论文题目:Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation
在同一个场景中,单目视觉深度信息、相机运动、光流、运动分割这些因素往往是相互联系、相互制约的,基于这一点作者提出了一种无监督方法,同时对这几种因素进行学习,并用他们的相互关系进行约束和增强,以此简化各个单独的问题。
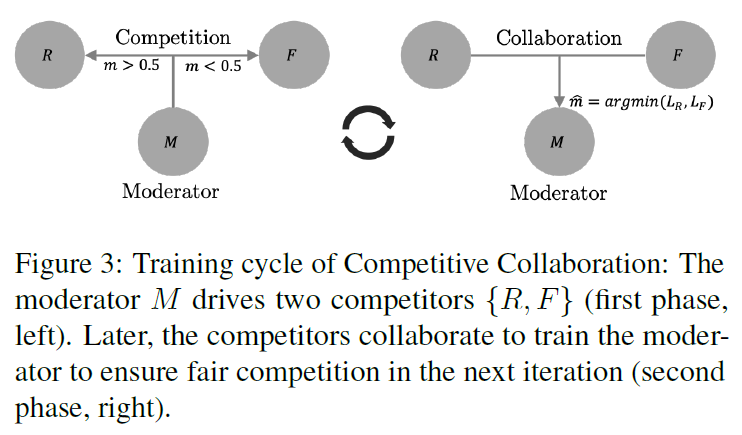
作者提出了一种网络 Competitive Collaboration (CC)。这个网络有两个 “玩家”,一个应用深度信息 D 和相机运动信息 C 来生成静态区域,称为 R ;另一个生成运动区域的图像,称为 F ,他们之间是竞争学习的关系。他们学习的效果由 “仲裁者” M 来实现,M是一个运动分割网络,将图片分割为运动部分和静态部分。但是M也是需要训练的,这个时候就需要R和F联合协作来训练M。
下面对这个网络进行一些数学上的表达。
考虑一个训练集
D
=
{
D
i
:
i
∈
N
}
\mathcal{D}=\{\mathcal{D}_i : i \in \mathbb{N} \}
D = { D i : i ∈ N } 训练分为两个阶段 :
固定仲裁者 M,用
E
1
E_1
E 1
E
1
=
∑
i
m
⋅
L
R
(
R
(
D
i
)
)
+
(
1
−
m
)
⋅
L
F
(
F
(
D
i
)
)
E_1 = \sum_i m \cdot L_R (R(\mathcal{D}_i)) + (1-m) \cdot L_F(F(\mathcal{D}_i))
E 1 = i ∑ m ⋅ L R ( R ( D i ) ) + ( 1 − m ) ⋅ L F ( F ( D i ) )
用
E
2
E_2
E 2
E
2
=
E
1
+
∑
i
L
M
(
D
i
,
R
,
F
)
E_2 = E_1 + \sum_i L_M(\mathcal{D}_i, R, F)
E 2 = E 1 + i ∑ L M ( D i , R , F )
网络 M 分割静态区域和运动区域,然后使得(D, C)只针对静态区域进行学习,而 F 则只针对运动区域进行学习。
考虑图像序列
I
−
,
I
,
I
+
I_-, I, I_+
I − , I , I +
I
−
,
I
+
I_-, I_+
I − , I +
深度
d
=
D
θ
(
I
)
