会议:2020 NIPS
单位:韩国KAKAO
作者:Jungil Kong, Jaehyeon Kim
文章主页
开源代码
文章目录
abstract
motivation:在推理时间 & 生成高保真音质方面均作出改进
- 观点:modeling periodic patterns of an audio is crucial
- 结果:22.05k的单人音频生成质量和录制语音接近;优点全CNN网络,前向推理速度非常快
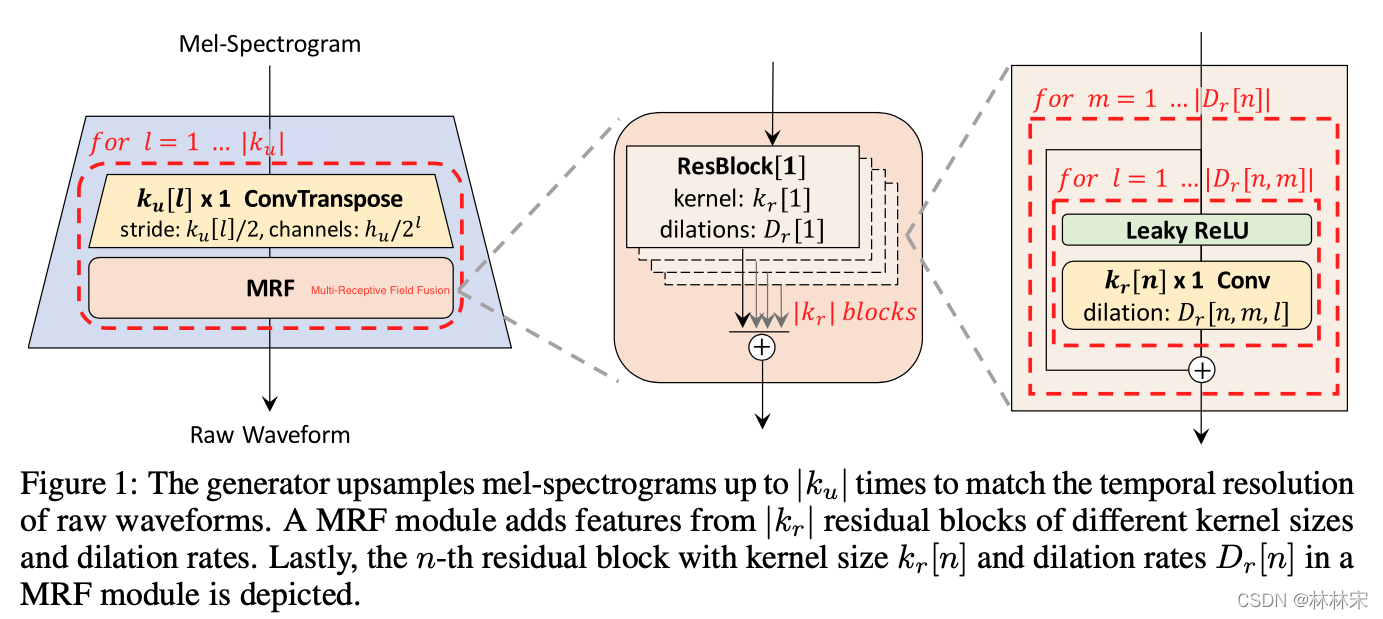
HiFi-GAN
包括一个生成器和两个判别器(multi-scale & multi-period),
生成器结构
MSD: multi-scale discriminator
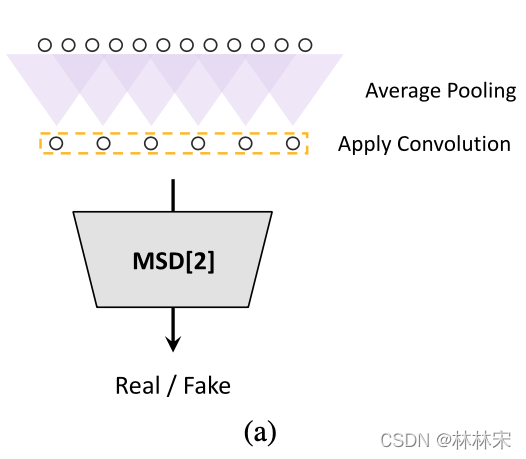
- 三个子判别器:对连续的语音采样点进行建模,分别建模原始语音,✖️2 average-pooled audio,✖️4 average-pooled audio
MPD:multi-period discriminator
- motivation:语音由不同的周期信号组成,重建语音数据需要对不同的周期模式进行建模。
- 对不连续的采样点进行建模,设置素数【2,3,5,7,11】为不同的period,按照period将音频采样点reshape为二维信号,然后用卷积单独处理周期重采样后的信号。
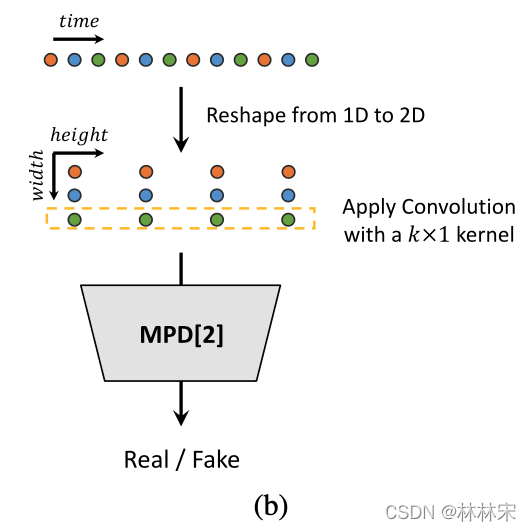

