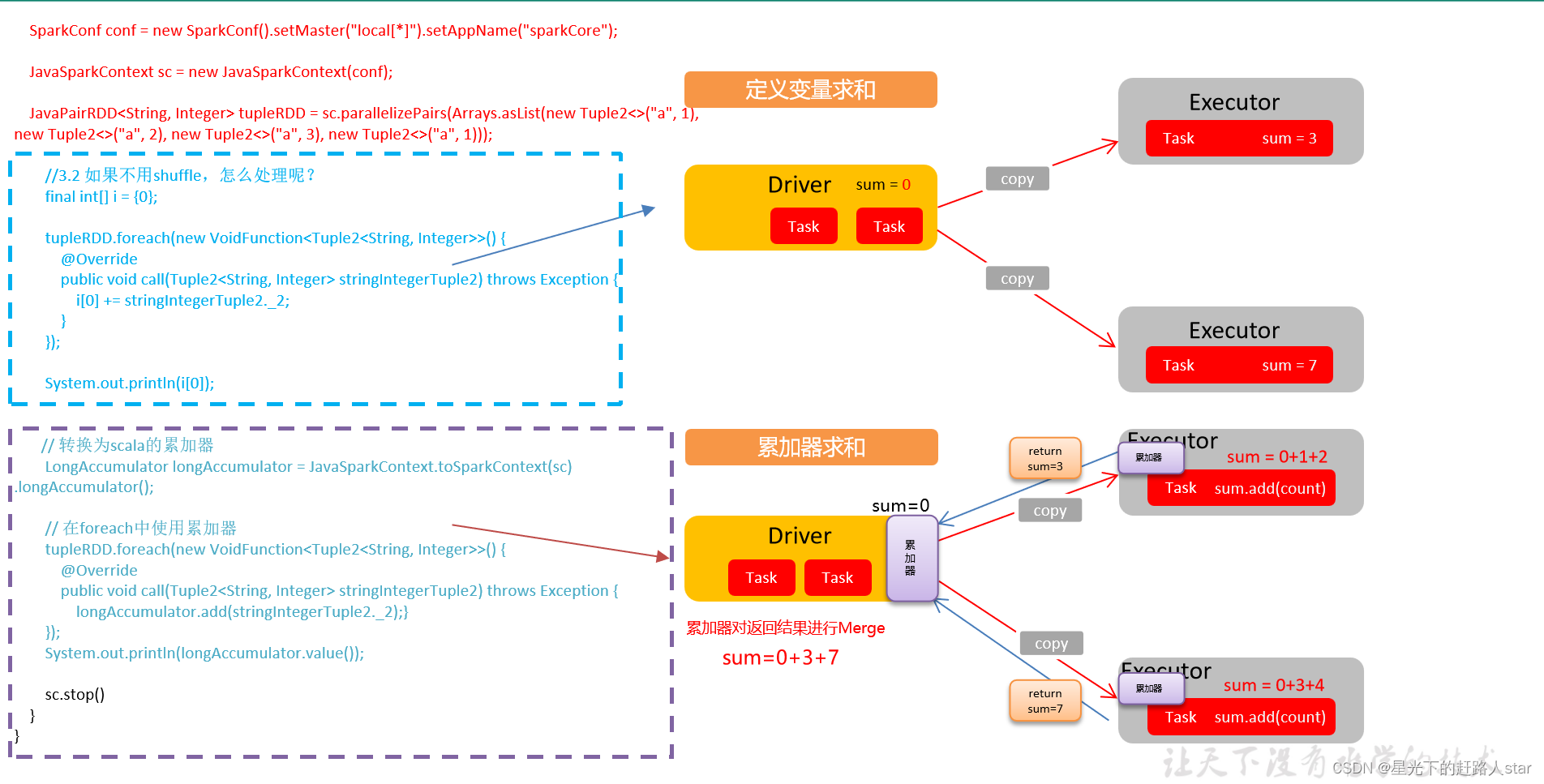
4、累加器的使用
(1)累加定义
LongAccumulator longAccumulator = JavaSparkContext.toSparkContext(sparkContext).longAccumulator();
(2)累加器添加数据(累加器.add方法)
(3)累加器获取数据(累加器.value)
5、创建包名:com.zhm.spark.operator.accumulator
6、代码实现
package com.zhm.spark.operator.accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.util.LongAccumulator;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName Test01_ACC
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/30 9:09
* @Version 1.0
*/
public class Test01_ACC {
/**
* 累加器是一个分布式共享只写变量
* 累加器要放在行动算子中,因为转换算子执行的次数取决于job的数量,一个spark应用由多个行动算子,
* 那么转换算子中的累加器可能会发生不止一次更新,导致结果出错。
*/
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaPairRDD<String, Integer> javaPairRDD = sparkContext.parallelizePairs(Arrays.asList(new Tuple2<>("a", 1), new Tuple2<>("a", 2), new Tuple2<>("a", 3), new Tuple2<>("a", 4)));
System.out.println("--------------使用reduceByKey走shuffle统计(效率低)--------------------");
JavaPairRDD<String, Integer> reduceByKey = javaPairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//收集输出
reduceByKey.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
System.out.println(stringIntegerTuple2);
}
});
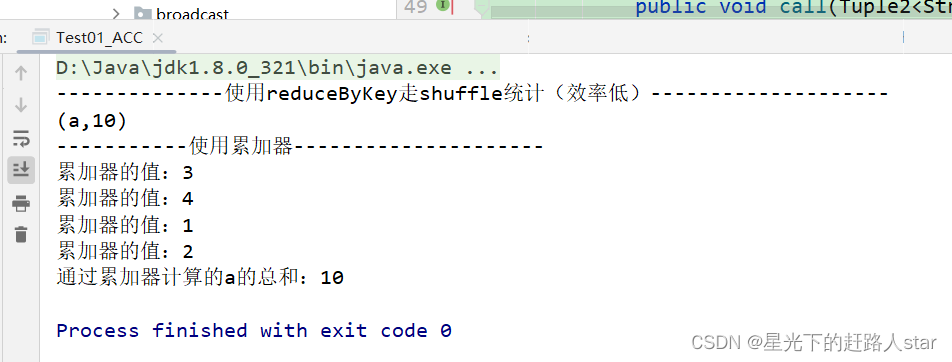
System.out.println("-----------使用累加器---------------------");
LongAccumulator longAccumulator = JavaSparkContext.toSparkContext(sparkContext).longAccumulator();
//在foreach中使用累加器统计a的value之和
javaPairRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
//不要在executor端获取累加器的值,因为不准确,因此我们说累加器叫做分布式共享变量
longAccumulator.add(stringIntegerTuple2._2);
//输出累加器的值,可看到获取到的累加器的值不是最终值
System.out.println("累加器的值:"+longAccumulator.value());
}
});
System.out.println("通过累加器计算的a的总和:"+longAccumulator.value());
//x 关闭 sparkContext
sparkContext.stop();
}
}
