matplotlib绘图和可视化
matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面)。绘图是数据分析工作中最重要的任务之一,是探索过程的一部分。
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
from numpy.random import randnplt.plot(np.arange(15))
plt.show()
Figure和Subplot
fig=plt.figure()
ax1=fig.add_subplot(2,2,1)
ax2=fig.add_subplot(2,2,2)
ax3=fig.add_subplot(2,2,3)plt.plot(np.random.randn(50).cumsum(),'k--')_=ax1.hist(np.random.randn(100),bins=20,color='r',alpha=0.3)
ax2.scatter(np.arange(30),np.arange(30)+3*np.random.randn(30))
plt.show()
plt.subplots,它可以创建一个新的Figure,并返回一个含有已创建的subplot对象的NumPy数组
fig,axes=plt.subplots(2,3)
axesarray([[<matplotlib.axes._subplots.AxesSubplot object at 0x0000000012981F98>,
<matplotlib.axes._subplots.AxesSubplot object at 0x0000000012835FD0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x00000000129EAFD0>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x000000001298C9B0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x00000000127EDA20>,
<matplotlib.axes._subplots.AxesSubplot object at 0x00000000125DBEB8>]], dtype=object)

调整subplot周围的间距
Figure的subplots_adjust方法可以修改间距
#subplots_adjust(left=None,bottom=None,right=None,top=None,wpace=None,hspace=None)
fig,axes=plt.subplots(2,2,sharex=True,sharey=True)
for i in range(2):
for j in range(2):
axes[i,j].hist(randn(500),bins=50,color='k',alpha=0.6)
plt.subplots_adjust(wspace=0,hspace=0)
plt.show()
颜色、标记和线型
matplotlib的plot函数接受一组X和Y坐标,还可以接受一个表示颜色和线型的字符串缩写
ax.plot(x,y,'g--') #根据x和y绘制绿色虚线
ax.plot(x,y,linestyle='--',color='g')plt.plot(np.random.randn(30).cumsum(),'ko--')
plt.show()
可以把它写成更为明确的方式
plt.plot(np.random.randn(30).cumsum(),color='b',linestyle='dashed',marker='o')
plt.show()
在线型图中,非实际数据点默认是按线性方式插值的。可以通过drawstyle选项修改
data=np.random.randn(30).cumsum()
plt.plot(data,'k--',label='Default')
plt.show()
plt.plot(data,'k-',color='b',drawstyle='steps-post',label='steps-post')
plt.show()
plt.plot(data,'k-',color='b',drawstyle='steps-post',label='steps-post')
plt.legend(loc='best')
plt.show()
刻度、标签和图例
设置标题、轴标签、刻度以及刻度标签
创建一个简单的图像并绘制一段随机漫步
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(np.random.randn(1000).cumsum())
plt.show()
可以使用set_xticks和set_xticklabels修改X轴的刻度
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(np.random.randn(1000).cumsum())
#用set_xticks修改X轴的刻度
ticks=ax.set_xticks([0,250,500,750,1000])
#可以通过set_xticklabels将任何其他的值用作标签
labels=ax.set_xticklabels(['one','two','three','four','five'],rotation=30,fontsize='small')
