写在前面:一个想法(如有不对的地方还请批评指正!)
对于平行语料库,由于utterances的内容是一致的,所以语音转换只需要对声学模型(Acoustic Model)建模并训练;而对于非平行语料库,由于utterances的内容不一致,所以才需要语言学模型(Linguistic Model)和声学模型(Acoustic Model)一起建模。
声学模型参数主要包括F0,delta, 频谱包络等信息。
语言学模型参数主要包括持续时间和音素的信息。
原文出处:https://ieeexplore.ieee.org/abstract/document/8063435/
仅为记录关键点:
摘要:提出了一种结合生成式对抗网络的基于静态参数的语音合成方法。尽管深度神经网络DNN技术被应用在人工合成语音,但是有一个问题:通过这种方式合成的语音和原始语音相比只有low的自然度。引起质量下降的一个问题是在生成的语音参数中经常观察到的过度平滑效应。本文介绍的GAN由两个神经网络组成:区分自然样本和生成样本的鉴别器,以及欺骗鉴别器的发生器。在所提出的包含GAN的框架中,训练鉴别器以区分自然和生成的语音参数,同时训练声学模型以最小化传统的最小生成损失和用于欺骗鉴别器的对抗性损失的加权和。由于GAN的目的是最小化自然语音参数和生成的语音参数之间的KL-divergence(即,分布差异,注:KL-divergence常用于描述两个概率分布之间的相似性),所提出的方法有效地减轻了对所生成的语音参数的过度平滑效应。我们评估了TTS和VC的有效性,并发现无论其参数设置如何,所提出的方法都可以生成比传统的最小生成错误训练算法更自然的频谱参数和F0。 此外,我们研究了各种GAN的divergence的影响,并发现最小化Earth-Mover距离的Wasserstein GAN在提高合成语音质量方面效果最好。(搬土距离(The Earth Mover's Distance,EMD)最早由Y. Rubner在1999年的文章《A Metric for Distributions with Applications to Image Databases》中提出,它是归一化的从一个分布变为另一个分布的最小代价,因此可用于表征两个分布之间的距离。)
1、介绍:
主要介绍了关于SPSS和TTS以及VC的相关概念。要注意的是(Voice Conversion)是一种从另一个语音来合成具有原始语言信息的语音的技术(在保留原始语音的语言信息的同时)。SPSS中,声学模型表征输入特征和声学特征之间的关系。为了TTS和VC,DNN被作为声学模型 [4],因为他可以比传统马尔科夫(HMM)模型和高斯混合模型(GMM)更准确地模拟输入特征和声学特征之间的关系。这些声学模型使用多种训练算法进行训练,例如最小生成误差(MGE)[7], [8]。用于训练声学模型以生成高质量语音的技术被广泛研究,因为它们可以用于TTS和VC。
方法一:降低自然语音和生成语音之间的参数差异。比如,由于自然语音和合成语音的参数分布明显不同[10],我们可以通过转换生成的语音参数来提高合成语音质量,使其分布接近自然语音的分布。比如,这可以通过在训练阶段中以参数[6]或非参数[11]方式对概率分布建模,然后通过使用模拟到的概率分布生成或变换合成语音参数来完成。更加有效的方法是使用在语音合成中分析得到的与语音质量下降一致相关的特征。全变差(Global variance,GV)和调制谱(modulation spectrum,MS)值众所周知的两个再现自然语音的特征,这些特征在训练/综合阶段[13],[14]中起到了约束作用。 Nose和Ito [15]和Takamichi等。 [13]提出了减少自然语音和生成语音的GV和MS的高斯分布之间的差异的方法。 然而,质量下降仍然是一个关键问题。