注意:Executor端的任务不要读取累加器的值(例如:在Executor端调用sum.value,获取的值不是累加器最终的值)。因为累加器是一个分布式共享只写变量。
7、累加器要放在行动算子中
因为转换算子执行的次数决定job的数量,如果一个spark应用由多个行动算子,那么转换算子中的累加器可能会发生不止一次更新,导致结果错误。所以,如果想要在一个无论失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动算子中。
8、运行结果:
三、广播变量
1、广播变量:分布式共享只读变量
2、原因:广播变量可用来向所有工作节点高效分发较大的对象,一个只读值,以供一个或多个SparkTask使用。
3、例如:如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来会很顺手。就是在多个Task并行操作中使用同一个变量,Spark会为每个Task任务分别发送。
4、使用广播变量步骤:
(1)调用SparkContext.broadcast(广播变量)创建出一个广播对象,任何可序列化的类型都可以这么实现。
(2)通过广播变量.value,访问该对象的值。
(3)广播变量只会被发到各个节点一次,作为只读值处理(修改这个值不会影响到别的节点)。
5、原理说明

6、代码实现
package com.zhm.spark.operator.broadcast;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.broadcast.Broadcast;
import java.util.Arrays;
import java.util.List;
/**
* @ClassName Test01_BroadCasr
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/30 9:24
* @Version 1.0
*/
public class Test01_BroadCast {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、创建RDD数据集
JavaRDD<Integer> javaRDD = sparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
//奇数列表
List<Integer> LuckList = Arrays.asList(1, 3, 6);
//4、使用List,为每个Task都创建一个List,浪费内存
JavaRDD<Integer> filter = javaRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer v1) throws Exception {
return LuckList.contains(v1);
}
});
//5、收集输出
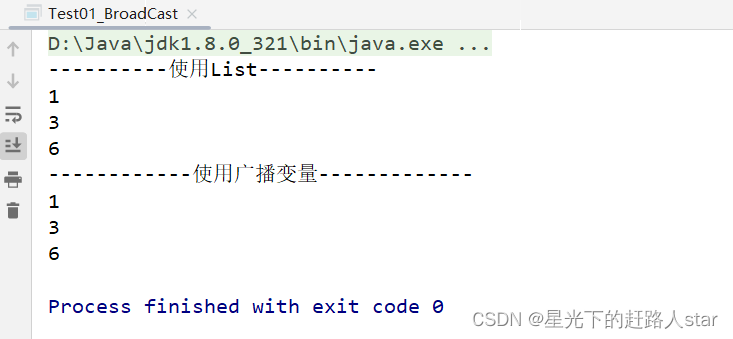
System.out.println("----------使用List----------");
filter.collect().forEach(System.out::println);
//6、使用广播变量,只会发送一个数据到每个Executor
Broadcast<List<Integer>> broadcast = sparkContext.broadcast(LuckList);
JavaRDD<Integer> filter1 = javaRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer v1) throws Exception {
return broadcast.value().contains(v1);
}
});
System.out.println("------------使用广播变量-------------");
filter1.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
四、SparkCore实战
4.1 数据准备
