1. 超参数的重要性级别:红->桔->紫

2. 如何调整参数
2.1 不要用grid来设置选择,因为不同参数的重要性不同

参数的选择范围从一个比较大的,到后来一个较小的
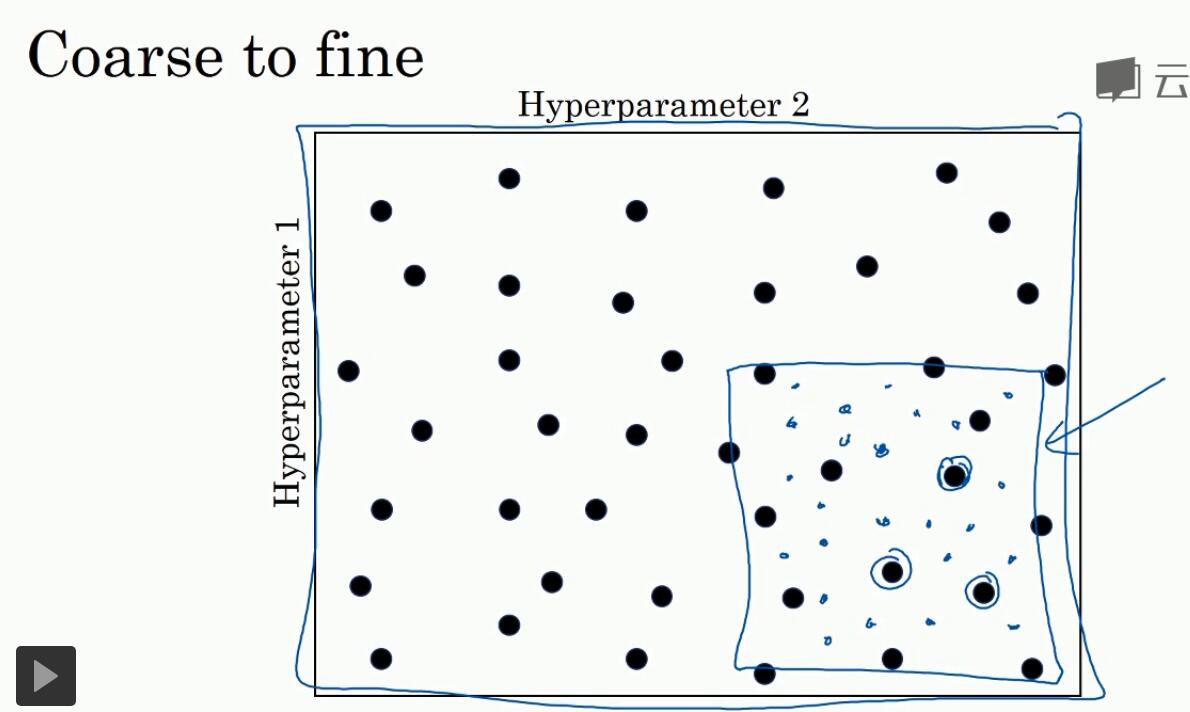
3. 为超参数选择合适的范围
3.1 uniform选择:如每层的节点数或网络层数。但并不是适用于所有超参数
3.2 scale的方法:比如选择学习率
如果在[0.0001,1]之间均匀选择,那么其实90%的数据是来自于[0.1,1],10%是来自[0.0001,0.1]。所以,更合理的方法应该是
把[0.0001,1]转换成[-4,0] (10^-4 = 0.0001),然后在[-4,0]间取样,这样在[0.0001,0.001]和[0.1,1]间取到的数的概率更平均
更一般地,取对数,然后把区间写成[a,b]

3.3. 指数权重均值的调整
- 为什么直接取[0.9,0.999]是均匀分布不好?因为当b越接近1时,它很小的变化都会对1/(1-b)结果造成更大的影响,下面举了个例子
- 把对b的选择,变成对1-b的考虑,然后再进行approximate scale

