声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
CUHK-EE voice cloning system for ICASSP 2021 M2VoC challenge
本文是香港中文大学在2021.03.09更新的文章,主要做少数据量声音复刻的任务,具体的文章链接
https://arxiv.org/pdf/2103.04699.pdf
1 背景
m2voc挑战官网(http://challenge.ai.iqiyi.com/detail?raceId=5fb2688224954e0b48431fe0)
文语转换(TTS)又称为语音合成,旨在将文本转换成自然语音的一类技术,是智能语音领域的前沿技术,在语音助手、信息播报、有声读物等方面具有重要的应用价值。在深度学习的帮助下,语音合成已实现了效果上的显著提升。端到端语音合成框架和神经声码器的最新进展使得我们能够生成特定领域内非常逼真和自然的语音,几乎可以以假乱真。但是,这种令人惊叹的能力仍然受限于训练集是大量单一说话人且表现力不够丰富数据的的理想情况。对于多说话人和多风格的语音合成,特别是在真实环境录制或是低资源的情况下表现力和鲁棒性仍然不能令人满意。例如,仅拥有每个说话人非常少量的音频样本时,语音的质量和目标说话人的相似度、表现力和鲁棒性仍然不能令人满意。即便是现有公开的音色克隆方案,对集外数据的音色复刻缺乏鲁棒性。我们称这种有挑战性的任务为多说话人和多风格的语音克隆任务(M2VoC)。近年来,迁移学习、风格迁移,说话人编码和因素解耦方面的最新进展,为低资源语音克隆的提供了潜在的解决方案。作为2021年声学、语音和信号处理国际会议(ICASSP2021)信号处理挑战旗舰任务之一,M2VoC挑战赛旨在提供一个通用的数据集以及一个公平的测试平台,对语音克隆任务进行研究。我们非常鼓励学术界和工业界的研究人员加入挑战,一起进行深入的讨论和合作。
我们设置了以下两个任务。
赛道1:少样本赛道
主办方将分别提供两个和三个说话人用于音色克隆的校验和最终测试。每个说话人有不同的说话风格和100个可用的音色克隆样例。主办方还将为参赛者提供一个多说话人语料库,可用来训练基础模型。目标说话人的测试集是一系列句子和短段落,用于针对目标说话人的文本到语音的生成。
子赛道1A:语音合成系统的搭建仅限于使用竞赛组织者提供的数据,禁止使用除此之外的数据。
子赛道1B:除了竞赛组织者提供的数据之外,可以使用任何公开数据搭建语音合成系统。但是在提交的系统描述中,应当明确说明使用的公开数据来源。
赛道2:极少样本赛道