- 如上图所示:可以看成大周期sin signal+小周期sin signal,不同的采样间隔建模到不同周期的信号。
目标函数

- Feature Matching Loss:衡量判别器对于真实样本和生成样本预测的结果偏差
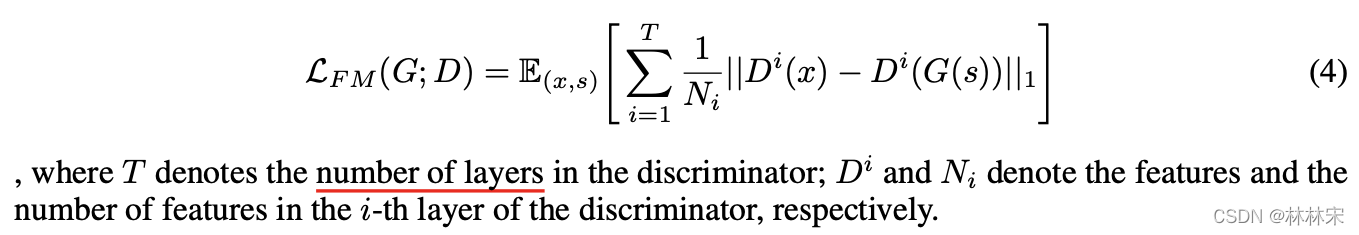
experiments
- 对比1:LJSpeech的效果,baseline选择官方开源的WaveNet,WaveGlow,MelGAN
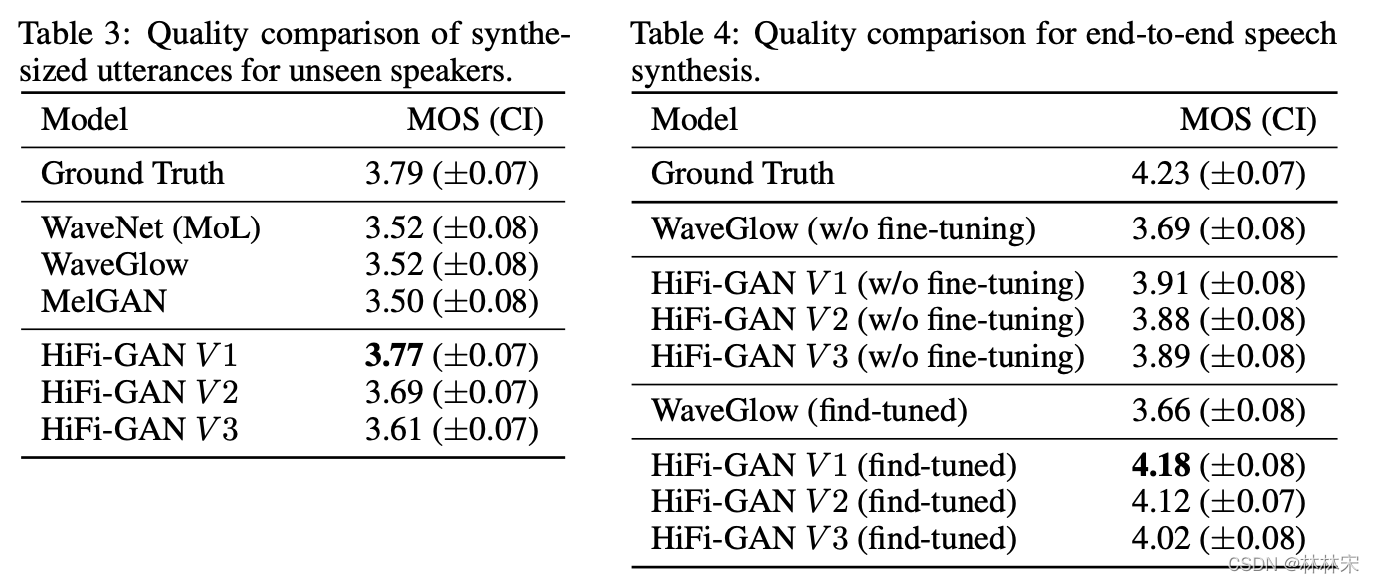
- 对于unseen speaker的泛化效果:VCTK数据集,9个人作为unseen speaker,剩下的用于训练WaveNet,WaveGlow,MelGAN, hifigan
- 为了对比合成质量和合成速度,分别设置三组参数V1,V2,V3,参数量依次越来越小;

ablation study
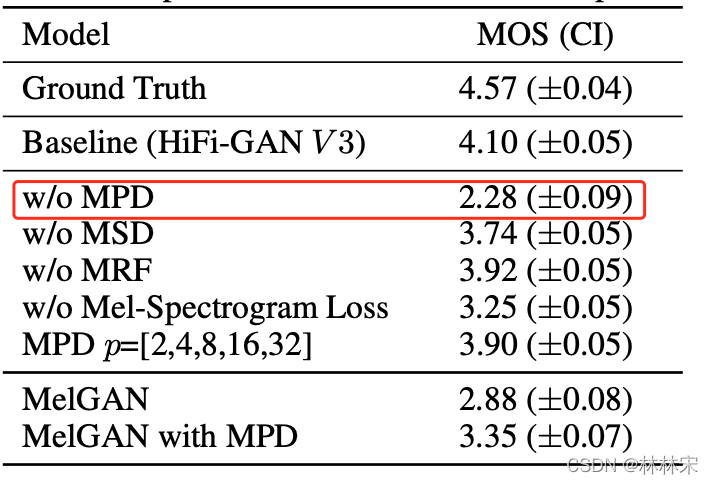
- MPD模块对结果的改善最显著
unseen speaker的泛化