声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Investigating on Incorporating Pretrained and Learnable Speaker Representations for Multi-Speaker Multi-Style Text-to-Speech
本文是国立台湾大学李宏毅团队在2021.03.06更新的文章,该工作主要是使用pretrained and learnable speaker representation来优化多发音人多风格的语音合成系统,该系统在ICASSP 2021 M2VoC的 trick2 one-shot任务获得第二名。具体的文章链接
https://arxiv.org/pdf/2103.04088.pdf
1 研究背景
现有的语音合成系统可以很好的合成近似人类的语音,但多发音人的模型合成的语音往往没有单发音人单模型的好,好像语音风格被中和了。为了优化多发音人多风格模型,本文联合使用预训练的speaker representation和TTS学习的speaker representation ,使多发音人模型合成的语音相似性更高。
2 详细设计
预训练的PSR(pretrained speaker representation)模型包括:D-vector,X-vector和VC representation。 联合训练的speaker representation包括 looked-up embeddding 和global style token。本文主要组合以上信息来优化多发音人模型。本系统的训练和推理流程如图1所示。

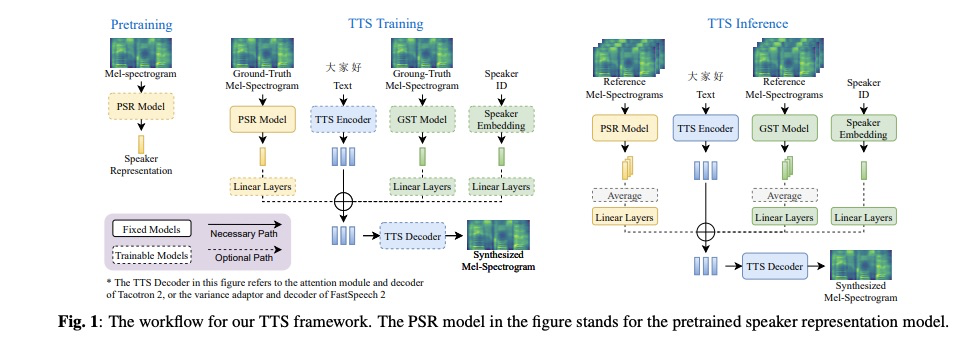
3 实验
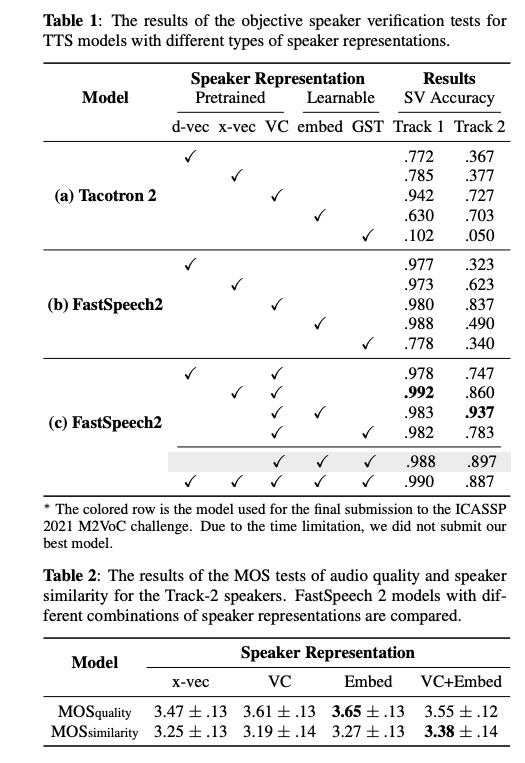
本文使用数据为ICASSP 2021 M2VoC数据,其中track 1任务为few-shots,track 2任务为one-shot,系统使用taoctron2和fastspeech2。table1显示使用每种representation的系统,其合成的语音通过speaker verfication后的结果,由此可知使用VC的representation效果最好。在table 2 展示track 2的MOS测试,VC+looked table效果最好。图2展示了三种pretrained representation。图3 展示了在ICASSP 2021 M2VoC的 track2 的排名,19个队伍前几个队伍,track 2A排第2。
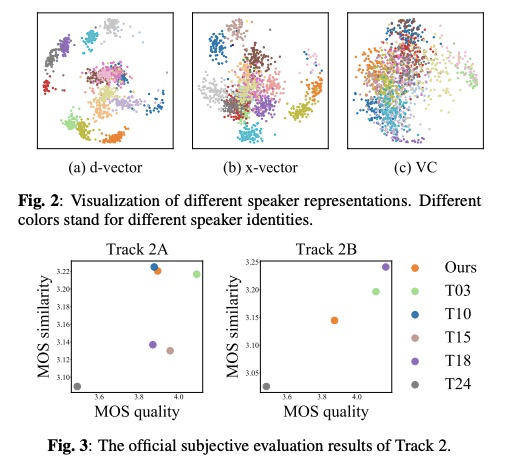
4 总结
为了优化多发音人多风格模型,本文联合使用预训练的speaker representation和TTS学习的speaker representation ,使多发音人模型合成的语音相似性更高。该系统在ICASSP 2021 M2VoC的 trick2 one-shot任务获得第二名。