为了处理语音质量的问题,本文提出了在SPSS中使用GAN来训练声学模型。基于这个框架,文章为驯良声学模型定义了一个新的训练方法:该标准是传统MGE训练和对抗性损失函数的加权和。adversarial loss使得鉴别器将所生成的语音参数识别为自然的。由于GAN的目的是最小化自然语音参数和生成的语音参数之间的KL-divergence,我们的方法有效地减轻了过度平滑生成的语音参数的影响。此外,我们的方法可以被视为使用分析导出的特征(例如GV和MS)的显式建模的传统方法的推广,因为它有效地最小化了散度而没有明确的统计建模。此外,我们的方法中使用的鉴别器可以被解释为反欺骗,即用于检测合成语音并防止语音欺骗攻击。因此,关于 anti-spoofing的技术和想法可以应用于训练。我们评估了所提方法在基于DNN的TTS和VC中的有效性,发现该算法比传统的MGE训练算法生成更自然的频谱参数和F0,并且无论其超参数设置如何都能提高合成语音质量。 它控制着对抗性损失的权重。此外,我们研究了各种GAN的发散效应,包括图像处理相关的GAN,如最小二乘GAN(LS-GAN)和Wasserstein GAN(W-GAN),以及与语音处理相关的GAN,如 f-divergence GAN(f-GAN)。 调查结果表明,最小化搬土距离(The Earth Mover's Distance,EMD)的W-GAN在改进方面效果最好的合成语音质量。
在本文的第二部分中,我们简要回顾了基于DNN的TTS和VC中的传统训练算法。 第III节介绍了GAN,并提出了一种包含这些GAN的语音合成方法。 第四节介绍了实验评估。 我们在第五节总结了一个总结。
2、传统基于DNN的SPSS
A.、DNN-Based TTS
1>、DNNs as Acoustic Models:
In DNN-based TTS [16],表征了语言学特征和语音参数之间关系的声学模型由多层分层网络组成。训练模型过程中,我们最小化自然语音参数和合成语音参数的代价函数。x = [x1⊤, . . . , xt⊤, . . . , xT⊤]⊤ 看作语言学特征序列,y = [y1⊤, . . . , yt⊤, . . . , yT⊤]⊤看作自然语音参数序列,yˆ = [yˆ1⊤, . . . , yˆt⊤, . . . , yˆT⊤]⊤看作生成语音参数序列,t 代表帧的索引,T代表总帧数。xt 和 yt = [yt (1) , . . . , yt (D)]⊤ 是语言学参数向量, 代表帧数t 时 D-dimensional 的语音参数向量。
表达式可能看不清:

最后y的维度:T x D。T表示帧数,D表示每一帧的维度。
2>、声学模型训练:
DNN预测来自于x的自然静态-动态语音特征序列 ,被训练来最小化定义的训练标准。
是 第t 帧时的自然静态-动态语音特征。给出一个预测序列
,以最常用的均方误差MSE(mean squared error),
来定义误差:
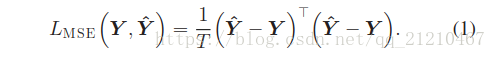
模型的参数集合(比如:DNN的权重weight和偏执bias)会根据
的梯度
来反向传播并更新。为了考虑静态 - 动态约束,提出了最小生成误差(MGE)训练算法[8],在MGE的训练中,损失函数
定义为自然语音参数和生成语音参数之间的均方误差,如下:
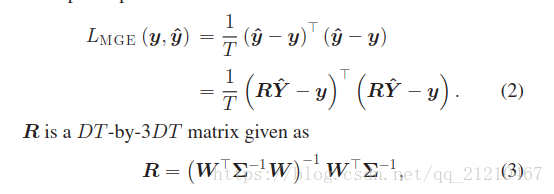
W是一个3DT*DT的矩阵用来计算动态特征, 是一个3DT*3DT的协方差矩阵。
是一个3D*3D的在第 t 帧的协方差矩阵。Σ需要使用训练数据单独估计。这里定义语音的参数预测为
,
是声学模型参数并且有生成误差的梯度
反向传递来更新。如[8]中描述的,梯度包括
以
来表示。
音素持续时间(Phoneme duration):在没有动态特征计算的情况下,以相同方式预测音素持续时间。
是自然音素持续时间序列,
是用持续时间模型描述的DNNs结构生成的持续时间序列。p是音素的索引,P是音素的总数,模型的参数更新使得
取到最小值。
B、DNN-Based VC
用于VC的基于DNN的声学模型将输入语音特征转换为期望的输出语音特征。 在训练中,动态时间规整算法用于在时间上对齐源和目标语音特征。 使用对齐的特征,x和y,训练声学模型以最小化LMGE(y,y^)损失,与基于DNN的TTS相同。
3、结合GAN并且基于DNN的SPSS
A、生成对抗网络GANs
GAN是一个学习深度生成模型的框架,它同时训练两个DNN:生成器和判别器,
是一个判别器的模型参数集合,通过从鉴别器的输出中获取sigmoid函数获得的值:1/(1 + exp(−D(y))),表示输入y是自然数据的后验概率。判别器训练使得来源于自然语言的后验概率趋近1而来自于生成语音的概率为0;同时,生成器训练来欺骗判别器:即使得判别器将来源于生成数据的后验概率判断为1.