#用set_title给图表设置一个标题
ax.set_title('My first matplotlib plot')
#为X轴设置一个名称
ax.set_xlabel('Stages')
plt.show()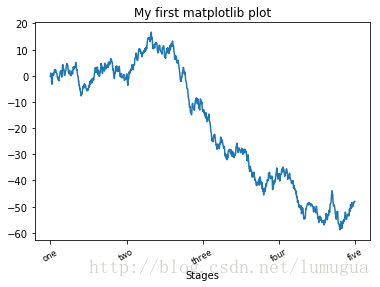
添加图例(legend)
在添加subplot的时候传入label参数来添加图例
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(np.random.randn(1000).cumsum(),'k',label='one',color='r')
ax.plot(np.random.randn(1000).cumsum(),'k--',label='two',color='g')
ax.plot(np.random.randn(1000).cumsum(),'k.',label='three',color='b')
ax.legend(loc='best')
plt.show()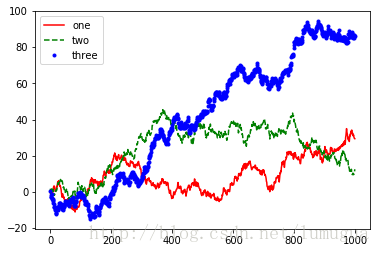
调用ax.legend()或plt.legend()来自动创建图例
loc告诉matplotlib要将图例放在哪,’beat’里面可以显示确定的位置,如下:best
upper right
upper left
lower left
lower right
right
center left
center right
lower center
upper center
center
如果要从图例中去除一个或多个元素,不传入label或传入label=’nolegend’
注解以及在Subplot上绘图
注解可以是文本、箭头或其他图形等,通过text、arrow和annotate等函数进行添加。text可以将文本绘制在图表的指定坐标(x,y),还可以加上一些自定义格式
ax.text(x,y,"hello world!",Family='monospace',fontsize=10)from datetime import datetime
import pandas as pd
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
data=pd.read_csv('examples/spx.csv',index_col=0,parse_dates=True)
spx=data['SPX']
spx.plot(ax=ax,style='k-')
crisis_data=[
(datetime(2007,10,11),'Peak of bull market'),
(datetime(2008,3,12),'Bear Stearns Fails'),
(datetime(2008,9,15),'Lehman Bankruptcy')]
for date,label in crisis_data:
ax.annotate(label,xy=(date,spx.asof(date)+50),
xytext=(date,spx.asof(date)+200),
arrowprops=dict(facecolor='black'),
horizontalalignment='left',verticalalignment='top')
# 放大到2007-2010
ax.set_xlim(['1/1/2007','1/1/2011'])
ax.set_ylim([600,1800])
ax.set_title('Important dates in 2008-2009 financial crisis')
plt.show()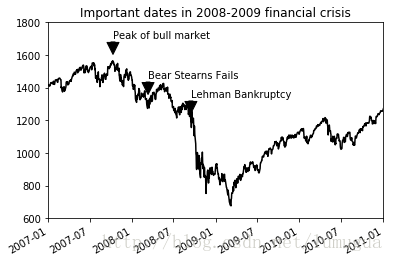
图2008-2009年金融危机期间的重要日期
要在图表中添加一个图形,你需要创建一个块对象shp,然后通过ax.add_patch(shp)将其添加到subplot中
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
rect=plt.Rectangle((0.2,0.75),0.4,0.15,color='r',alpha=0.6)
circ=plt.Circle((0.7,0.2),0.15,color='b',alpha=0.3)
pgon=plt.Polygon([[0.15,0.15],[0.35,0.4],[0.2,0.6]],color='g',alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)
plt.show()
将图表保存到文件
利用plt.savefig可以将当前图表保存到文件。该方法相当于Figure对象的实例方法savefig
plt.savefig('figpath.svg')plt.savefig('figpath.png',dpi=400,bbox_inches='tight')from io import StringIO
plt.savefig(buffer)
plot_data=buffer.getvaule()
matplotlib配置
matplotlib自带一些配色方案,以及为生成出版质量的图片而设定的默认配置信息,可以管理图像大小、subplot边距、配色方案、字体大小、网格类型等。操作matplotlib配置系统的方式主要有两种。第一种是Python编程方式,即利用rc方法
将全局的图像默认大小设置为10×10
