会议:ICASSP 2019
论文:VOICE TRIGGER DETECTION FROM LVCSR HYPOTHESIS LATTICES USING
BIDIRECTIONAL LATTICE RECURRENT NEURAL NETWORKS
作者:Woojay Jeon ; Leo Liu ; Henry Mason
ABSTRACT
我们提出了一种通过神经网络对服务器端大型词汇连续语音识别器(LVCSR)的假设格进行后处理的方法,以减少启用语音的个人助理的错误语音触发。我们首先讨论如何使用已知技术从假设晶格中获取触发短语后验概率的估计值,以执行检测,然后研究以更明确的数据驱动,判别方式处理晶格的统计模型。我们建议为任务使用双向格子递归神经网络(LatticeRNN),并表明与使用1个最佳结果或后验方法相比,它可以显着提高检测精度。
CONCLUSION AND FUTURE WORK
我们提出了一种基于双向格网递归神经网络的基于LVCSR假设格的语音触发短语检测的新方法,并表明它可以显着减少数字个人助理中错误触发的发生。
鉴于在这种情况下LVCSR同时用于触发检测和语音识别,未来的工作将研究一种目标函数,该目标函数将识别精度和检测精度最大化,这将更好地适合系统的真实目标。
INTRODUCTION
具有语音功能的个人助手通常可以通过使用触发短语方便地激活。如果使用Apple个人助理Siri,则英语用户可以说“ Hey Siri”来激活助理并单步提出请求,例如“ Hey Siri,库比蒂诺今天的天气如何?”
通常,设备上的检测器[1]决定是否说出触发短语,如果是,则允许音频(包括触发短语)流到基于服务器的大词汇量连续语音识别器(LVCSR)。由于设备上检测器受资源限制,因此其准确性受到限制,并会导致偶尔出现“错误触发”,用户不会说出触发短语,但无论如何设备都会唤醒并给出意外响应。
为了减少误报,可以设想在服务器上运行一个辅助触发短语检测器,它使用比设备上更大的统计模型来更准确地分析音频,并在发现没有触发短语时覆盖设备的触发决策。存在。由于我们使用专门针对检测任务训练的专用声学模型,因此该方法将最佳地提高准确性。但是,由于必须针对每种话语执行此操作,因此,一种更节省资源的方法是使用服务器端LVCSR的输出(无论如何针对每种话语运行)来执行辅助检测。
一种明显的方法是检查LVCSR产生的最高识别结果是否以触发短语开头。但是,LVCSR通常会偏向于在音频开始时识别触发短语,因此,即使该最佳短语不存在,它也会在“最佳”结果中“半透明”该短语。