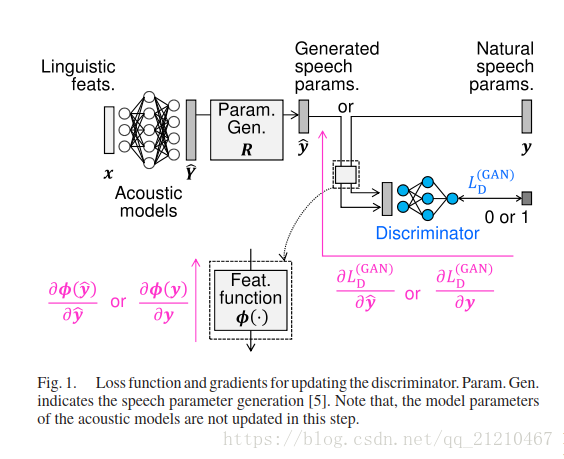
在GAN的训练中,两个DNNs的更新是使用GSD随机梯度下降迭代进行的。首先使用自然数据y和生成数据,计算判别器损失函数
定义如下:
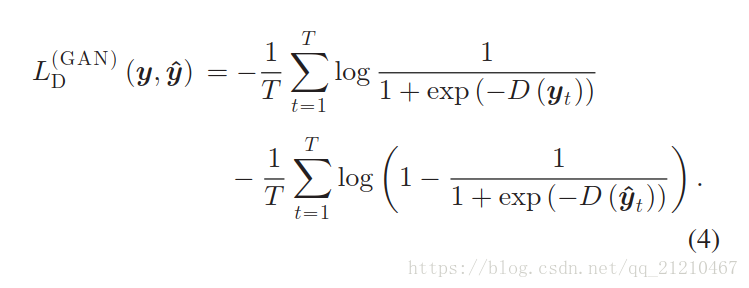
根据上式的随机梯度来更新,图一说明了判别器损失函数的计算流程。在判别器更新之后,我们计算对抗网络的生成器损失函数:
,用来欺骗判别器。公式如下:
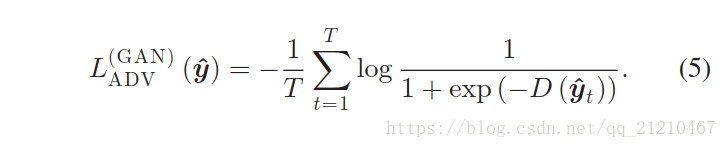
同样,参数的更新是由随机梯度下降确定。在Goodfellow的论文里面展示了对抗网络的最小化Jensen-Shannon(JS)散度的方法,最小化自然数据和真实数据之间的分布。
B、结合GAN的声学模型的训练
这一节介绍一种结合GAN来训练SPSS的新颖方法。对于所提出的算法,训练声学模型用来欺骗区分自然和生成的语音参数的鉴别器。
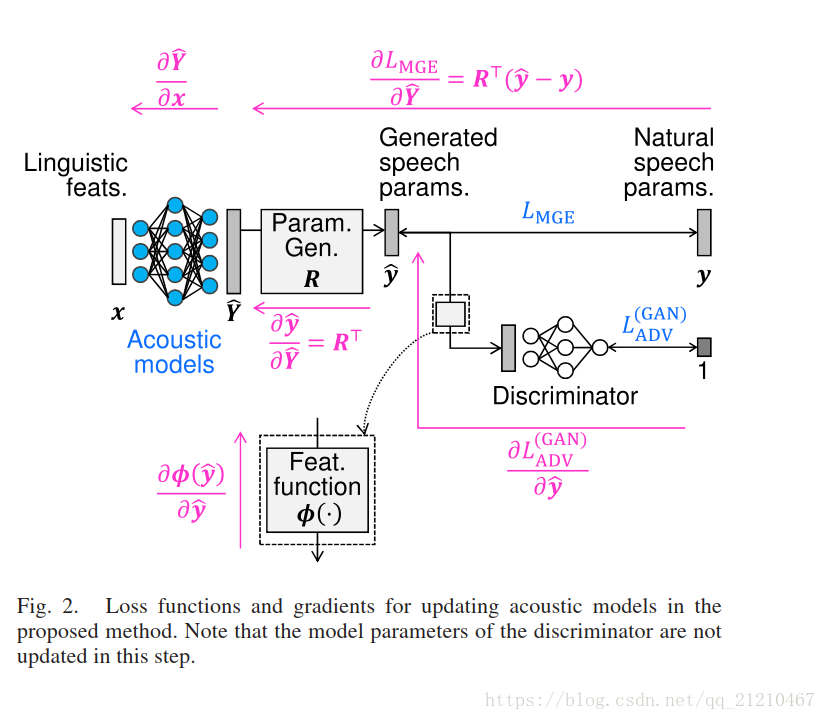
语音合成的损失函数有如下定义:
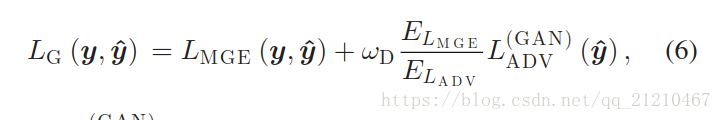
使得判别器将生成的语音参数看作自然语音的参数,以及最小化自然语音和生成语音参数之间的分布差异。因此,我们提出的损失函数不仅仅最小化生成误差而且是的生成语音的参数和自然语音的参数更加接近。
和
分别表示最小生成误差
和生成器的对抗损失函数
,两者的比率
/
是两个损失函数之间的尺度归一化项,超参数WD控制着第二项的权重。当WD=0成立的时候损失函数与传统的MGE训练是一样的,WD=1时,两个损失函数有相等的权重参数。声学模型参数
由
的随机梯度来更新。图二指出了我们提出的损失函数的计算过程。在我们的算法中,声学模型和判别器是迭代优化的,就像展示的算法1一样。当一个模块正在更新时,另一个模块的模型参数是固定的。也就是说,虽然鉴别器包括在前向路径中以计算