d =D_\theta(I)
d = D θ ( I )
相机运动
e
−
,
e
+
=
C
ϕ
(
I
−
,
I
,
I
+
)
e_-, e_+ = C_\phi(I_-, I, I_+)
e − , e + = C ϕ ( I − , I , I + )
静止置信度
m
−
,
m
+
=
M
χ
(
I
−
,
I
,
I
+
)
m_-, m_+ = M_\chi(I_-, I, I_+)
m − , m + = M χ ( I − , I , I + )
光流
u
−
=
F
ψ
(
I
,
I
−
)
u_- = F_\psi(I,I_-)
u − = F ψ ( I , I − )
u
+
=
F
ψ
(
I
,
I
+
)
u_+ = F_\psi(I,I_+)
u + = F ψ ( I , I + )
注:
m
−
,
m
+
∈
[
0
,
1
]
Ω
m_-, m_+ \in [0,1]^\Omega
m − , m + ∈ [ 0 , 1 ] Ω
网络的优化目标是最小化能量E
E
=
λ
R
E
R
+
λ
F
E
F
+
λ
M
E
M
+
λ
C
E
C
+
λ
S
E
S
E = \lambda_R E_R + \lambda_F E_F + \lambda_M E_M + \lambda_C E_C + \lambda_S E_S
E = λ R E R + λ F E F + λ M E M + λ C E C + λ S E S
λ
M
\lambda_M
λ M
E
R
=
∑
s
∈
{
+
,
−
}
∑
Ω
ρ
(
I
,
ω
c
(
I
s
,
e
s
,
d
)
)
⋅
m
s
E_R = \sum_{s\in\{+,-\}} \sum_\Omega \rho(I, \omega_c(I_s, e_s, d)) \cdot m_s
E R = ∑ s ∈ { + , − } ∑ Ω ρ ( I , ω c ( I s , e s , d ) ) ⋅ m s
E
F
=
∑
s
∈
{
+
,
−
}
∑
Ω
ρ
(
I
,
ω
f
(
I
s
,
u
s
)
)
⋅
(
1
−
m
s
)
E_F = \sum_{s\in\{+,-\}} \sum_\Omega \rho(I, \omega_f(I_s, u_s)) \cdot (1-m_s)
E F = ∑ s ∈ { + , − } ∑ Ω ρ ( I , ω f ( I s , u s ) ) ⋅ ( 1 − m s )
