Ea-GANs: Edge-Aware Generative Adversarial Networks for CrossModality MR Image Synthesis
为了利用来自多重成像模态的互补信息,跨模态 MR 图像合成引起了越来越多的研究兴趣。但是,大多数现有方法仅着眼于最小化像素/体素方向的强度差异,而忽略了图像内容结构的纹理细节,这影响了合成图像的质量。具体来说,我们集成了边缘信息,以反映图像内容的纹理结构并描绘图像中不同对象的边界,以缩小这种差距。对应于不同的学习策略,提出了两个框架,即生成器诱导的 Ea-GAN(gEa-GAN)和鉴别器诱导的 Ea-GAN(dEa-GAN)。 gEa-GAN 通过其生成器并入了边缘信息,而 dEa-GAN 进一步从生成器和鉴别器中获取了边缘信息,因此还可以从边缘上学习边缘相似性。
综述
磁共振成像(MRI)通过设置任务特定的扫描参数产生不同的图像形式,已广泛用于医学图像分析中。在分析过程中,来自多个MR成像模态(例如 T1 加权,T2 加权,FLAIR)的图像将一起处理,因为每个模态都显示出独特的软组织对比度。例如,多模式 MR 图像已被集体用于研究人类大脑的神经解剖结构,以进行疾病诊断或治疗计划, 来自多模态的补充信息比来自单个成像模态的信息具有更好的预测能力。同时,由于不同临床中心之间的模态缺失和模态不一致,在临床和研究中并不总是满足使用多种 MR 成像方式进行分析的高要求,这不利地影响了诊断和治疗的质量。因此,多模态 MR 图像合成 近来引起了越来越多的研究兴趣,并且为应对临床和研究中不足的形式的局限性进行了越来越多的研究。
医学图像合成被定义为未知目标模式图像和给定源模式图像之间的映射,已经显示了广泛的应用,例如,虚拟数据集创建,缺失图像插补和图像超分辨。 当前的方法可以大致分为两类。 第一个类别是指基于图集的方法。这些方法利用源和目标模态中的成对图像图集,计算源模态中的 Atlas-to-Image 转换,然后探索这种转换以从其对应的图像中合成类似目标模态的图像目标模式图集。由于大多数地图集都是建立在健康受试者身上的,因此这些方法在具有明显异常的图像上的表现不太令人满意。 第二类是基于学习的方法,可以缓解此问题。 具体来说,这些方法直接学习了从源模式到目标模式的映射。 一旦训练集适当地包含了病理学,这些信息就可以被学习的模型捕获,这样,诸如脑部肿瘤之类的异常现象也可以在目标模态图像中合成。
一大类基于学习的合成方法训练了一个非线性模型,该模型将每个小源模式小块映射到目标模式中具有相同位置的相应小块中心的像素/体素。(作者列举了一系列基于传统方法的例子)为了解决上述问题,基于深度学习的模型,例如卷积神经网络(CNN)和完全卷积网络(FCN),已被用来自动学习具有更好描述能力的特征。 此外,研究人员最近发现,与基于小补丁的方法相比,使用基于全图像或大补丁的分析可以更好地了解像素/体素之间的隐式依赖性,而所需的计算成本却更少。
此外,条件生成对抗网络(cGAN)最近在通用图像合成中取得了可喜的成果。基本上,cGAN 模型由两个模块组成,一个用于合成图像的生成器(例如,基于 CNN 的传统图像模型)和一个用于将合成图像与真实图像区分开的鉴别器。这两个模块相互竞争以达到纳什均衡。最近,基于 cGAN 的图像合成模型也已成功应用于医学图像,例如视网膜图像,CT 图像,PET 图像, MR 图像,超声图像和内窥镜图像。这些方法大多数都可用于 2D 图像合成。对于 3D 医学成像数据,这些方法独立地估计每个轴向切片,然后将它们串联起来以形成目标 3D 图像。以这种方式,合成的 3D 图像的冠状和矢状切片是由分别来自轴向平面的估计线形成的,因此可能显示出强烈的不连续性,从而损害了整个对象的合成质量。