4. 超参数的实践:pandas VS canviar
因为数据等各种条件变化,需要经常对参数进行调整
第一种是:pandas( babysitting one model)
一次就关注一个model,然后频繁地进行修改
系统比较复杂时选这个
第二种是:canviar(training many models in parrel)
一次可以并行调试多个model
有比较多的计算资源时选这个
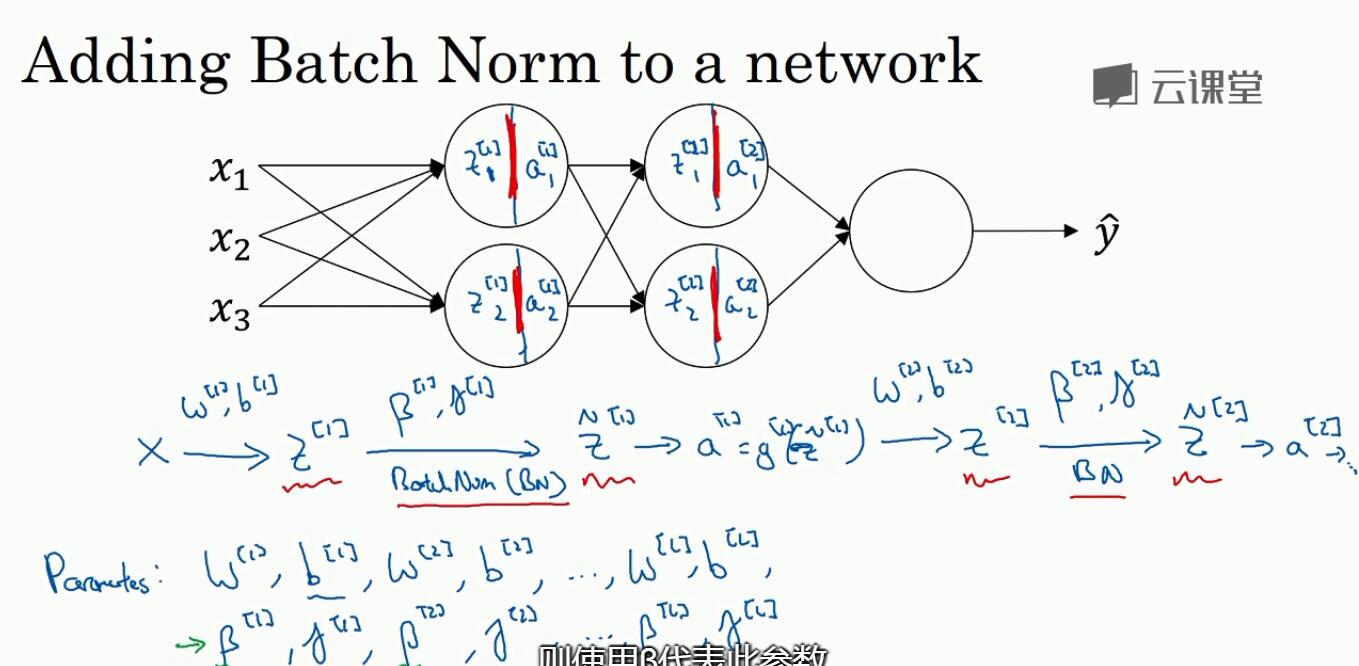
5. 正则化激活函数
对隐藏层的输入进行正则化(而不止是第一个输入层)
实现方式:batch归一化算法。这里默认对z值而不是对a
计算出znorm后,再求一个式子(有两个参数),最后是用z~来计算,而z~的均值和方差可以通过两个参数来控制

6.2 在nn中使用batch-norm 一般框架中会把这个实现好,如tf,只要一个函数即可
6.3 在mini-batch中使用bn:对z值求平均再减去均值,这样b[l]不论是什么值,最后都不会对结果有影响,因此这里可以把b[l]这个参数去掉