中的
,但是声学模型的反向传播不会更新
。
我们的方法中使用的鉴别器可以被视为基于DNN的反欺骗(语音欺骗检测)[18],[19].能够鉴别自然语音和合成的语音。从这个角度来看,可以在语音参数预测和鉴别器之间插入特征函数φ(·),如图1和2所示.该函数计算反欺骗中比可以直接使用语音参数本身更具有可区分性的特征。

换句话说,可以用和
来代替公式(4)和公式(5)中的 y 和
.在训练声学模型时,梯度用于反向传递。比如:
时,梯度
用啦ijinxing反向传递。
C、应用于F0和持续时间生成
我们的算法简单的应用于频谱参数的生成和为了TTS和VC的转换。这里,本文将算法扩展到由F0和持续时间生成的TTS。对于F0生成,由于实现简单,我们使用连续的(continuous )F0序列[20]而不是F0序列。判别式的输入是每一帧的频谱参数和连续F0值的结合的向量
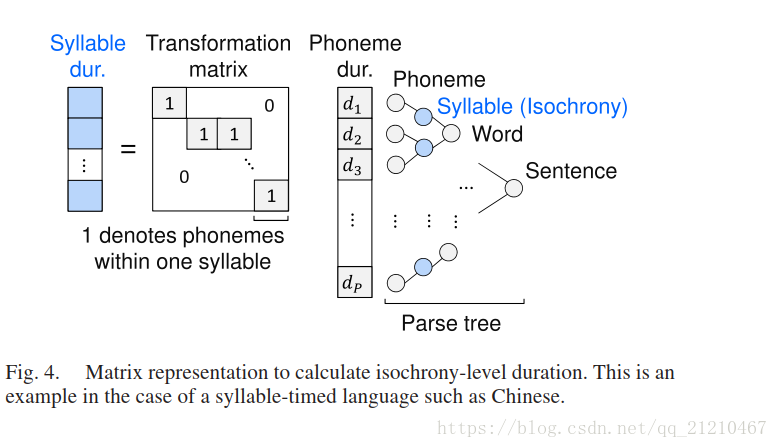
对于持续时间的生成,尽管我们可以直接使用我们的算法在音素的持续时间上。不保证自然分布的音素持续时间具有目标语言的自然等时性(例如,日语中的moras)[21]。因此,我们修改我们的算法,以便生成的持续时间自然地分布在依赖于语言的等时级别。图3展示了这种结构。对于具有mora等时的日语,每个音节持续时间是根据相应的音素持续时间计算的。
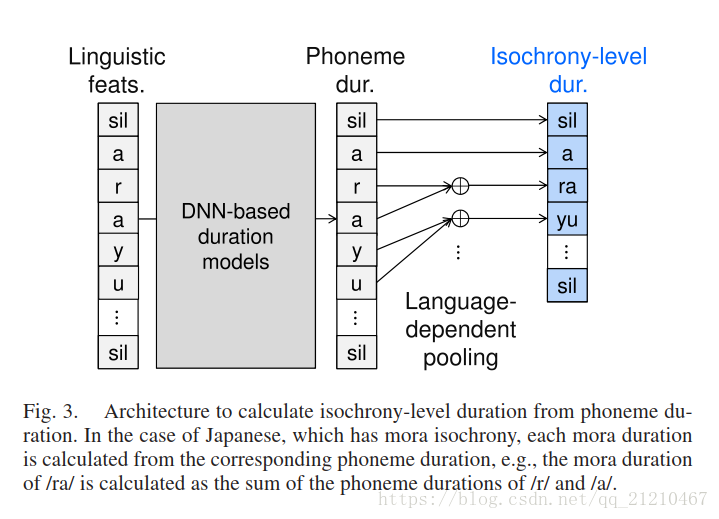
鉴别器通过使用等时级持续时间来最小化交叉熵函数,而生成器使用等时级持续时间来最小化自然和生成的音素持续时间之间的MSE和对抗性损失的加权和。。由于等时级持续时间的计算表示为图4中所示的矩阵乘法,因此使用变换矩阵的转置来完成反向传播。
D、将GANs应用到提出的算法