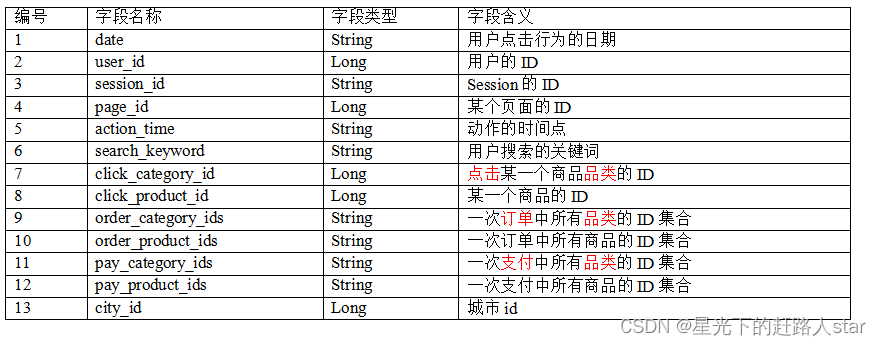
1、数据格式

2、数据详细字段说明
4.2 需求:Top10热门品类
1、需求说明:
品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量(次数)来统计热门品类。
鞋========>点击数 下单数 支付数
衣服=======>点击数 下单数 支付数
电脑=======>点击数 下单数 支付数
例如,综合排名 = 点击数20% + 下单数30% + 支付数*50%
为了更好的泛用性,当前案例按照点击次数进行排序,如果点击相同,按照下单数,如果下单还是相同,按照支付数。
4.2.1 需求分析(方案一)类对象
采用类对象的方式实现。
4.2.2 需求实现
1、添加lombok的插件
2、添加依赖lombok可以省略getset代码
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
3、在bean包下创建两个存放数据的类UserVisitAction和CategoryCountInfo
import lombok.Data;
/**
* @ClassName UserVisitAction
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/30 9:35
* @Version 1.0
*/
@Data
public class UserVisitAction {
private String date; //用户点击行为的日期
private Long user_id; //用户的ID
private String session_id; //Session的ID
private Long page_id; //某个页面的ID
private String action_time; //动作的时间点
private String search_keyword; //用户搜索的关键词
private Long click_category_id; //点击某一个商品品类的ID
private Long click_product_id; //某一个商品的ID
private String order_category_ids; //一次订单中所有品类的ID集合
private String order_product_ids; //一次订单中所有商品的ID集合·1
private String pay_category_ids; //一次支付中所有品类的ID集合
private String pay_product_ids;//一次支付中所有商品的ID集合
private Long city_id; //城市ID
public UserVisitAction(String date, Long user_id, String session_id, Long page_id,
String action_time, String search_keyword,
Long click_category_id, Long click_product_id,
String order_category_ids, String order_product_ids,
String pay_category_ids, String pay_product_ids,
Long city_id) {
this.date = date;
this.user_id = user_id;
this.session_id = session_id;
this.page_id = page_id;
this.action_time = action_time;
this.search_keyword = search_keyword;
this.click_category_id = click_category_id;
this.click_product_id = click_product_id;
this.order_category_ids = order_category_ids;