ρ
(
x
,
y
)
=
λ
ρ
(
x
−
y
)
2
+
ϵ
2
+
(
1
−
λ
ρ
)
[
1
−
(
2
μ
x
μ
y
+
c
1
)
(
2
μ
x
y
+
c
2
)
(
μ
x
2
+
μ
y
2
+
c
1
)
(
σ
x
+
σ
y
+
c
2
)
]
\rho(x, y)=\lambda_{\rho} \sqrt{(x-y)^{2}+\epsilon^{2}}+\left(1-\lambda_{\rho}\right)\left[1-\frac{\left(2 \mu_{x} \mu_{y+c_{1}}\right)\left(2 \mu_{x y+c_{2}}\right)}{\left(\mu_{x}^{2}+\mu_{y}^{2}+c_{1}\right)\left(\sigma_{x}+\sigma_{y}+c_{2}\right)}\right]
ρ ( x , y ) = λ ρ ( x − y ) 2 + ϵ 2
+ ( 1 − λ ρ ) [ 1 − ( μ x 2 + μ y 2 + c 1 ) ( σ x + σ y + c 2 ) ( 2 μ x μ y + c 1 ) ( 2 μ x y + c 2 ) ]
E
M
=
∑
s
∈
{
+
,
−
}
∑
Ω
H
(
1
,
m
s
)
E_{M}=\sum_{s \in\{+,-\}} \sum_{\Omega} H\left(\mathbf{1}, m_{s}\right)
E M = ∑ s ∈ { + , − } ∑ Ω H ( 1 , m s )
E
C
=
∑
s
∈
{
+
,
−
}
∑
Ω
H
(
I
ρ
R
<
ρ
F
∨
I
∥
ν
(
e
s
,
d
)
−
u
s
∣
∣
<
λ
c
,
m
s
)
E_{C}=\sum_{s \in\{+,-\}} \sum_{\Omega} H\left(\mathbb{I}_{\rho_{R}<\rho_{F}} \vee \mathbb{I}_{ \| \nu\left(e_{s}, d\right)-u_{s}| |<\lambda_{c}}, m_{s}\right)
E C = ∑ s ∈ { + , − } ∑ Ω H ( I ρ R < ρ F ∨ I ∥ ν ( e s , d ) − u s ∣ ∣ < λ c , m s )
E
S
=
∑