在现有的 cGAN 模型中,Pix2pix 是一项具有代表性的工作,它在图像合成方面取得了非常有希望的结果,并且是我们工作的比较基准。 因此,简要介绍如下。 在 Pix2pix 中,其生成器 G 从输入源图像 x 合成类似于真实目标图像 y 的图像 G(x),而其鉴别符 D 试图从中区分出合成图像对(x,G(x))。 其对应的实像对(x,y)。 生成器 G 的目标公式如下:LGcGAN = Ex∼pdata(x)[log(1−D(x,G(x))) +λl1Ex,y∼pdata(x,y)[||y−G(x)||1],其中 E 表示最大似然估计。Pix2pix 中 D 的目标定义为:LDcGAN =−Ex,y∼pdata(x,y)[log D(x, y)] −Ex∼pdata(x)[log(1−D(x,G(x)))]。为了整合图像生成和识别的子任务,Pix2pix 的最终目标定义为:LcGAN =LGcGAN + LDcGAN。
方法
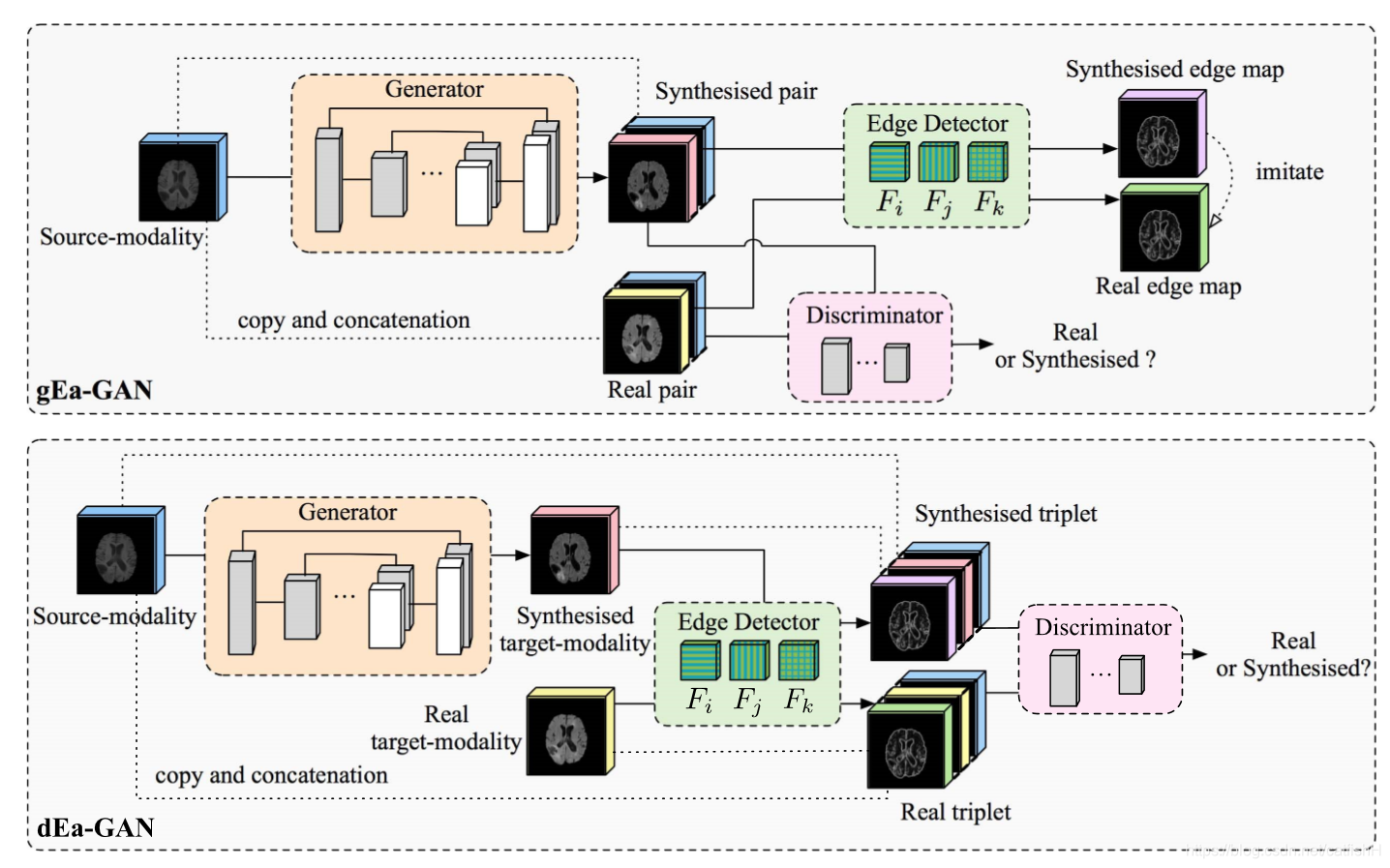
我们提出了边缘感知的生成对抗网络(Ea-GAN),以进一步克服切片不连续性和医学图像合成的大多数现有cGAN模型中较不清晰的合成问题。我们的方法基于 3D,并且提取体素强度和图像结构信息以促进合成。为了捕获图像结构,我们提取包含关键纹理信息以进行视觉识别的边缘,并将边缘图与 cGAN 模型集成以提高合成质量。具体来说,提出了两种框架,即生成器诱导的 Ea-GAN(gEa-GAN)和更高级的鉴别器诱导的 Ea-GAN(dEa-GAN),以通过不同的学习策略来学习 Ea-GAN。
大多数现有的 cGAN 模型,例如 Pix2pix,都专注于像素到像素/体素到体素的图像合成。它们通常在合成图像和真实图像之间强制执行像素/体素方向的强度相似性。但是,他们忽略了图像内容的结构,例如 MR 图像中的纹理细节。由于边缘反映了局部强度变化并显示了 MR 图像中不同组织之间的边界,因此保持边缘可以捕获图像内容的纹理结构并有助于锐化合成的 MR 图像。特别地,当在 MR 图像中包含病变时,边缘信息有助于区分病变和正常组织,并且有助于更好地描绘异常区域的轮廓。为了在 MR 图像合成期间执行边缘保留,我们基于来自合成图像和真实图像的边缘图的相似性添加了额外的约束。由于其简单性,可以使用常用的 Sobel 算符来计算边缘图,并且可以轻松地为反向传播计算其导数。
用三个 Sobel 滤波器 Fi,Fj 和 Fk 用于对图像 A 进行卷积,以生成分别与沿 i,j 和 k 方向的强度梯度相对应的三个边缘图。 然后,通过以下等式将这三个边缘图合并为最终边缘图 S(A): S(A)=[(Fi ∗ A)2 +(Fj ∗ A)2 +(Fk ∗ A)2]1/2, 其中*表示卷积运算。基于利用边缘图的不同策略,提出了两种框架,即,gEa-GAN 和 dEa-GAN。 它们每个都由三个模块组成,分别是发生器 G,鉴别器 D 和 Sobel 边缘检测器 S。这两个框架的详细信息如下。
总结
用 GAN 进行的一般是图像合成,主要分为创建虚拟数据集和从源模式到目标模式的映射两种思路。这篇文章主要是在 Pix2pix 上加入边缘约束,以便在合成时保留病变区域的边缘。