6.4

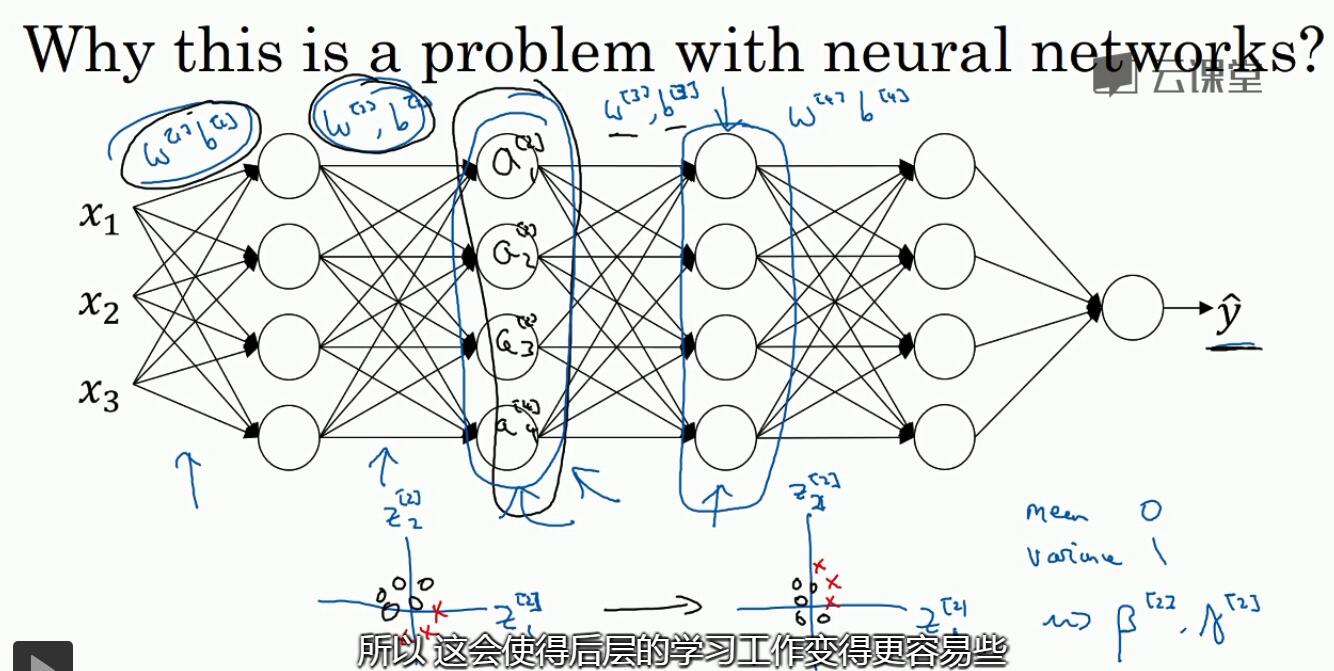
6.5 为什么bn会有用?加速学习
- 归一化:与输入归一化的作用一致
- 就某一层来说,它的上一层对它的输入会发生变化,但是通过归一化,可以使得这个变化被限制在一定的范围内,使得层与层之间可以稍微独立一点
下面这个例子是说对黑色的猫进行训练,然后以有色猫作为输入进行测试(covariance shift)
- 会产生一些噪音,会有正则化的效果?


6.6 在测试中使用bn
训练时,bn是需要在整个mini-batch上执行,但测试时可能不能一次同时执行整个mini-batch(样本数量比较大),因此需要另外的方法进行估算
方法:指数权重平均值