Ω
∥
λ
e
∇
d
∥
2
+
∥
λ
e
∇
u
−
∥
2
+
∥
λ
e
∇
u
+
∥
2
+
∥
λ
e
∇
m
−
∥
2
+
∥
λ
e
∇
m
+
∥
2
E_{S}=\sum_{\Omega}\left\|\lambda_{e} \nabla d\right\|^{2}+\left\|\lambda_{e} \nabla u_{-}\right\|^{2}+\left\|\lambda_{e} \nabla u_{+}\right\|^{2} + \left\|\lambda_{e} \nabla m_{-}\right\|^{2}+\left\|\lambda_{e} \nabla m_{+}\right\|^{2}
E S = ∑ Ω ∥ λ e ∇ d ∥ 2 + ∥ λ e ∇ u − ∥ 2 + ∥ λ e ∇ u + ∥ 2 + ∥ λ e ∇ m − ∥ 2 + ∥ λ e ∇ m + ∥ 2
对上面几个式子的解释:
ω
c
\omega_c
ω c
d
d
d
e
e
e
I
−
或
I
+
I_-或I_+
I − 或 I +
I
I
I
ω
f
\omega_f
ω f
u
u
u
λ
ρ
\lambda_{\rho}
λ ρ
ϵ
=
0.01
\epsilon=0.01
ϵ = 0 . 0 1
μ
x
,
σ
x
\mu_{x}, \sigma_{x}
μ x , σ x
c
1
=
0.0
1
2
c_{1}=0.01^{2}
c 1 = 0 . 0 1 2
c
2
=
0.0
3
2
c_{2}=0.03^{2}
c 2 = 0 . 0 3 2
E
M
E_M
E M
H
(
)
H()
H ( )
λ
M
\lambda_M
λ M
ν
(
e
,
d
)
\nu(e, d)
ν ( e , d )
d
d
d
e
e
e
I
∈
{
0
,
1
}
\mathbb{I} \in\{0,1\}
I ∈ { 0 , 1 }
ρ
R
=
ρ
(
I
,
w
c
(
I
s
,
e
s
,
d
)
)
\rho_{R}=\rho\left(I, w_{c}\left(I_{s}, e_{s}, d\right)\right)
ρ R = ρ ( I , w c ( I s , e s , d ) )
ρ
F
=
ρ
(
I
,
w
f
(
I
s
,
u
s
)
)
\rho_{F}=\rho\left(I, w_{f}\left(I_{s}, u_{s}\right)\right)
