这篇博客是对深度学习中比较重要的或者常见的超参数做一个整理笔记。
1:learning rate()
学习率决定了权值更新的速度,在迭代更新权值的过程中,设置过大容易使训练的模型跨过最优值,导致过拟合;设置过小会使梯度下降过程过慢。这个参数是根据经验和不断实验来设置。
2:Weight decay()
为了避免过拟合,必须对目标函数cost function(损失函数一般也叫价值函数)加入一些正则项:,其中
为原目标函数,后边则为L2正则项,是所有参数w的平方和,除以训练集的样本大小N的2倍,
是正则项系数。这里顺便了解一下L2正则项是怎样防止overfitting的。
推导过程:(参考了这位大神博客:https://www.cnblogs.com/alexanderkun/p/6922428.html)
求导:
对w的更新为:,由于
,所以
的效果实际上是减小了w,这也就是权重衰减(weight decay)的由来。当然考虑到后边的导数项,w更新后的值可能增大也可能减小。
但是加入正则项L2有让w减小的效果,为什么w减小能够防止过拟合呢?下边引用知乎上的一个回答:
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。

3:Momentum()
动量的作用是为了在梯度下降中,加快下降的速度,从而使训练迅速收敛。我们知道,在mini-batch SGD法中,梯度为
,其中m为mini-batch中的m个样本,加入momentum之后,
的更新分为两步:

第一步:新建一个动量,计算
第二步:更新权值,
。实际上动量是一个下降过程的累积。
直观解释:如图所示,红色为SGD+Momentum。黑色为SGD。可以看到黑色为典型Hessian矩阵病态的情况,相当于大幅度的徘徊着向最低点前进。
而由于动量积攒了历史的梯度,如点P前一刻的梯度与当前的梯度方向几乎相反。因此原本在P点原本要大幅徘徊的梯度,主要受到前一时刻的影响,而导致在当前时刻的梯度幅度减小。
直观上讲就是,要是当前时刻的梯度与历史时刻梯度方向相似,这种趋势在当前时刻则会加强;要是不同,则当前时刻的梯度方向减弱。
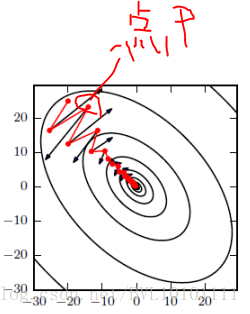
在参数更新过程中,其原理类似:
1) 使网络能更优和更稳定的收敛;
2) 减少振荡过程。
4:RMSprop()
先了解一下AdaGrad算法,AdaGrad的历史梯度为
RMSprop在此基础上增加了一个衰减系数来控制历史信息的获取多少:

根据上图伪代码所示:RMSprop算法对权值的更新有三步:
第一步:新建变量 ,且
第二步:计算更新量,这一步可以看成学习率改变了由
变为了
第三步:计算,
优化效果图如下:

下边了解一下Nesterov(牛顿动量)的RMSProp

5:Adam(其实就是Momentum+RMSProp的结合,然后再修正其偏差)
1.Adam算法可以看做是修正后的Momentum+RMSProp算法
2.动量直接并入梯度一阶矩估计中(指数加权)
3.Adam通常被认为对超参数的选择相当鲁棒
4.学习率建议为0.001
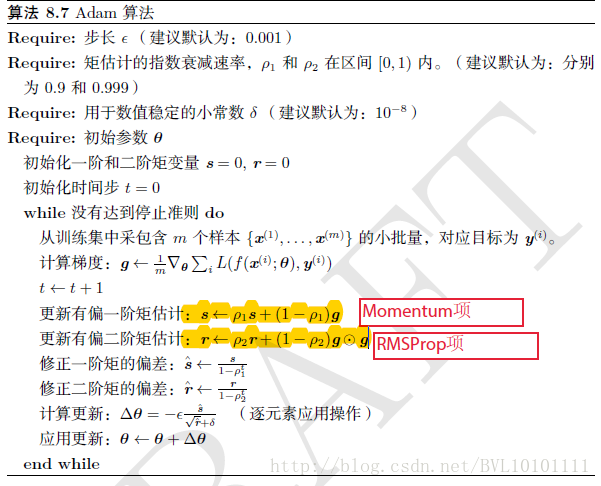
根据上图,Adam算法对quan权值的更新有yi以下六步:
第一步:计算一阶累计梯度,
第二步:计算er二阶累计梯度,
第三步:调节一阶梯度,,其中t为迭代次数
第四步:调节二阶梯度,
第五步:计算更新量,
第六步:计算
因为Adam结合Momentum和RMSprop两种优化算法的优点于一身,所以现在经常用的是Adam优化算法。