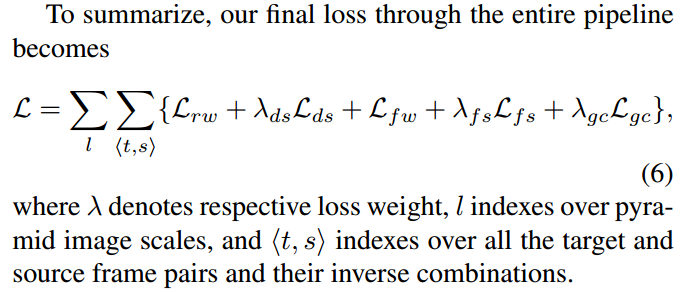论文信息
题目:GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose
作者:Zhichao Yin and Jianping Shi
来源:CVPR
时间:2018
Abstract
我们提出了 GeoNet,这是一种联合无监督学习框架,用于视频中的单目深度、光流和自我运动估计。
这三个组件通过 3D 场景几何的性质耦合在一起,由我们的框架以端到端的方式共同学习。具体来说,根据各个模块的预测提取几何关系,然后将其组合为图像重建损失,分别对静态和动态场景部分进行推理。
此外,我们提出了一种自适应几何一致性损失,以提高对异常值和非朗伯区域的鲁棒性,从而有效地解决遮挡和纹理模糊问题。
Introduction
在本文中,我们提出了一种无监督学习框架 GeoNet,用于联合估计视频中的单眼深度、光流和相机运动。我们的方法的基础建立在 3D 场景几何的性质之上(详细信息请参见第 3.1 节)。
直观的解释是,大多数自然场景都是由刚性静态表面组成,即道路、房屋、树木等。它们在视频帧之间投影的二维图像运动可以完全由深度结构和相机运动决定。同时,此类场景中普遍存在行人和汽车等动态物体,通常具有位移大、排列混乱的特点。
因此,我们使用深度卷积网络抓住了上述原则。具体来说,我们的范例采用了分而治之的策略。设计了一种由两个阶段组成的新颖的级联架构来自适应地解决场景刚体流和目标运动。因此,全局运动场能够逐步细化,使我们的完整学习流程变得分解且更易于学习。这种融合运动场引导的视图合成损失导致无监督学习的自然正则化。预测示例如图 1 所示。

作为第二个贡献,我们引入了一种新颖的自适应几何一致性损失,以克服纯视图合成目标中未包含的因素,例如遮挡处理和照片不一致问题。通过模仿传统的前后(或左右)一致性检查,我们的方法自动过滤掉可能的异常值和遮挡。在非遮挡区域中的不同视图之间强制执行预测一致性,而错误的预测会被平滑,尤其是在遮挡区域中。
Related Work
场景流估计是与我们的工作密切相关的另一个主题,它从立体图像序列中解决场景的密集 3D 运动场 [49]。 KITTI 基准上排名靠前的方法通常涉及几何、刚性运动和分割的联合推理 [3, 51]。 MRF [27] 被广泛采用来将这些因素建模为离散标记问题。然而,由于存在大量需要优化的变量,这些现成的方法在实际使用中通常太慢。另一方面,最近的几种方法强调了通用场景流中的严格规律。 Taniai 等人[46]提出使用二元掩模从刚性场景中分割出移动物体。 Sevilla-Lara 等人[41]根据语义分割定义了不同的图像运动模型。