this.order_product_ids = order_product_ids;
this.pay_category_ids = pay_category_ids;
this.pay_product_ids = pay_product_ids;
this.city_id = city_id;
}
}
import lombok.Data;
/**
* @ClassName CategoryCountInfo
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/30 9:43
* @Version 1.0
*/
@Data
public class CategoryCountInfo implements Comparable{
private Long categoryId;
private Long clickCount; //点击数
private Long orderCount; //下单数
private Long payCount; //支付数
public CategoryCountInfo() {
}
public CategoryCountInfo(Long categoryId, Long clickCount, Long orderCount, Long payCount) {
this.categoryId = categoryId;
this.clickCount = clickCount;
this.orderCount = orderCount;
this.payCount = payCount;
}
@Override
public int compareTo(Object o) {
CategoryCountInfo categoryCountInfo= (CategoryCountInfo) o;
if (this.getClickCount()==categoryCountInfo.getClickCount()){
if (this.getOrderCount()==categoryCountInfo.getOrderCount()){
if (this.getPayCount()==categoryCountInfo.getPayCount()){
return 0;
}
else return (int) (this.getPayCount()-categoryCountInfo.getPayCount());
}
else return (int) (this.getOrderCount()-categoryCountInfo.getOrderCount());
}
else return (int) (this.getClickCount()-categoryCountInfo.getClickCount());
}
}
4、创建Top10类,编写核心业务代码实现
import com.zhm.spark.Top10Demo.bean.CategoryCountInfo;
import com.zhm.spark.Top10Demo.bean.UserVisitAction;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.serializer.KryoSerializer;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Iterator;
/**
* @ClassName Top10
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/30 9:46
* @Version 1.0
*/
public class Top10 {
public static void main(String[] args) throws ClassNotFoundException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01").set("spark.serializer", KryoSerializer.class.getName()).