GAN框架用作自然语音参数和生成的语音参数之间的散度最小化的(工具)。如第三节B中描述的那样,原始的GAN[17]最小化了JS散度差异的近似。从散度最小化的角度来看,我们进一步引入了额外的GAN,最大限度地减少了其他散度(divergences):f-GAN [22], Wasserstein GAN(W-GAN) [23]and least squares GAN (LS-GAN) [24](最小二乘法GAN). f-GAN的divergences与诸如非负矩阵分解之类的语音处理密切相关[25],[26],并且W-GAN和LS-GAN在图像处理中的有效性是已知的。判别器损失和对抗损失
下面会介绍,可以分别用来替代(4)和(5)。
1、f-GAN[22]:
f-GAN是一个包含了原始GAN的统一框架。自然数据和生成数据的分布之间的差异被定义为f-divergence[27],它是一大类不同的divergence,包括Kullback-Leibler(KL)和JS divergence。f-divergence 定义如下:
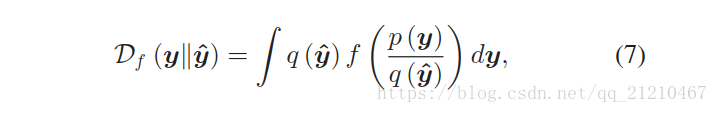
p(·)和q(·) 分别是 和
的绝对连续密度函数。
是满足
的凸函数。尽管可以使用各种f(·)来获得流行的divergences,但我们采用了与语音处理相关的选择。
KL-GAN:定义并给出KLdivergence的公式如下:
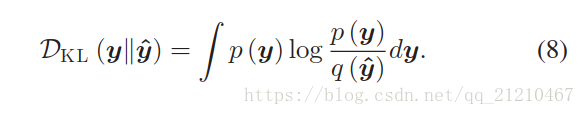
判别器损失有如下定义:
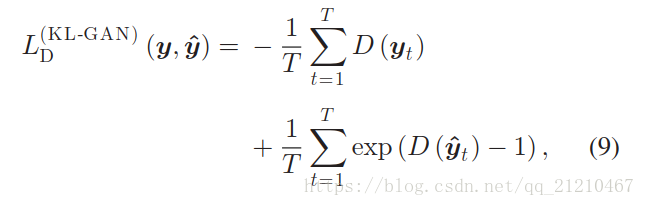
对抗损失定义如下:
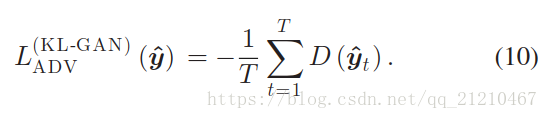
后面介绍了反向KL-GAN:总的损失函数和分别的损失函数见下。