Method
在本节中,我们从 3D 场景几何的本质开始。然后我们概述了 GeoNet。它由两个组件组成:分别是刚性结构重建器和非刚性运动定位器。
最后,我们提出了几何一致性执行,这是 GeoNet 的核心。
Nature of 3D Scene Geometry
视频或图像是 3D 空间投影到特定维度的屏幕截图。 3D 场景自然由静态背景和移动对象组成。视频中静态部分的运动完全是由摄像机运动和深度结构引起的。而动态物体的运动则更为复杂,由均匀的相机运动和特定物体运动共同作用。
与完整的场景理解相比,理解均匀的相机运动相对容易,因为大部分区域都受到其约束。
为了从本质上分解 3D 场景理解问题,我们希望分别学习由相机运动控制的场景级一致运动,即刚性流和具体的物体运动。
为了对严格限制的刚性流进行建模,我们通过帧 i 的深度图 D i D_i Di 的集合以及从目标帧到源帧的相对相机运动 T t → s T_{t→s} Tt→s 来定义静态场景几何形状。从目标图像 I t I_t It到源图像 I s I_s Is的相对二维刚性流可以表示为:

另一方面,我们将无约束的物体运动建模为经典光流概念,即二维位移矢量。
我们学习残差流 f t → s r e s f^{res}_{t→s} ft→sres 而不是非刚性情况的完整表示。
GeoNet OverViwe
我们提出的 GeoNet 以无人监督的方式感知 3D 场景几何的本质。
特别是,
- 我们使用单独的组件分别通过刚性结构重建器和非刚性运动定位器来学习刚性流和物体运动。
- 采用图像外观相似度来指导无监督学习,可以推广到无限数量的视频序列,而无需任何标记成本。
我们的 GeoNet 的概述如图 2 所示。
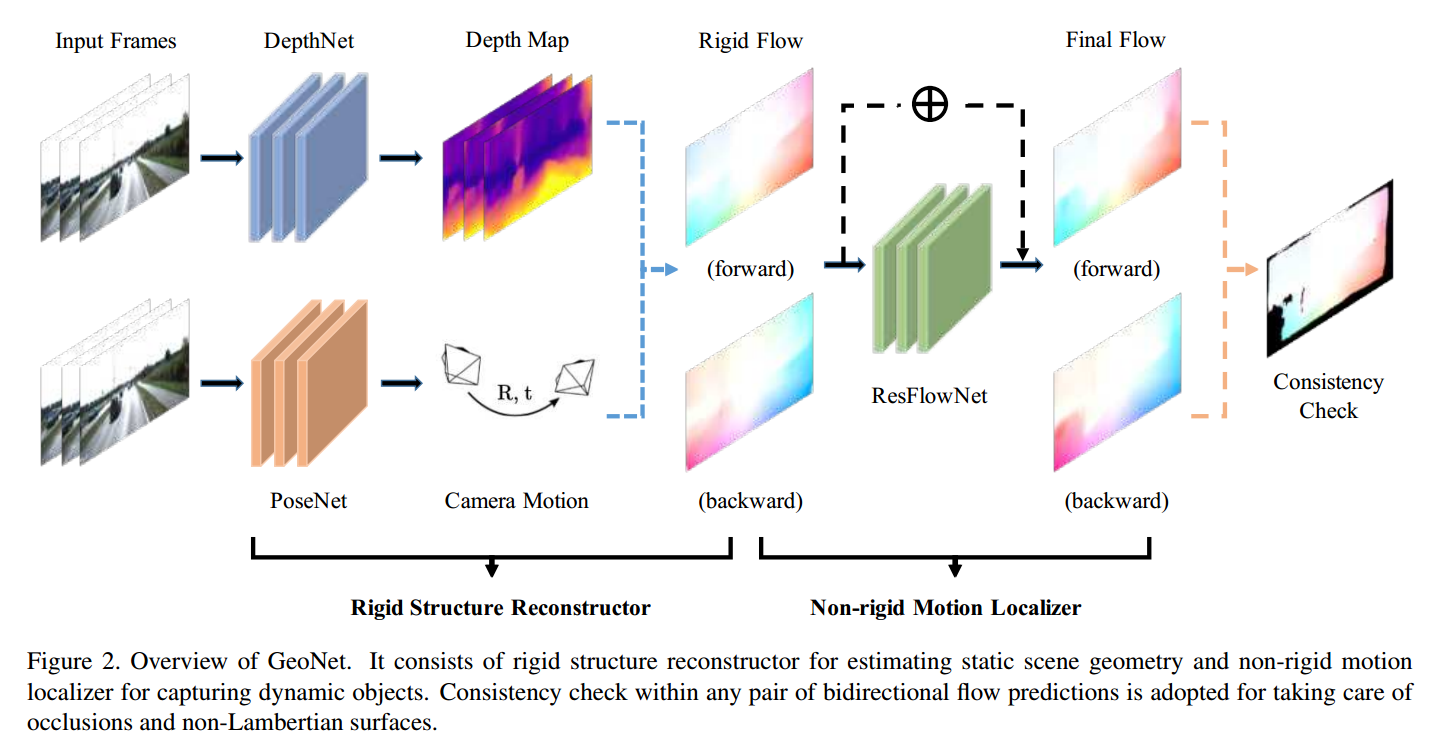
它包含两个阶段,刚性结构推理阶段和非刚性运动细化阶段。
推断场景布局的第一阶段由两个子网络组成,即 DepthNet 和 PoseNet。深度图和相机位姿分别回归并融合以产生刚性流。
第二阶段由 ResFlowNet 完成以处理动态对象。 ResFlowNet 学习到的残余非刚性流与刚性流相结合,得出我们最终的流预测。由于我们的每个子网络都针对特定的子任务,因此复杂的场景几何理解目标被分解为一些更简单的目标。不同阶段的视图合成是我们无监督学习范式的基本监督。
最后但并非最不重要的一点是,我们在训练期间进行几何一致性检查,这显着增强了我们预测的一致性并取得了令人印象深刻的性能