registerKryoClasses(new Class[]{
Class.forName(UserVisitAction.class.getName()),Class.forName(CategoryCountInfo.class.getName())});
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//2019-07-17_95_26070e87-1ad7-49a3-8fb3-cc741facaddf_37_2019-07-17 00:00:02_手机_-1_-1_null_null_null_null_3
//3、创建RDD数据集(按行读取文件数据)
JavaRDD<String> javaRDD = sparkContext.textFile("inputTop10");
//4、转化为UserVisitAction对象储存(map)
JavaRDD<UserVisitAction> map = javaRDD.map(new Function<String, UserVisitAction>() {
@Override
public UserVisitAction call(String v1) throws Exception {
String[] split = v1.split("_");
UserVisitAction userVisitAction = new UserVisitAction(split[0], Long.parseLong(split[1]),
split[2], Long.parseLong(split[3]), split[4], split[5], Long.parseLong(split[6]), Long.parseLong(split[7]), split[8],
split[9], split[10], split[11], Long.parseLong(split[12])
);
return userVisitAction;
}
});
//5、遍历map,将数据炸裂为(CategoryCountInfo对象)
JavaRDD<CategoryCountInfo> categoryCountInfoJavaRDD = map.flatMap(new FlatMapFunction<UserVisitAction, CategoryCountInfo>() {
@Override
public Iterator<CategoryCountInfo> call(UserVisitAction userVisitAction) throws Exception {
ArrayList<CategoryCountInfo> list = new ArrayList<>();
//代表是点击行为
if (userVisitAction.getClick_category_id() != Long.valueOf(-1)) {
list.add(new CategoryCountInfo(userVisitAction.getClick_category_id(), 1L, 0L, 0L));
}
//代表是下单行为
if (!userVisitAction.getOrder_category_ids().equals("null")) {
String[] split = userVisitAction.getOrder_category_ids().split(",");
for (String s : split) {
list.add(new CategoryCountInfo(Long.parseLong(s), 0L, 1L, 0L));
}
}
if (!userVisitAction.getPay_category_ids().equals("null")) {
String[] split = userVisitAction.getPay_category_ids().split(",");
for (String s : split) {
list.add(new CategoryCountInfo(Long.parseLong(s), 0L, 0L, 1L));
}
}
return list.iterator();
}
});
//6、将 categoryCountInfoJavaRDD转换为key-valueRDD
JavaPairRDD<Long, CategoryCountInfo> longCategoryCountInfoJavaPairRDD = categoryCountInfoJavaRDD.mapToPair(new PairFunction<CategoryCountInfo, Long, CategoryCountInfo>() {
@Override
public Tuple2<Long, CategoryCountInfo> call(CategoryCountInfo categoryCountInfo) throws Exception {
return new Tuple2<>(categoryCountInfo.getCategoryId(), categoryCountInfo);
}
});
//7、将longCategoryCountInfoJavaPairRDD的值累加
JavaPairRDD<Long, CategoryCountInfo> longCategoryCountInfoJavaPairRDD1 = longCategoryCountInfoJavaPairRDD.reduceByKey(new Function2<CategoryCountInfo, CategoryCountInfo, CategoryCountInfo>() {
@Override
public CategoryCountInfo call(CategoryCountInfo v1, CategoryCountInfo v2) throws Exception {
//计算点击的和
v1.setClickCount(v1.getClickCount() + v2.getClickCount());
//计算下单的和
v1.setOrderCount(v1.getOrderCount() + v2.getOrderCount());
//计算支付的和
v1.setPayCount(v1.getPayCount() + v2.getPayCount());
return v1;
}
});
//8、将longCategoryCountInfoJavaPairRDD1转换为value型的RDD
JavaRDD<CategoryCountInfo> map1 = longCategoryCountInfoJavaPairRDD1.map(new Function<Tuple2<Long, CategoryCountInfo>, CategoryCountInfo>() {
@Override
public CategoryCountInfo call(Tuple2<Long, CategoryCountInfo> v1) throws Exception {
return v1._2;
}
});
//9、排序
JavaRDD<CategoryCountInfo> sortBy = map1.sortBy(new Function<CategoryCountInfo, CategoryCountInfo>() {
@Override
public CategoryCountInfo call(CategoryCountInfo v1) throws Exception {
return v1;
}
}, false, 2);
//10、获取数据集前10个
sortBy.take(10).forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