在过去的许多研究中,LVCSR的输出已被用于关键字发现(或密切相关的关键字搜索)。早期的方法是使用n最佳列表中包含关键字的假设的可能性之和[2]。但是,n个最佳列表是单词假设晶格的有损表示,它是ASR输出的更丰富的表示[3]。因此,随后的工作通过神经网络[6]计算单词后验[4]或归一化的置信度得分[5]或上下文特征,直接作用于假设格。
我们将开始研究如何使用LVCSR假设网格上的已知处理技术来构建辅助语音触发检测器,以计算触发短语的后验概率[4]。但是,此方法受到LVCSR声学模型和语言模型的可靠性的严格限制,这对于经常包含可能是语音或可能不是语音的多样化且不可预测的声音的错误触发的音频可能不够准确。为了积极克服LVCSR的某些错误,我们考虑使用统计模型,该模型可以以区分性的,数据驱动的方式解释假设格。我们建议使用双向版本的“ LatticeRNN” [7] 为此目的,并表明与使用简单的后验概率相比,可以显着提高准确性。
VOICE TRIGGER DETECTION BASED ON LATTICE POSTERIORS
略~
BIDIRECTIONAL LATTICE-RNN FOR VOICE TRIGGER DETECTION
在上一节中,我们讨论了如何根据假设晶格计算语音触发后验概率以执行语音触发检测。这种方法的基本局限性在于它直接暴露于LVCSR的声学和语言模型得分中。如果LVCSR过于偏向于给语音触发短语提供高分,则等式中的后验。(3)会一直很高,并且检测精度会受到影响。系统中唯一可调整的参数是应用于后验的检测阈值,并且一个参数(应用于所有话语)不足以克服LVCSR中的建模错误。
这激励我们建立一个具有更多参数的更通用的统计模型,这些模型可以使用训练示例来学习如何以数据驱动的方式处理假设格。实际上,该模型学习了LVCSR分数中的“错误”,并积极尝试对其进行纠正。在我们提出的方法中,我们采用了格子递归神经网络[7],它可以读取整个假设晶格,而无需我们试探性地将它们转换为有损形式,例如n-最佳列表或单词混淆网络。
3.1. The Bidirectional LatticeRNN
略~
EXPERIMENT
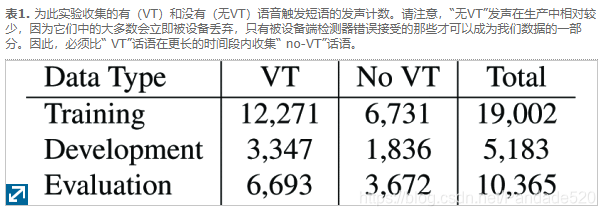
实验中使用了一组带有标签的语音,其中一些以“ Hey Siri”触发短语开始,其余的则没有。表1列出了用于培训,发展和评估的正面和负面例子的数量。
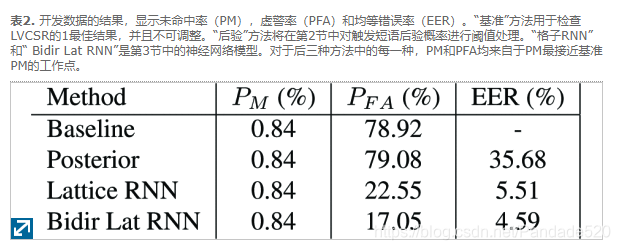
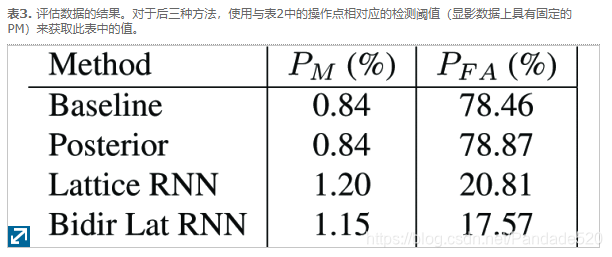