ρ F = ρ ( I , w f ( I s , u s ) ) 第一个指示函数 选择那些更偏向于静止区域的像素点;第二个指示函数 同样选择那些最可能是静止区域的点;最后他们取并集
∨
\vee
∨
m
s
m_s
m s 因此“一致代价”
E
C
E_C
E C 。“平滑代价”
E
S
E_S
E S
λ
e
=
e
−
∇
I
\lambda_{e}=e^{-\nabla I}
λ e = e − ∇ I
λ
e
\lambda_{e}
λ e
要想训练这个网络,需要通过重建图像的效果来判断网络各部分(深度、光流、分割)的预测效果。在重建图像时,对图像运动部分和静止部分的分割由以下公式获得
m
∗
=
I
m
+
⋅
m
−
>
0.5
∨
I
∥
ν
(
e
+
,
d
)
−
u
+
∥
<
λ
c
m^{*}=\mathbb{I}_{m_{+} \cdot m_{-}>0.5} \vee \mathbb{I}_{\left\|\nu\left(e_{+}, d\right)-u_{+}\right\|<\lambda_{c}}
m ∗ = I m + ⋅ m − > 0 . 5 ∨ I ∥ ν ( e + , d ) − u + ∥ < λ c
u
∗
=
I
m
∗
>
0.5
⋅
ν
(
e
+
,
d
)
+
I
m
∗
≤
0.5
⋅
u
+
u^{*}=\mathbb{I}_{m^{*}>0.5} \cdot \nu\left(e_{+}, d\right)+\mathbb{I}_{m^{*} \leq 0.5} \cdot u_{+}
u ∗ = I m ∗ > 0 . 5 ⋅ ν ( e + , d ) + I m ∗ ≤ 0 . 5 ⋅ u +
d
d
d
e
e
e
u
∗
u^*
u ∗
m
∗
m^*
m ∗
因此最终训练的时候在开头提到的那两个阶段,第一个阶段就可以用
E
R
E_R
E R
E
F
E_F
E F
E
M
E_M
E M
E
C
E_C
E C
算法的伪代码如下:
附录的东西我就不放了哈,大家想看可以去读作者的论文。
 一些实验结果如下所示
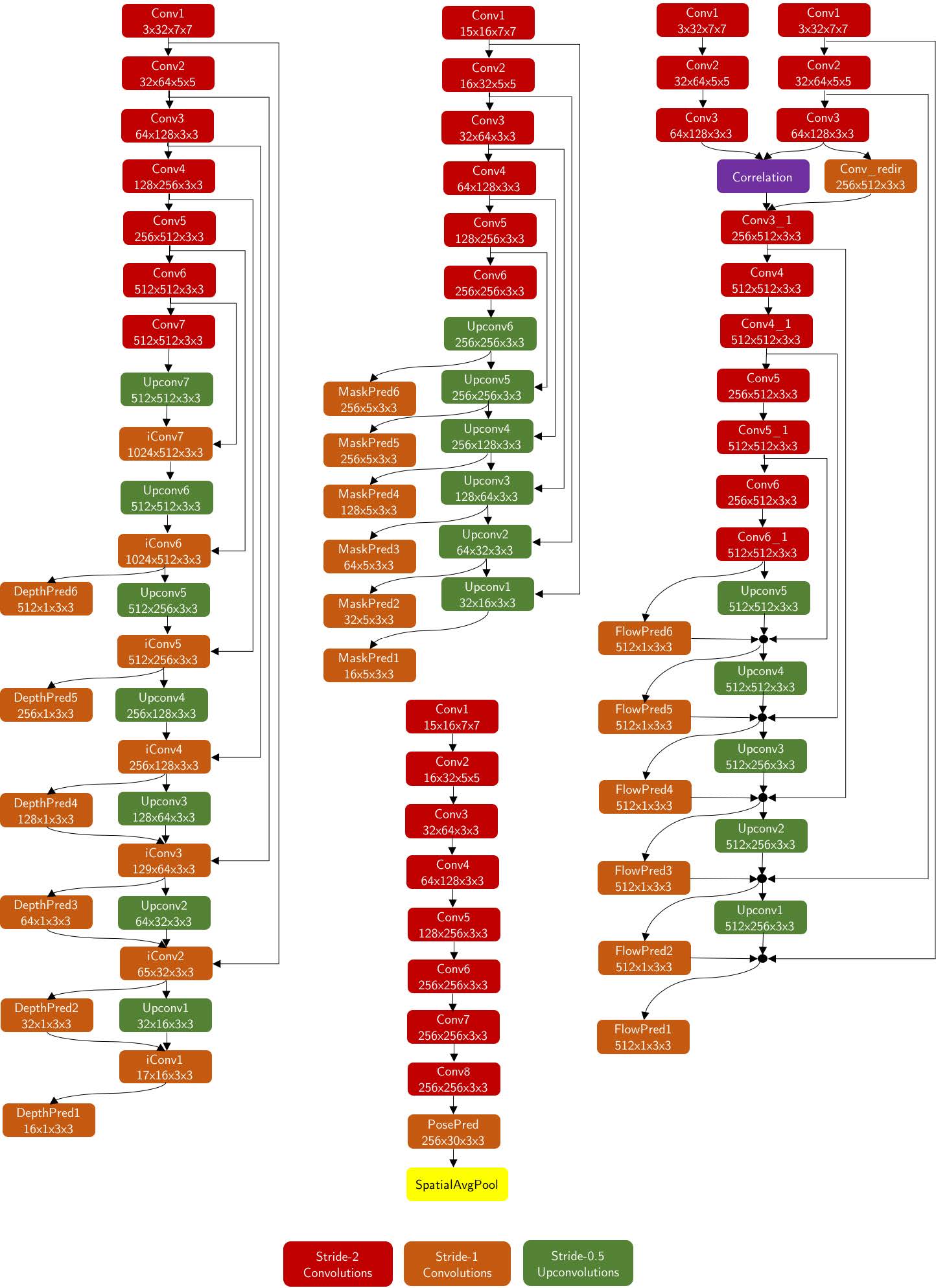
一些实验结果如下所示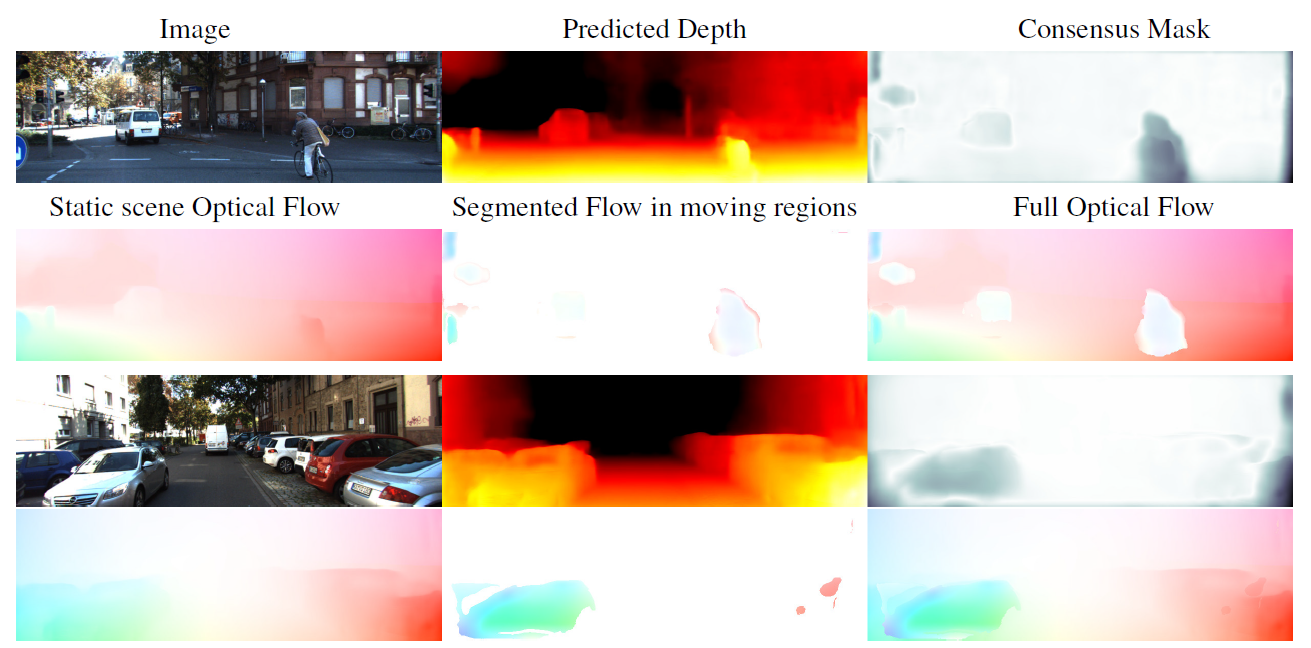 更详细的网络结构如下图
更详细的网络结构如下图