plt.rc('figure',figsize=(10,10))font_opinions={'family':'monospace','weight':'bold','size':'samll'}
plt.rc('font',**font_options)pandas中的绘图函数
pandas在线文档将会是最好的绘图函数学习资源。
线型图
Series对象的索引会被传给matplotlib,并用以绘制X轴。可以通过use_index=False禁用该功能。
X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim
s=Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10))
s.plot()
plt.show()
pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。这使你能够在网格布局中更为灵活地处理subplot的位置。
DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例。
df=DataFrame(np.random.randn(10,4).cumsum(0),columns=['A','B','C','D'],index=np.arange(0,100,10))
df.plot()
plt.show()
注意: plot的其他关键字参数会被传给相应的matplotlib绘图函数,所以要更深入地自定义图表,就必须学习更多有关matplotlib API的知识。
柱状图
在生成线型图的代码中加上kind=’bar’(垂直柱状图)或kind=’barh’(水平柱状图)即可生成柱状图。这时,Series和DataFrame的索引将会被用作X(bar)或Y(barh)刻度
fig,axes=plt.subplots(2,1)
data=Series(np.random.rand(16),index=list('abcdefghijklmnop'))
data.plot(kind='bar',ax=axes[0],color='g',alpha=0.6)
data.plot(kind='barh',ax=axes[1],color='g',alpha=0.6)
plt.show()
对于DataFrame,柱状图会将每一行的值分为一组
df=DataFrame(np.random.rand(6,4),index=['one','two','three','four','five','six'],columns=['A','B','C','D'])
df| A | B | C | D | |
|---|---|---|---|---|
| one | 0.381932 | 0.042627 | 0.290334 | 0.700356 |
| two | 0.212308 | 0.519060 | 0.241667 | 0.653755 |
| three | 0.223746 | 0.233344 | 0.714892 | 0.620117 |
| four | 0.401946 | 0.862935 | 0.874891 | 0.862926 |
| five | 0.680490 | 0.879683 | 0.562349 | 0.036203 |
| six | 0.791145 | 0.873458 | 0.604575 | 0.479191 |
df.plot(kind='bar')
plt.show()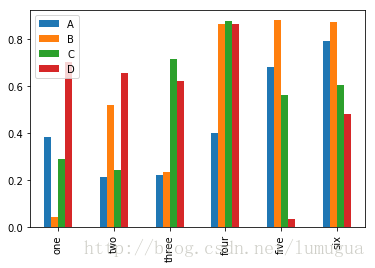
DataFrame各列的名称”Genus”被用作了图例的标题。设置stacked=True即可为DataFrame生成堆积柱状图,这样每行的值就会被堆积在一起
提示:柱状图有一个非常不错的用法:利用value_counts图形化显示Series中各值的出现频率,比如s.value_counts ().plot(kind=’bar’)。
df.plot(kind='barh',stacked=True,alpha=0.8)
plt.show()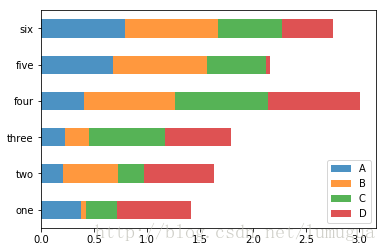
以本书的有关小费的数据集为例,假设我们想要做一张堆积柱状图以展示每天各种聚会规模的数据点的百分比。我用read_csv将数据加载进来,然后根据日期和聚会规模创建一张交叉表
tips=pd.read_csv('examples/tips.csv')
#如果通过tips.size,取到的是一整列的和
party_counts=pd.crosstab(tips.day,tips['size'])
party_counts| size | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| day | ||||||
| Fri | 1 | 16 | 1 | 1 | 0 | 0 |
| Sat | 2 | 53 | 18 | 13 | 1 | 0 |
| Sun | 0 | 39 | 15 | 18 | 3 | 1 |
| Thur | 1 | 48 | 4 | 5 | 1 | 3 |
进行规格化,使得各行的和为1(必须转换成浮点数),并生成图表
party_counts=party_counts.ix[:,2:5]# 1个人和6个人的聚会都比较少
party_pcts=party_counts.div(party_counts.sum(1).astype(float),axis=0)