JS-GAN的损失函数以及判别器和生成器的损失函数:

注意,由原始GAN最小化的近似JS散度是[17]。
2、Wasserstein GAN (W-GAN) [23]:
为了使原始怒稳定的GAN的训练变得更加 稳定,Arjovskyet al. [23]提出了W-GAN,使得搬土距离(the Earth-
Mover’s distance (Wasserstein-1).)最小化。the Earth-Mover’s distance定义为;

是联合概率分布,y和
是边缘分布。在Kantorovich-Rubinstein二元性的基础上[28]的基础上,判别器损失
定义如下:
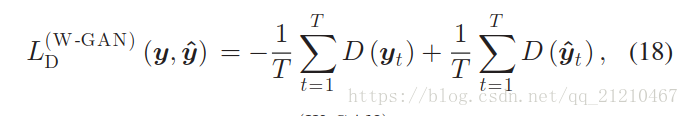
对抗损失是定义如下:
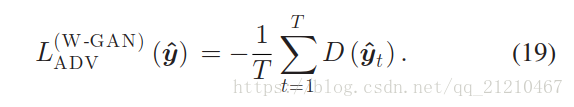
我们假设鉴别器是K-Lipschitz函数。 即,在更新鉴别器之后,我们将其权重参数钳制到固定的间隔,例如[-0.01,0.01]。
3、最小二乘GAN(Least Squares GAN (LS-GAN)) [24]:
为了避免原始GANs中使用sigmoid交叉熵带来的梯度消失的问题,Mao et al. [24]提出LS-GAN,公式化了最小化均方误差的目标函数。判别器损失函数有如下定义:
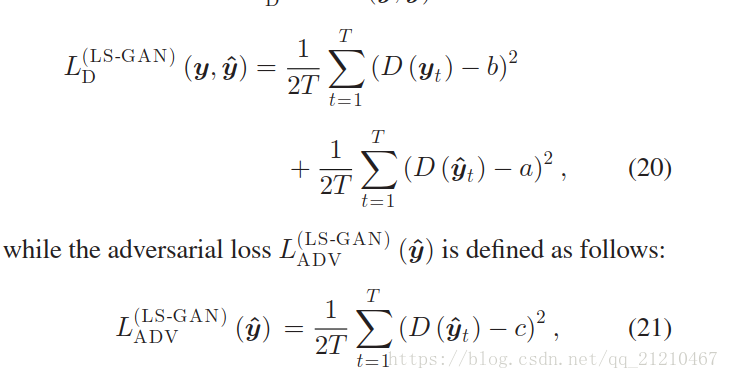
其中a,b和c分别表示使鉴别器识别生成的数据为生成的,自然数据为自然的,生成数据为自然数据的标签。当他们满足条件和
时,要最小化的divergence是
和
之间的Pearson
偏差。因为我们发现这些条件会降低合成语音的质量,我们使用了[24,eq.(9)]。中提出的替代条件。 即a = 0,b = 1,c = 1。
E、Discussions、
后面有时间在翻译了。太长了的说……