“基准”方法是简单地查看LVCSR的最高识别结果,并检查其是否以“ Hey Siri”开头。如表2和表3所示,未命中的概率(当出现触发词组时无法识别)通常小于1%,但是错误警报的概率(当不出现触发词组时“误认为”触发词组)在这个数据集上大约是79%。请注意,由于没有触发短语的大多数话语会被设备端检测器立即丢弃,因此实际的Siri用户遭受的误报要少得多,只有偶尔的一些跳过检测器才成为我们负面数据的一部分。
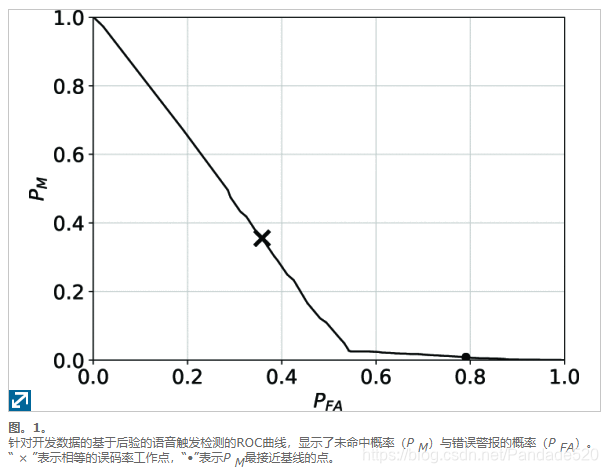
“后验”方法在第2节中进行了描述,其中语音触发后验概率是直接从假设晶格中计算出来的。从图1的ROC曲线中可以明显看出,在某个阈值之上(曲线中存在明显的尖角),语音触发的后验趋于在真实触发和虚假触发之间平均分配,因此很难区分。但是,在转折点以下,大多数输入都是错误触发,因此,在错误警报概率约为55%或更高时,检测器的性能要好得多。对于开发数据中,P FA是当79.08%,P 中号与基线相同(0.84%)。从该工作点获得的阈值应用于评估数据,以获得表3中的值。
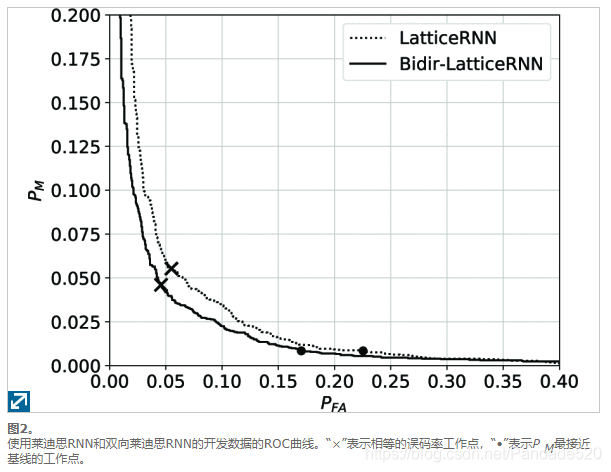
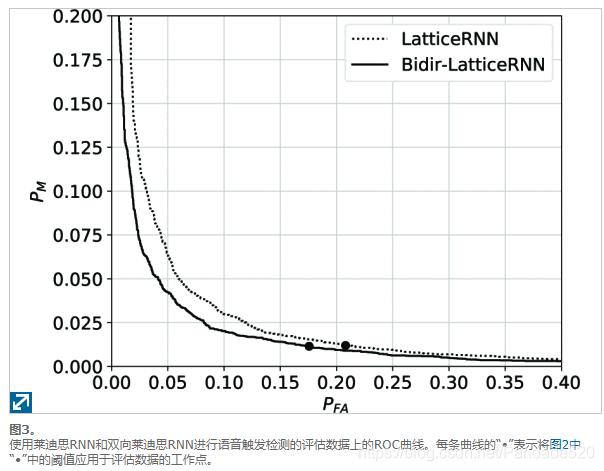
对于晶格RNN,弧特征向量x(e)由19个特征组成:对数声学得分,对数语言模型得分,弧所消耗的语音帧数,指示单词是否为“嘿”的二进制特征,指示单词是否为“ Siri”的二进制特征。 ,以及代表弧词的电话序列的14个特征。可变长度的电话序列被转换为51维二进制手机袋向量,并通过自动编码器缩减为14维。使用70万个单词的发音词典来训练自动编码器。单向晶格RNN具有状态向量的24维,该维被馈送到具有20个隐藏节点的前馈网络,从而形成总共1577个参数。双向晶格RNN在每个状态向量中都有15个维,并与具有15个隐藏节点的前馈网络一起使用,从而产生总共1,531个参数。所有输入均经过均值和方差归一化,并从训练数据中计算出比例和偏差。池化功能等式 (10)和(12)是算术平均值。
与基于基线或基于后验的方法相比,使用晶格神经网络可观察到巨大的准确性增益,而使用双向而不是单向晶格RNN可以观察到更多的准确性。
在运行时计算复杂度方面,所提出的方法为现有的LVCSR添加了最小的延迟,因为1)晶格通常很紧凑;在训练数据上,每个晶格的平均弧数为42.7,而声学特征帧的平均数为406,以及2)晶格RNN小,仅具有约1,500个参数。
为了保持电话序列在每个弧中的顺序,我们还尝试用序列到序列自动编码器中的编码替换电话袋功能,但没有观察到给定数据的准确性提高。
附: