本次分享华南理工大学、优必选研究院等合作在ICASSP2023会议发表的论文《DST: Deformable Speech Transformer for Emotion Recognition》。该论文提出一个可变形的Transformer结构来对语音情感信号进行建模,能够自适应地发现并关注到语音信号中有价值的细粒度情感信息。
论文地址:https://arxiv.org/abs/2302.13729
代码仓库:https://github.com/HappyColor/DST
0 Abstract
得益于多头自注意机制,Transformer在语音情感识别(Speech Emotion Recognition, SER)领域取得了令人瞩目的成果。与原始的全局注意机制相比,基于局部窗口的注意机制在学习细粒度特征方面更加有效,同时可以极大降低模型的冗余度。然而,情感信息是以多粒度的方式存在的,预先设定的固定窗口会严重降低模型的灵活性。此外,人们难以得到最优的窗口设置。针对上述问题,本文提出一个可变形的Transformer结构来对语音情感信号进行建模,记作DST(Deformable Speech Transformer)。DST可以通过一个轻量的决策网络,根据输入语音的特性动态决定注意机制中的窗口大小。同时,我们引入一个与输入语音信号相关的偏移量来调整注意力窗口的位置,使DST能够自适应地发现并关注到语音信号中有价值的情感信息。我们在IEMOCAP和MELD数据库上进行的大量实验,证明了DST的优越性。
1 Introduction
由于情感是区分人类和机器最基本的特征之一且语音是日常交流中最基本的工具,因此,通过语音信号分析人类的情感状态是研究界所重点关注的研究方向。由于深度学习的快速发展,许多模型已被提出并在语音情感识别方向取得不错的效果。其中,卷积神经网络、循环神经网络及其变体已被广泛研究和应用在实际生活中。
Transformer是近年来广受关注的新架构,并在深度学习领域大放异彩。与以往的模型不同,Transformer采用图1(a)中的全局注意机制学习输入信号的全局表征。尽管Transformer在SER中的有效性已经得到证实,但在使用Transformer进行情感分析时,仍有几个关键点需要特别注意:1)情感信息是多粒度的,这意味着除了语言信号的全局表征,语音中的细节信息也很重要。语言的局部特征,如清晰度和延音,也与情感状态高度相关。2)全局注意机制模式固定,缺乏多样性,不足以捕捉多粒度的情感特征。3)全局注意机制的计算量大,计算冗余,应用时对硬件的要求高。
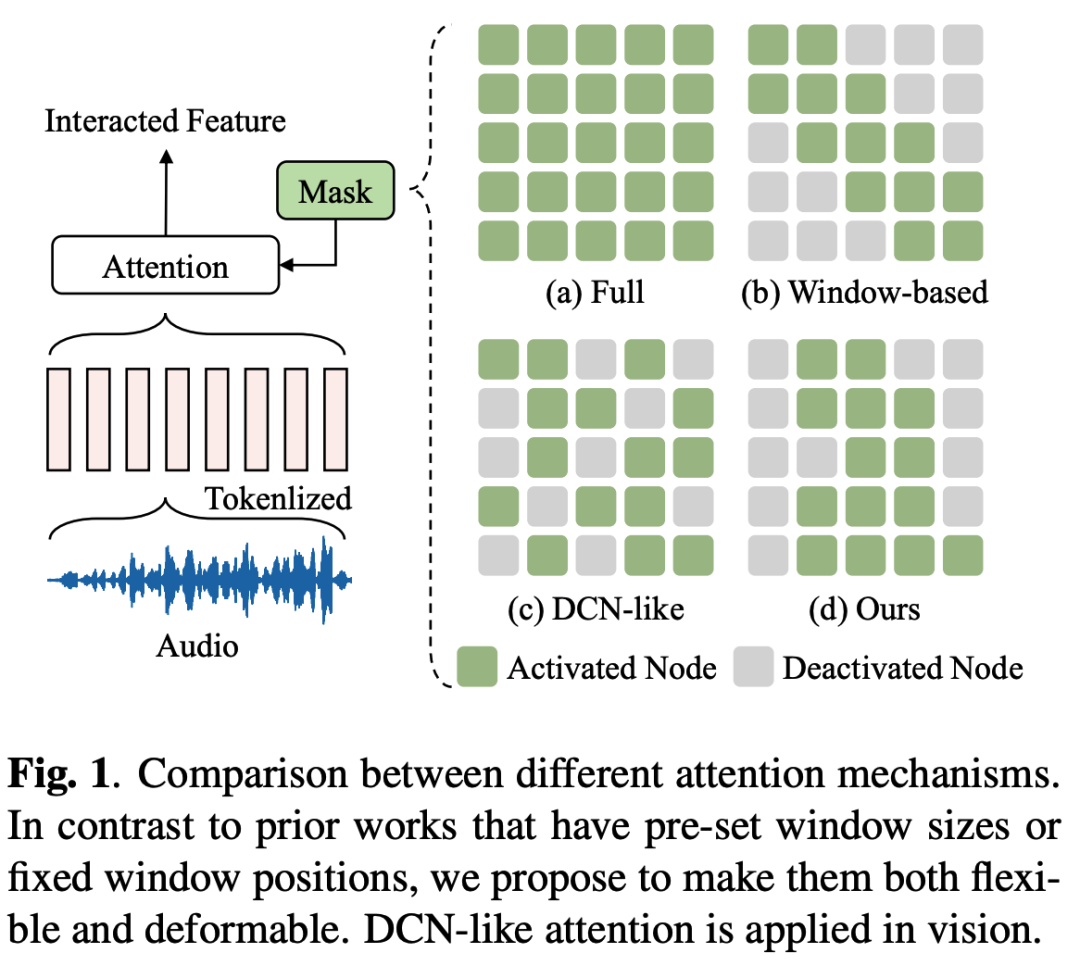
改进Transformer的一个主流做法是将全局注意机制替换为基于局部窗口的注意机制。如图1(b)所示,基于局部窗口的注意机制将注意力范围限制在一个固定的局部窗口。窗口的大小通常被设定为一个较小的值,迫使Transformer学习细粒度的特征。然而,固定的窗口严重降低了模型的灵活性。不仅如此,它还削弱了模型的全局学习能力。通常此做法需要对窗口的设置进行大量的人工调整才能确保模型获得最佳的性能。
为了解决上述问题,本文为语言情感识别任务提出一个可变形的Transformer架构,称为DST。我们赋予Transformer可变形的能力。在DST中,注意力窗口的大小由一个轻量的决策网络学习而来,无需预先设定窗口的大小。另外,注意力窗口的位置可以通过学习而来的偏移量进行移动。DST的这些性质遵循语言情感信息的本质,同时极大地提高了模型的灵活性。此外,与可变形卷积网络(Deformable Convolutional Network,DCN)和在视觉领域中使用的类DCN注意力(图1(c))不同,DST对连续的tokens进行建模,使得DST更加遵循语音信号的连续性(图1(d))。在实验部分,我们将对不同的注意力机制进行可视化分析,以便直观地理解各种注意力机制之间的区别。
2 Methodology
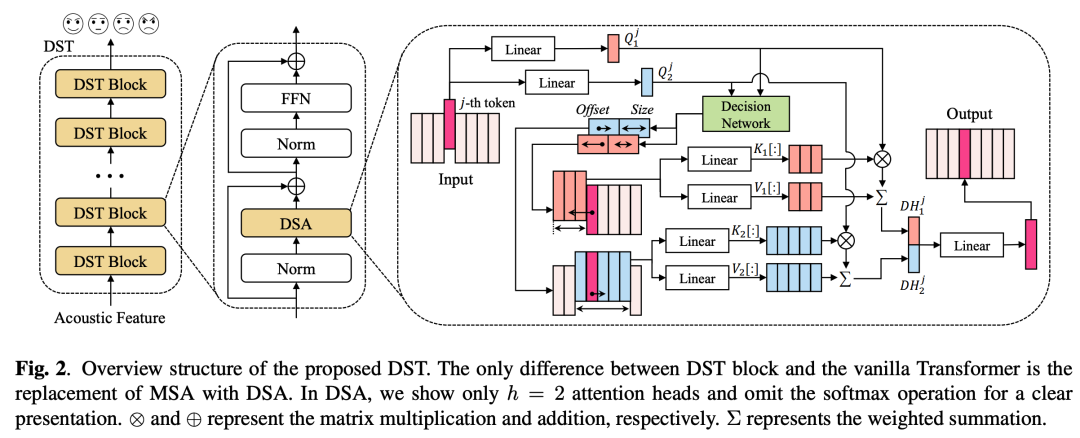
如图2所示,我们提出的DST由多个DST blocks堆叠组成。其中,每个DST block主要由可变形的注意模块(Deformable Speech Attention, DSA)和前馈网络(Feed-Forward Network, FFN)组成。配备了DSA模块后,我们的DST能够根据输入的语音信号自适应地决定注意窗口的大小和位置,这极大地提高了模型的灵活性,并能够有效地学习多粒度的情感表征。

2.1 Revisiting Transformer
原始Transformer的核心是多头自注意模块(Multi-Head Self-Attention,MSA),它使得Transformer在其他深度神经网络中脱颖而出。具体来说,MSA机制可以写成:
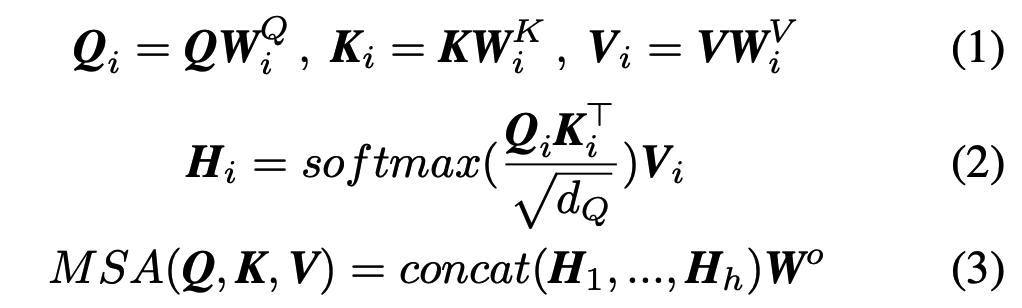
其中,Q,K,V分别是query,key,value矩阵;dQ是一个缩放因子,h代表注意力头的数量;WQi,WKi,WVi,Wo是可学习的参数矩阵。
2.2 Deformable Speech Transformer
2.2.1 Deformable Speech Attention
可变形的注意机制(DSA)是DST的核心。与先前的注意机制不同,DSA能够通过简单的决策网络改变窗口的大小并调整窗口的位置。设Qi中的第j个token为Qji,其中i属于[i,h]。决策网络首先根据Qji产生窗口的大小sij和偏移量oij:
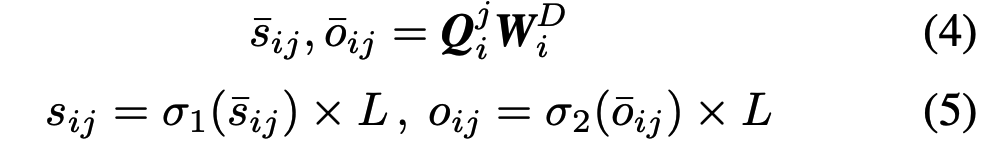
给定当前位置索引j和偏移量oij,既可以得到关键片段Aij的中心锚点。结合预测的窗口大小sij,可以得出第i个注意力头中第j个query token的注意力窗口左边界Lij和右边界Rij。计算方法如下:
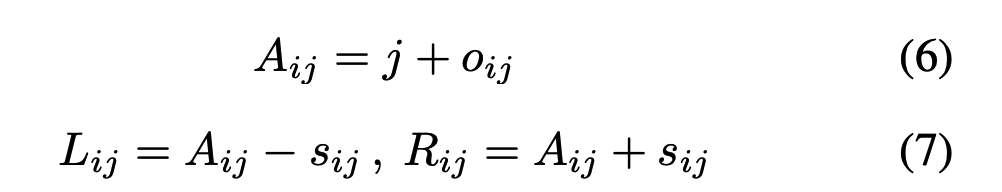
最后,每个query token通过所提出的DSA机制分别在其变形后的注意力窗口中计算注意力输出。DSA的计算公式如下:

2.2.2 End-to-End Training
为了便于阅读,我们将省略符号的下标。在实践中,决策网络的输出窗口大小s和偏移量o是小数,导致注意力边界L和R也是小数。然而,在公式(8)中,索引操作K[L:R]和V[L:R]要求L和R均为整数。一个简单的解决方法是将L和R四舍五入为整数。然而,上述舍入操作是不可微的,将导致决策网络无法通过反向传播算法进行优化。为了以可微的方式将决策网络添加到计算图中,我们利用预测边界(L和R)与真实边界之间的距离,以及中心tokens与中心锚点(A)之间的距离,为被DSA选中的关键tokens生成权重。具体而言,只有当预测的边界接近真实边界时,第L和R个tokens才会被分配较大的权重。两个中心tokens的权重相互影响,锚点靠近哪一侧,则哪一侧的权重更大。需要注意的是,我们期望中心锚点即是重要片段的中心,因此中心tokens的权重应大于1以增强中心tokens的作用。权重的计算方法如下所示:
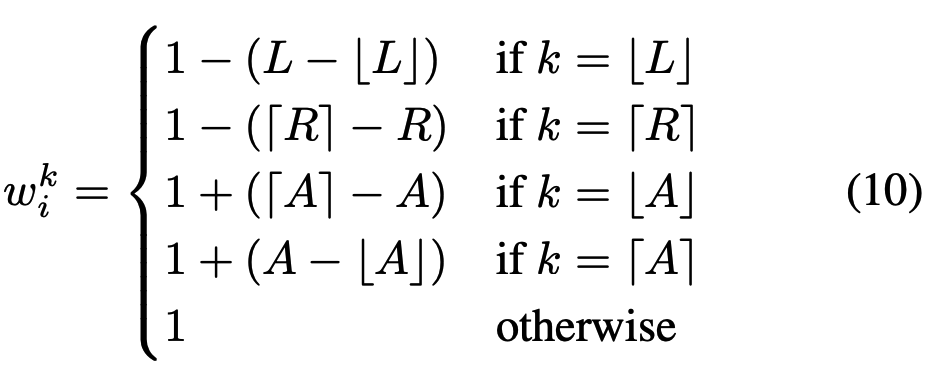
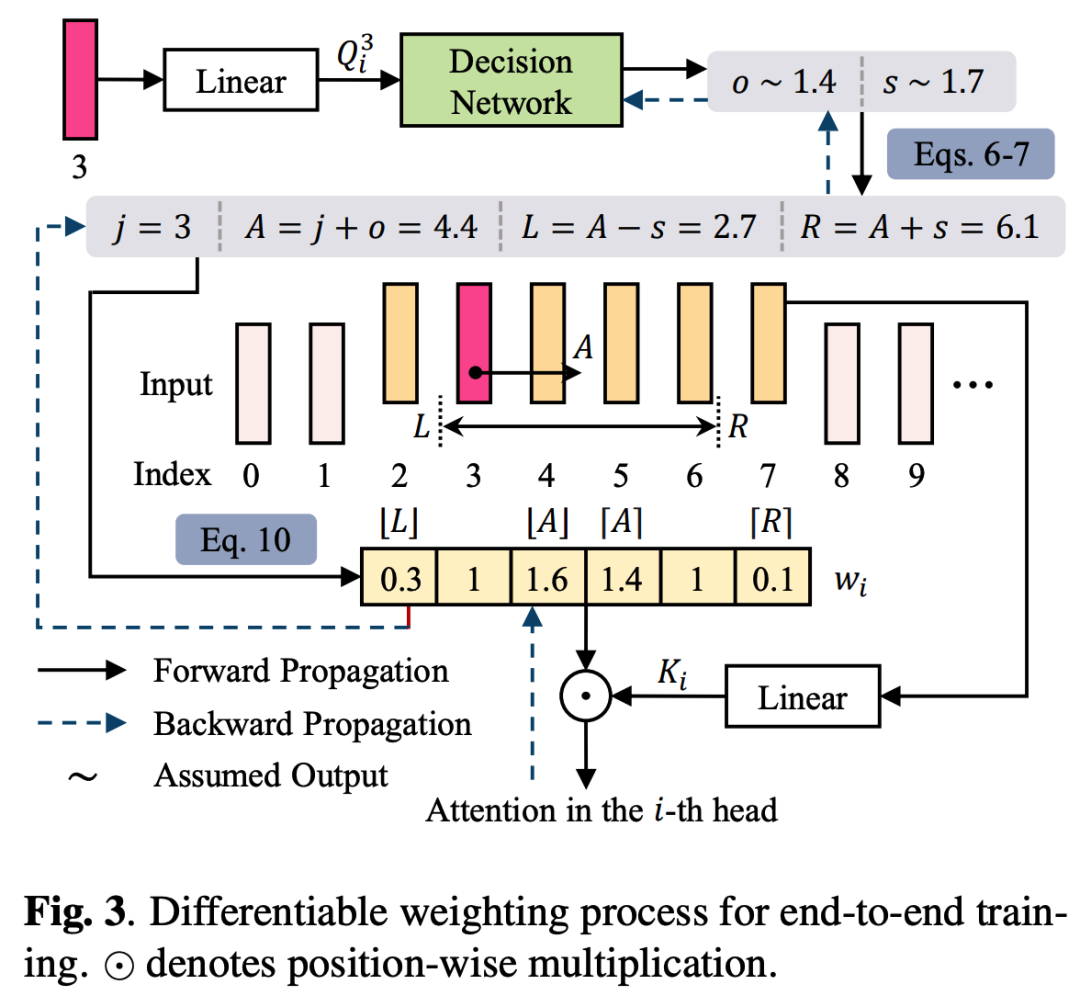
最终,决策网络可以以端到端的方式与整个模型一起进行优化。假设当前的索引为3,权重计算和加权过程如图3所示。
3 Experiments
3.1 Datasets and Acoustic Features
数据集:IEMOCAP、MELD
指标:weighted accuracy(WA)、unweighted accuracy(UA)、weighted average F1(WF1)
输入特征:采用WavLM模型提取声学特征。IEMOCAP和MELD样本的最大序列长度分别设定为326和224。
3.2 Training Details and Hyper-Parameters
我们使用随机梯度下降算法(SGD)来训练120 epochs,其中在IEMOCAP数据集上的学习率为5e−4,在MELD数据集上为1e−3。我们使用cosine annealing warm restarts scheduler来调整训练过程中的学习率。决策网络的学习率需要乘以0.1。batch大小设置为32,注意力头的数量为8,DST blocks的数量为4。
3.3 Experimental results and analysis
3.3.1 Comparison with Other Attention Mechanisms
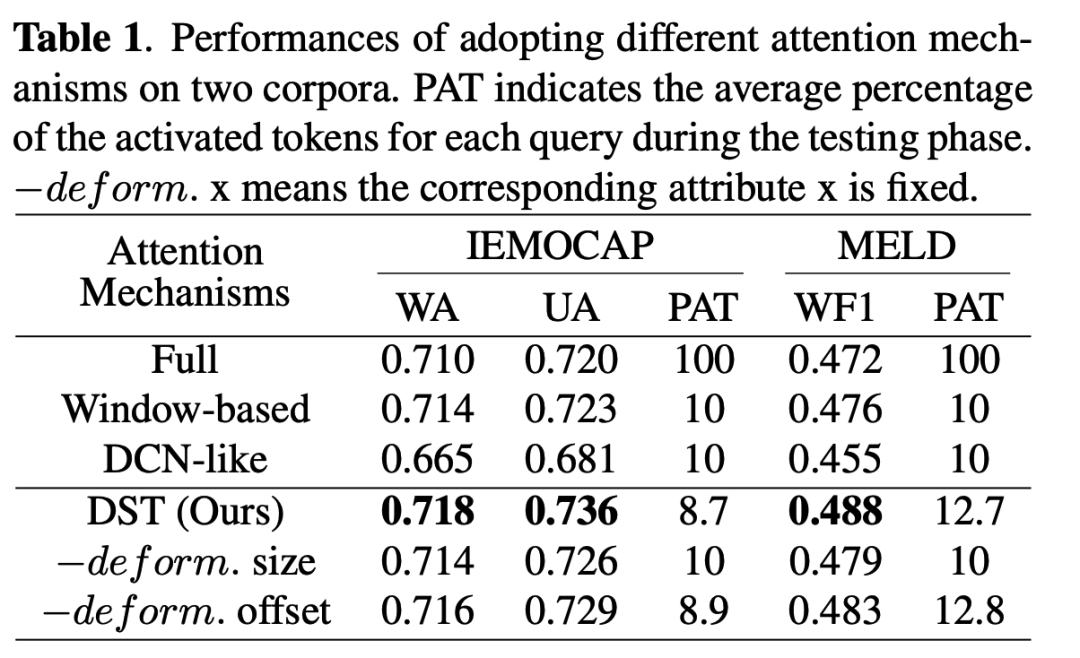
Performance Analysis:为了分析DST的优越性,我们实现了其他常见的注意力机制,包括全局注意机制、基于局部窗口的注意机制和类DCN的注意机制,并对它们进行比较。基于局部窗口的注意机制的窗口大小和类DCN的注意机制中采样点的数量设置为输入长度的10%。我们还提供每个query的平均激活tokens数量占输入tokens总量的百分比,方便进行全面的分析。如表1所示,DST在IEMOCAP和MELD数据集上的表现都要好于其他的注意机制。其中,使用类DCN注意机制会导致性能显著下降,这表明对语音信号进行连续建模是十分必要的。另外,我们发现在IEMOCAP上,每个query的平均激活tokens数量占输入总tokens数量的8.7%,而在MELD上,这个占比增加到12.7%。这种不确定性揭示了手动调整注意力窗口参数的困难性,而让模型自主确定窗口的配置是更好的选择。此外,DST可通过可变形能力学习所有潜在的细粒度和粗粒度情感特征。最后,我们进行了消融实验,我们丢弃了学习而来的窗口大小(-deform.size)或将学习而来的偏移量重置为零(-deform.offset),表1中最后两行的消融结果再次证实了本文所提出的可变形做法的有效性。
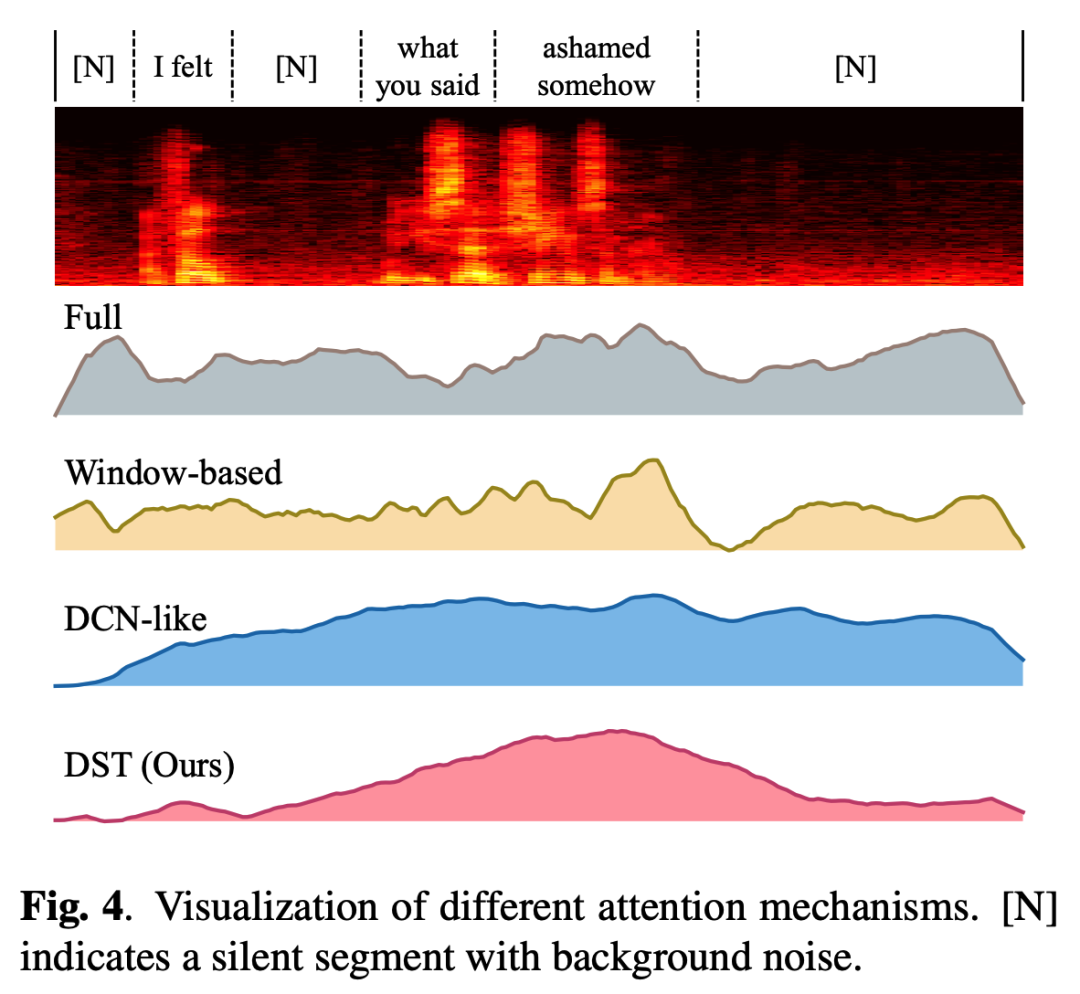
Visualization Analysis:为了进一步理解模型,我们考虑一段来自IEMOCAP的语音样本,并通过可视化直观地比较各种注意力机制中的权重。如图4所示,有声片段仅占整个语音样本中的一小部分。由于大量的噪声很容易使模型感到困惑,因此使用全局注意机制的模型很难突出语音中的关键部分。虽然基于局部窗口的注意机制能够学习细粒度特征,但当关键部分的持续时间和位置与其预先设定好的窗口不匹配时,其性能将会不可避免地受到限制。由于语音是连续信号,类DCN的注意机制无法通过离散的tokens判断每个tokens的重要性,导致其分配的权重之间的差异很小。DST成功地将注意力集中在关键片段(“somehow ashamed”),并通过学习而来的窗口大小和偏移量来突出它们。
3.3.2 Comparison to previous state-of-the-art
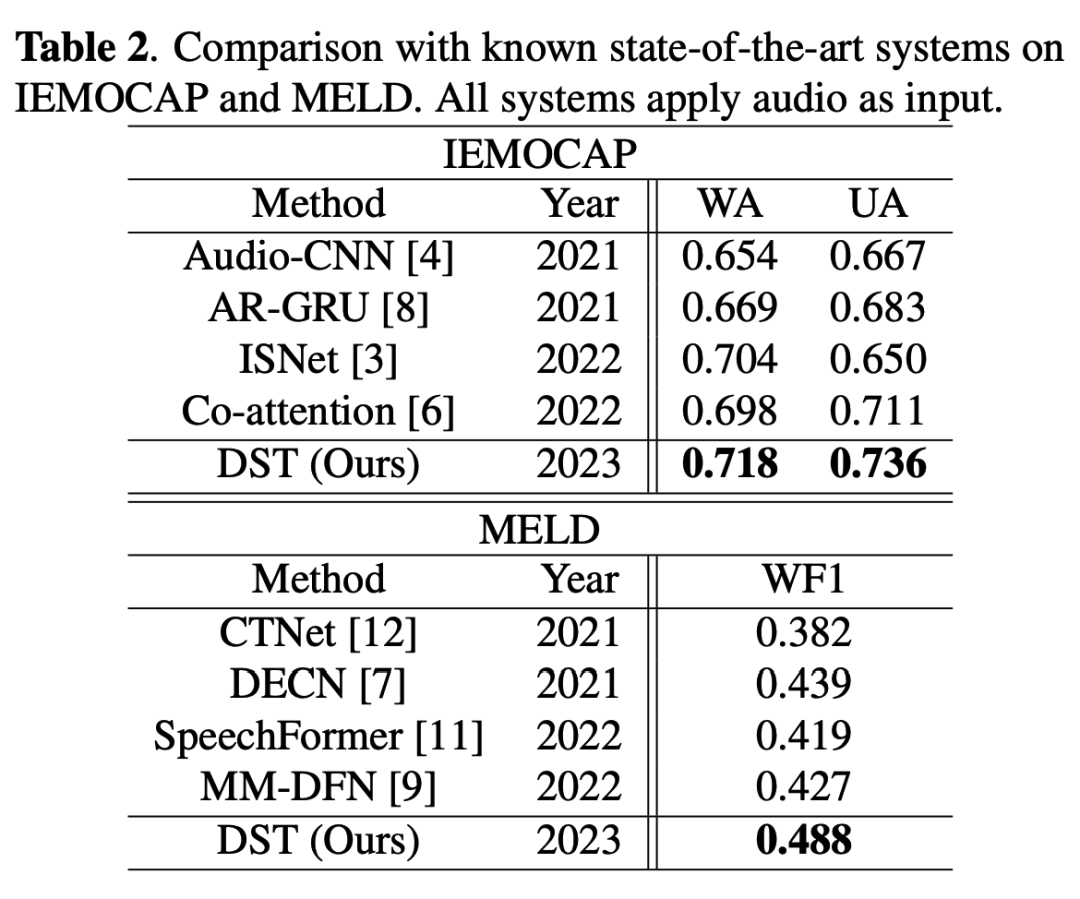
Table 2在IEMOCAP和MELD数据集上将所提的DST与一些已知方法进行比较。所有方法都采用声学特征作为输入以便进行公平的比较。在IEMOCAP上,DST要优于之前的方法。在MELD上,DST也超越了其他竞争对手。
4 Conclusion
本文为语音情感识别提出了一种名为DST的可变形Transformer方法。DST通过变形的注意力窗口有效地捕捉多粒度的情感信息。注意力窗口的大小和位置由模型自动确定。这种可变性显着提高了模型的灵活性和适应性。在IEMOCAP和MELD数据集的实验结果证明了DST的有效性。我们希望我们的工作能够在语音领域启发设计更灵活且高效的Transformer变体。在未来,我们计划将DST扩展到其他的语音任务并验证其通用性。
(论文翻译:华南理工大学 陈炜东)