Rigid Structure Reconstructor
我们的第一阶段旨在重建刚性场景结构,并对非刚性和异常值具有鲁棒性。
训练示例是具有已知相机内在特性的时间连续帧 I i ( i = 1 ∼ n ) I_i(i = 1 ∼ n) Ii(i=1∼n)。通常,目标帧 I t I_t It被指定为参考视图,而其他帧是源帧 I s I_s Is。
DepthNet 将单一视图作为输入,并利用累积的场景先验进行深度预测。在训练期间,整个序列被视为独立图像的小批量并输入到 DepthNet 中。
相反,为了更好地利用不同视图之间的特征对应关系,我们的 PoseNet 将沿通道维度连接的整个序列作为输入,一次性回归所有相对 6DoF 相机姿势 T t → s T_{t→s} Tt→s。
基于这些基本预测,我们能够根据方程(1) 推导出全局刚性流。 我们可以立即合成任意一对目标帧和源帧之间的另一个视图。
我们将 I ~ s r i g \tilde{I}^{rig}_s I~srig 表示为基于 f t → s r i g f^{rig}_{t→s} ft→srig 从 I s I_s Is 到目标图像平面的逆扭曲图像。
因此,我们当前阶段的监督信号自然以最小化合成视图 I ~ s r i g \tilde{I}^{rig}_s I~srig 和原始帧 I t I_t It 之间的差异(或相反)的形式出现。
但需要指出的是,刚性流仅主导非遮挡刚性区域的运动,而在非刚性区域则失效。尽管这种负面影响在相当短的序列中略有减轻,但我们对光度损失采用了鲁棒的图像相似性测量[15],它保持了适当的感知相似性评估和异常值的适度弹性之间的平衡,并且本质上是可微分的如下:

Non-rigid Motion Localizer
第一阶段为我们提供了刚性场景布局的立体感知,却忽略了动态物体的普遍存在。因此,我们提出了第二个组件,即 ResFlowNet 来定位非刚性运动。
直观上,通用光流可以直接对无约束运动进行建模,这在现成的深度模型中通常采用[8, 18]。但它们并没有充分利用刚性区域的良好约束特性,而我们实际上已经在第一阶段做到了这一点。
我们制定 ResFlowNet 来学习残余非刚性流,即仅由相对于世界平面的对象运动引起的移动。具体来说,我们按照[18]推荐的方式在第一阶段之后级联 ResFlowNet。对于任何给定的帧对,ResFlowNet 利用刚性结构重建器的输出,并预测相应的残差信号 f t → s r e s f^{res}_{t→s} ft→sres 。最终的全流预测 f t → s f u l l f^{full}_{t→s} ft→sfull 由 f t → s r i g + f t → s r e s f^{rig}_{t→s} + f^{res}_{t→s} ft→srig+ft→sres 构成。