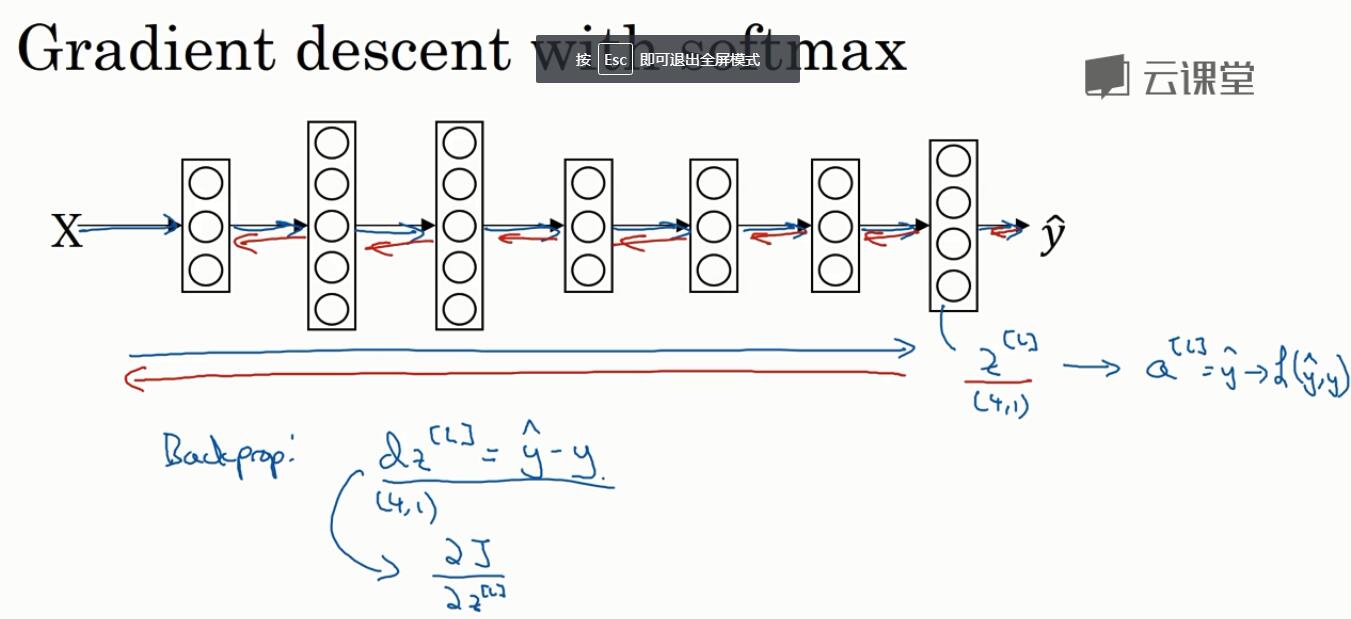
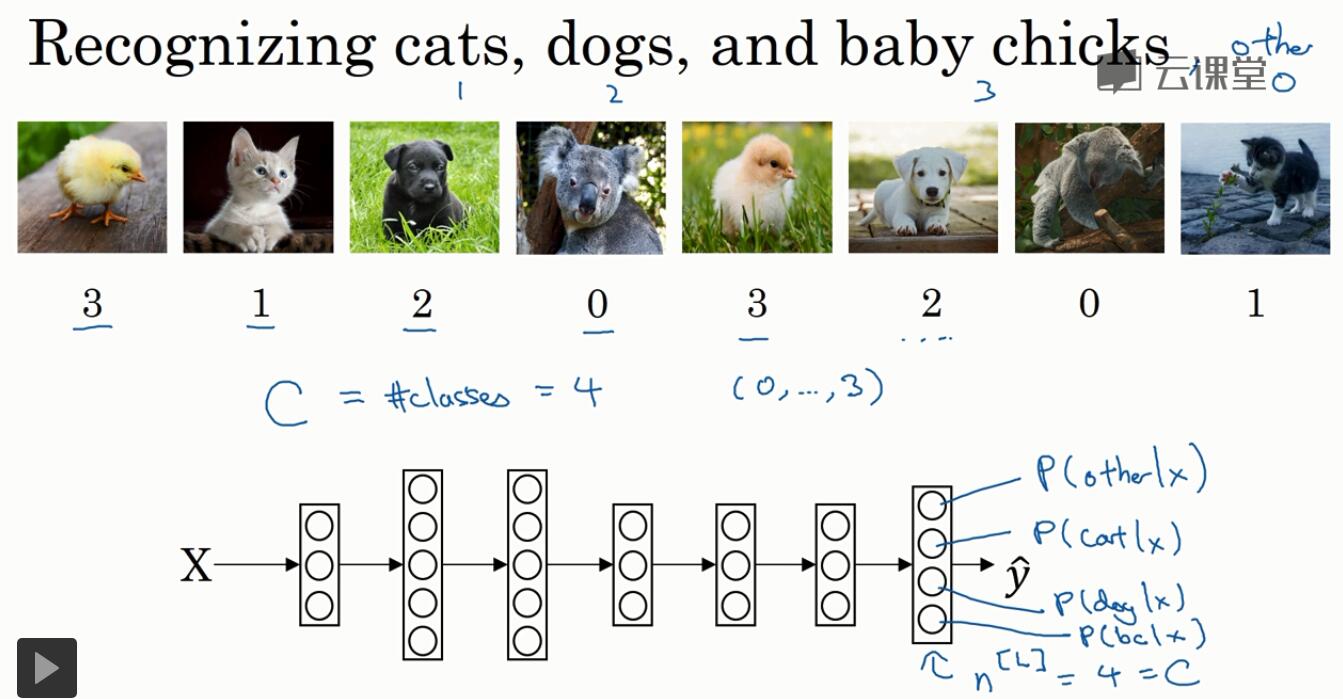
7. softmax回归
分类的类型有多种(二分分类就两种)
使用softmax激活函数:和前面不同的是,它的输入和输出都是向量,前面只是实数;对输出结果归一化,输出的概率之和为1
当只有一个层(没有隐藏层时),任何两个分类间的决策都是线性的

7.2 训练一个softmax网络
相对于hard max,是把最可能的结果标记为1,其它为0, softmax是通过概率大小来体现

损失函数的定义

为什么back是这样的? dz = yhat - y???