party_pcts| size | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| day | ||||
| Fri | 0.888889 | 0.055556 | 0.055556 | 0.000000 |
| Sat | 0.623529 | 0.211765 | 0.152941 | 0.011765 |
| Sun | 0.520000 | 0.200000 | 0.240000 | 0.040000 |
| Thur | 0.827586 | 0.068966 | 0.086207 | 0.017241 |
通过该数据集就可以看出,聚会规模在周末会变大
直方图和密度图
直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量
以前面那个小费数据为例,通过Series的hist方法,我们可以生成一张“小费占消费总额百分比”的直方图
tips['tip_pct']=tips['tip']/tips['total_bill']
tips['tip_pct'].hist(bins=50)
plt.show()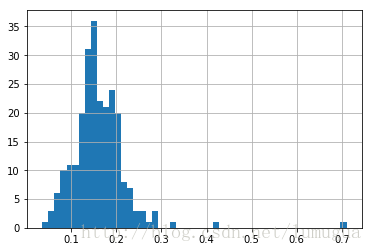
小费百分比的直方图
与此相关的一种图表类型是密度图,它是通过计算“可能会产生观测数据的连续概率分布的估计”而产生的。一般的过程是将该分布近似为一组核(即诸如正态(高斯)分布之类的较为简单的分布)。
调用plot时加上kind=’kde’即可生成一张密度图(标准混合正态分布KDE)
tips['tip_pct'].plot(kind='kde')
plt.show()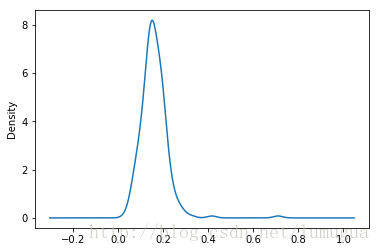
小费百分比的密度图
这两种图表常常会被画在一起。直方图以规格化形式给出(以便给出面元化密度),然后再在其上绘制核密度估计。接下来来看一个由两个不同的标准正态分布组成的双峰分布
comp1=np.random.normal(0,1,size=200)#N(0,1)
comp2=np.random.normal(10,2,size=200)# (10,4)
values=Series(np.concatenate([comp1,comp2]))
values.hist(bins=100,alpha=0.3,color='g',normed=True)
values.plot(kind='kde',style='k--')
plt.show()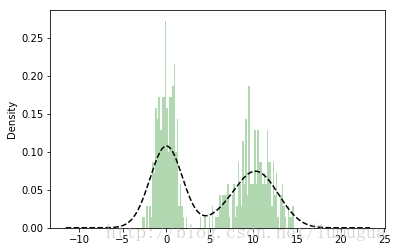
散布图
散布图(scatter plot)是观察两个一维数据序列之间的关系的有效手段。matplotlib的scatter方法是绘制散布图的主要方法
通过例子看看,首先加载了来自statsmodels项目的macrodata数据集,选择其中几列,然后计算对数差
macro=pd.read_csv('examples/macrodata.csv')
data=macro[['cpi','m1','tbilrate','unemp']]
trans_data=np.log(data).diff().dropna()
trans_data[-5:]| cpi | m1 | tbilrate | unemp | |
|---|---|---|---|---|
| 198 | -0.007904 | 0.045361 | -0.396881 | 0.105361 |
| 199 | -0.021979 | 0.066753 | -2.277267 | 0.139762 |
| 200 | 0.002340 | 0.010286 | 0.606136 | 0.160343 |
| 201 | 0.008419 | 0.037461 | -0.200671 | 0.127339 |
| 202 | 0.008894 | 0.012202 | -0.405465 | 0.042560 |
利用plt.scatter即可轻松绘制一张简单的散布图
plt.scatter(trans_data['m1'],trans_data['unemp'])
plt.title('Cahnges in log %s vs. log %s '%('m1','unemp'))
plt.show()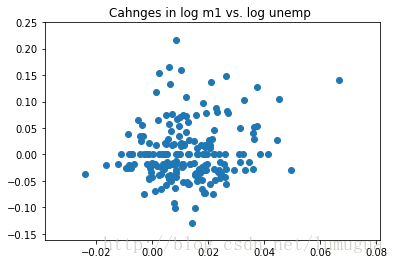
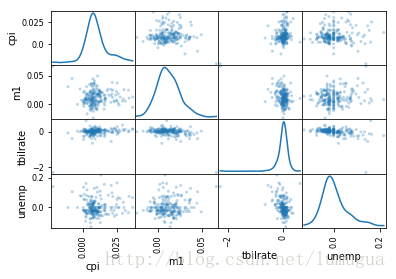
散布图矩阵(scatter plot matrix)。
pandas提供了一个能从DataFrame创建散布图矩阵的scatter_matrix函数。它还支持在对角线上放置各变量的直方图或密度图
pd.scatter_matrix(trans_data,diagonal='kde',alpha=0.3)
plt.show()e:\python\lib\site-packages\ipykernel_launcher.py:1: FutureWarning: pandas.scatter_matrix is deprecated. Use pandas.plotting.scatter_matrix instead
"""Entry point for launching an IPython kernel.
通过练习python matplotlib可视化的知识,学习到对数据绘图的基础知识,了解到matplotlib其他的绘图接口 seaborn和 ggplot。
完善并深入练习还是需要去官方网站去查看相关的用法。
有兴趣可以去官网查看手册:https://matplotlib.org/