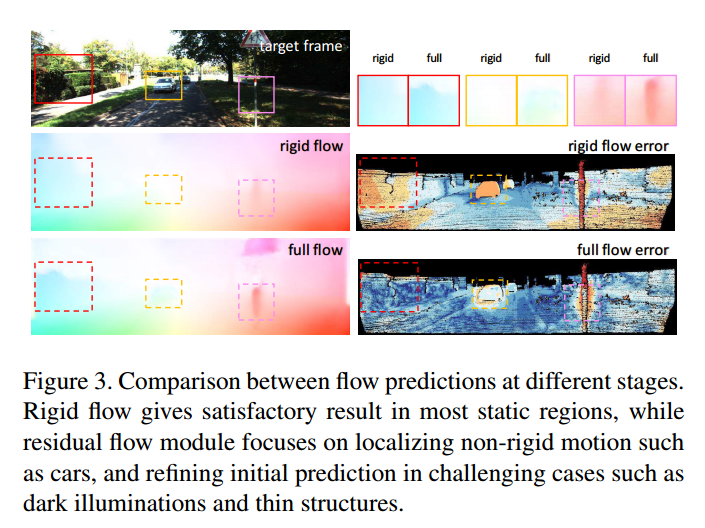
如图 3 所示,我们的第一阶段,刚性结构重建器,在大多数刚性场景中产生高质量的重建,这为我们的第二阶段奠定了良好的起点。因此,我们的运动定位器中的 ResFlowNet 仅关注其他非刚性残基。请注意,ResFlowNet 不仅可以纠正动态对象中的错误预测,而且由于我们的端到端学习协议,还可以改进第一阶段可能由高饱和度和极端照明条件引起的不完美结果。
同样,我们可以简单修改一下把第一阶段扩展到第二阶段。具体来说,按照完整流程 f t → s f u l l f^{full}_{t→s} ft→sfull ,我们再次在任意一对目标帧和源帧之间执行图像扭曲。将等式(2) 中的 I ~ s r i g \tilde{I}^{rig}_s I~srig 替换为 I ~ s f u l l \tilde{I}^{full}_s I~sfull得到完整变形损失 L f w L_{fw} Lfw。类似地,我们扩展了方程(3) 中二维光流场的平滑度损失,我们将其表示为 L f s L_{fs} Lfs。
Geometric Consistency Enforcement
我们的 GeoNet 采用刚性结构重建器用于静态场景,采用非刚性运动定位器作为动态物体的补偿。两个阶段都利用视图合成目标作为监督,并隐含地假设光度一致性。尽管我们采用了强大的图像相似性评估,例如等式 (2)。
遮挡和非朗伯曲面在实践中仍然无法完美处理。
为了进一步减轻这些影响,我们在学习框架中应用了前向后向一致性检查,而不改变网络架构。 Godard 等人 [15] 的工作将类似的想法融入到他们的具有左右一致性损失的深度学习方案中。然而,我们认为这种一致性约束以及扭曲损失不应该强加在遮挡区域(参见第 4.3 节)。相反,我们优化了最终运动场的自适应一致性损失。
具体来说,我们的几何一致性强制是通过优化以下目标来实现的

由于这些区域违反了照片一致性以及几何一致性假设,因此我们仅使用平滑度损失 L f s L_{fs} Lfs 来处理它们。因此,我们的全流扭曲损失 L f w L_{fw} Lfw 和几何一致性损失 L g c L_{gc} Lgc 均按 [ δ ( p t ) ] [δ(pt)] [δ(pt)] 像素加权。