主办方将分别提供两个和三个说话人用于音色克隆的校验和最终测试。每个说话人有不同的说话风格和5个可用的音色克隆样例。主办方还将为参赛者提供一个多说话人语料库,可用来训练基础模型。目标说话人的测试集是一系列句子和短段落,用于针对目标说话人的文本到语音的生成。
子赛道2A:语音合成系统的搭建仅限于使用竞赛组织者提供的数据,禁止使用除此之外的数据。
子赛道2B:除了竞赛组织者提供的数据之外,可以使用任何公开数据搭建语音合成系统。但是在提交的系统描述中,应当明确说明使用的公开数据来源。
2 详细设计
本文是参加track 1的系统,即使用少数据量来进行复刻,使用的系统包括:tacotron2 +durIAN结合的声学模型 + hifi-gan声码器。具体流程分为:基础模型训练->目标人微调->推理。具体如图1所示,整个系统都很简单,不做额外介绍。
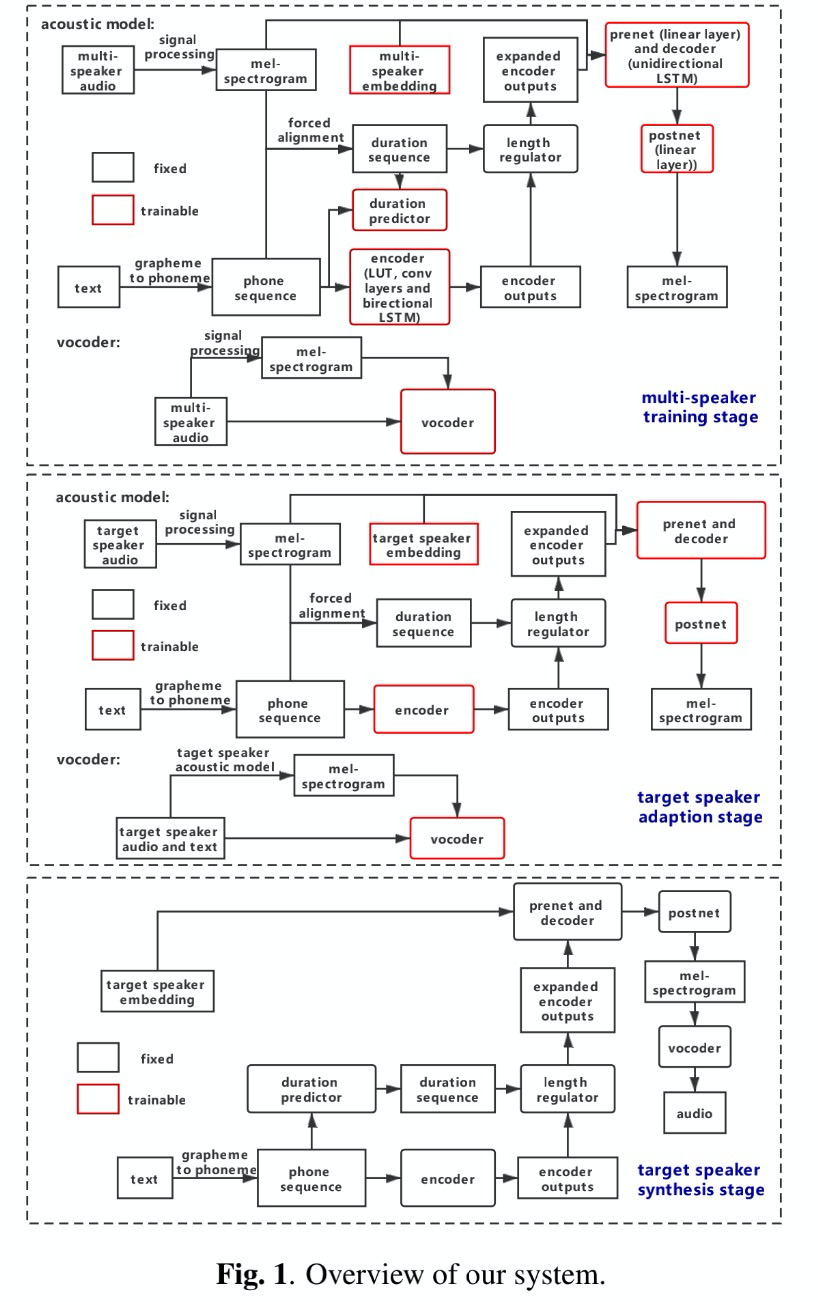
3 结果
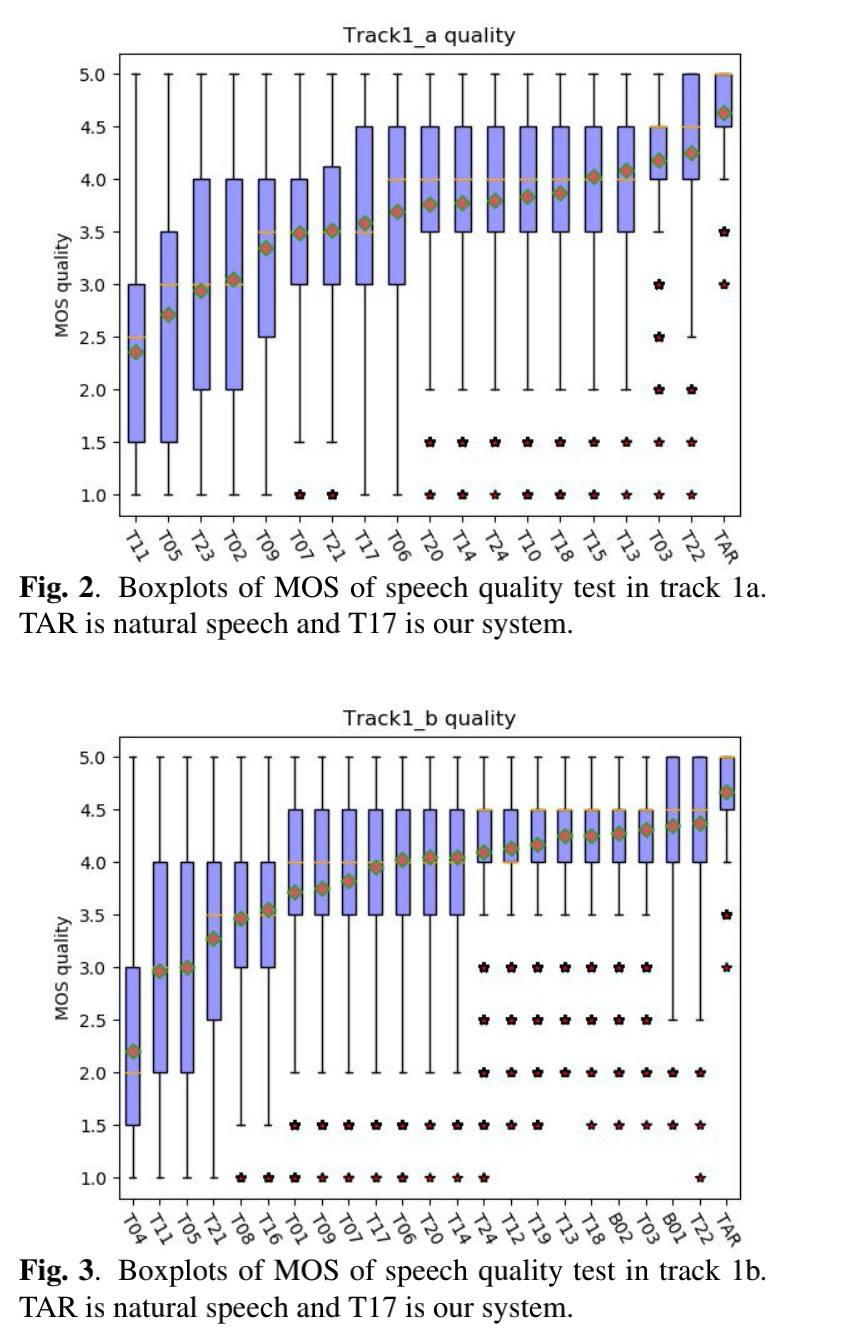
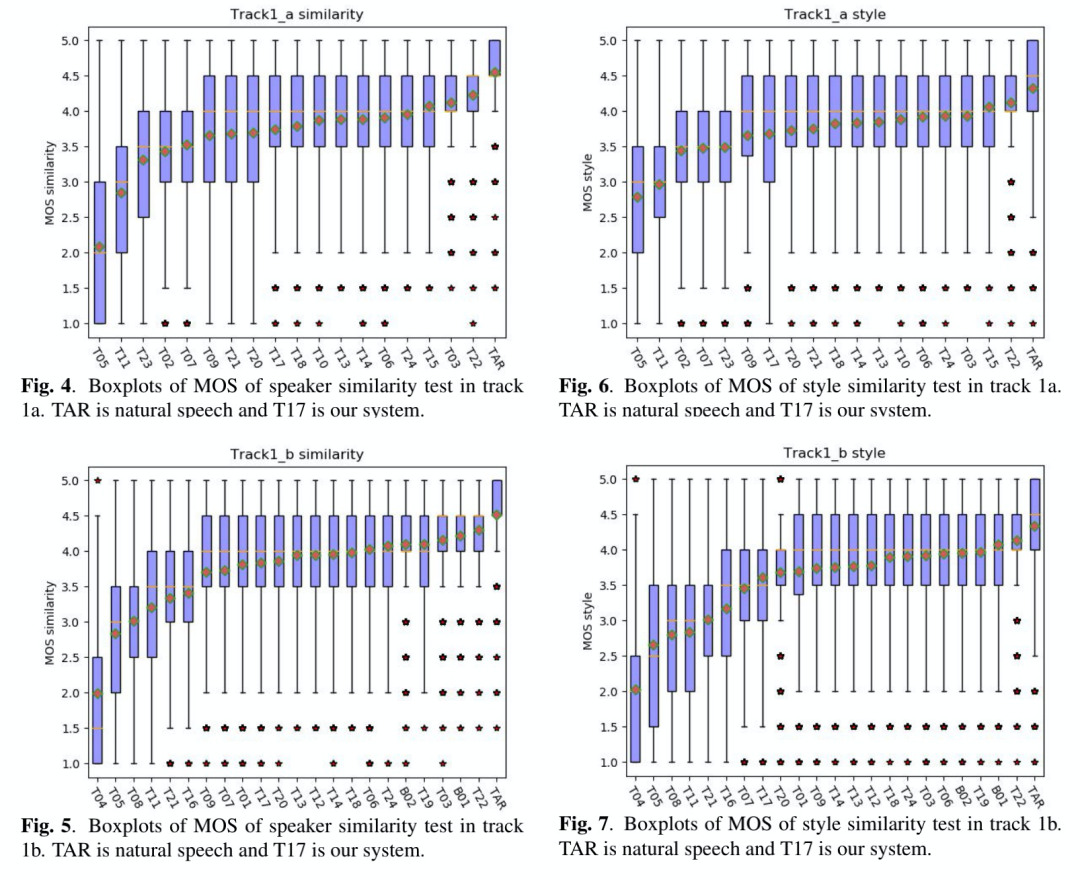
在track1a和b的MOS和SMOS的结果如图2~图7,t17为本文结果,总体排名中下。
4 总结
本文是参加m2voc的系统,系统和流程都不难理解,结果中下。