1.建立模型(Model)
如下为我们进行某项实验获得的一些实验数据:
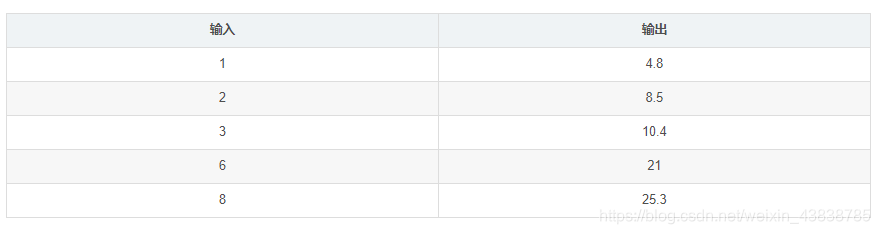
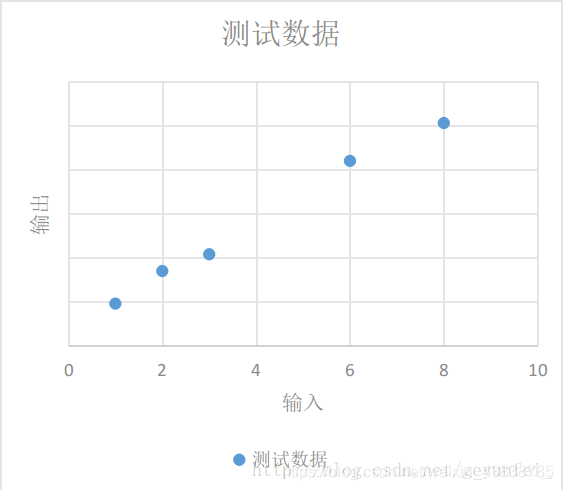
我们将这些数据放到一个二维图上可以看的更直观一些,如下,这些数据在图中表现为一些离散的点
我们需要根据现有的这些数据归纳出一个通用模型,通过这个模型我们可以预测其他的输入值产生的输出值。
如下图,我们选择的模型既可以是红线表示的鬼都看不懂的曲线模型,也可以是蓝线表示的线性模型,在概率统计理论的分析中,这两种模型符合真实模型的概率是一样的。
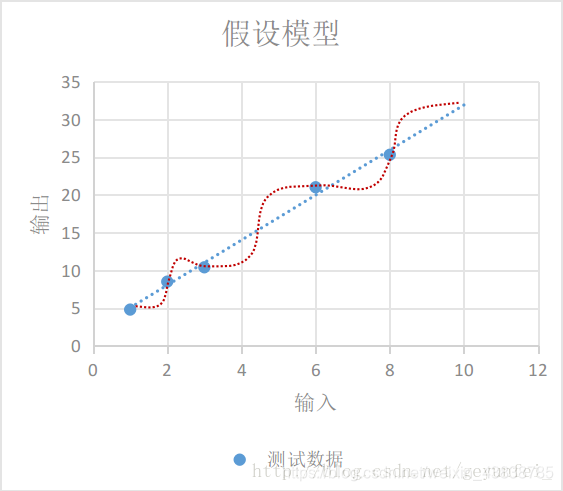
根据 “奥卡姆剃刀原则-若有多个假设与观察一致,则选最简单的那个,蓝线表示的线性模型更符合我们的直观预期。
如果用 x 表示输入, y 表示输出,线性模型可以用下面的方程表示:
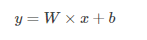
即使我们选择了直线模型,可以选择的模型也会有很多,如下图的三条直线都像是一种比较合理的模型,只是W和b参数不同。这时我们需要设计一个损失模型(loss model),来评估一下哪个模型更合理一些,并找到一个最准确的模型。
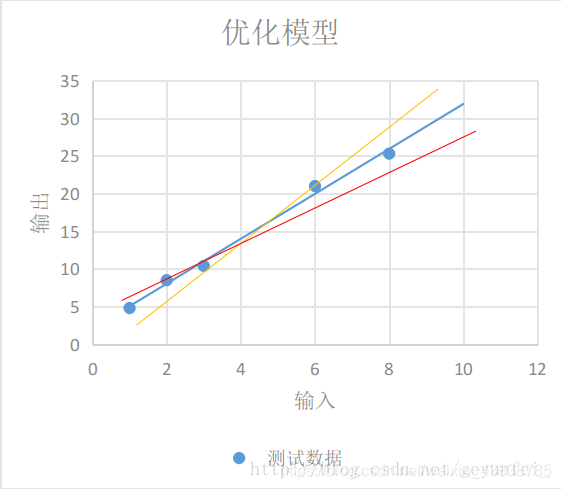
如下图每条黄线代表线性模型计算出来的值与实际输出值之间的差值:
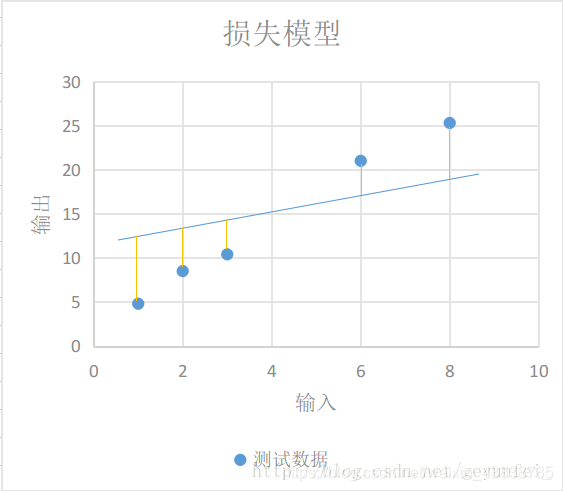
我们用y′表示实验得到的实际输出,用下面的方程表示我们的损失模型:
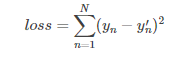
显然,损失模型里得到的loss越小,说明我们的线性模型越准确。
2.使用 TensorFlow 实现模型

import tensorflow as tf
# 创建变量 W 和 b 节点,并设置初始值
W = tf.Variable([.1], dtype=tf.float32)
b = tf.Variable([-.1], dtype=tf.float32)
# 创建 x 节点,用来输入实验中的输入数据
x = tf.placeholder(tf.float32)
# 创建线性模型
linear_model = W*x + b
# 创建 y 节点,用来输入实验中得到的输出数据,用于损失模型计算
y = tf.placeholder(tf.float32)
# 创建损失模型
loss = tf.reduce_sum(tf.square(linear_model - y))
# 创建 Session 用来计算模型
sess = tf.Session()
通过tf.Variable()创建变量 Tensor 时需要设置一个初始值,但这个初始值并不能立即使用,例如上面的代码中,我们使用print(sess.run(W))尝试打印W的值会得到下面提示未初始化的异常
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value Variable
变量 Tensor 需要经过下面的 init 过程后才能使用:
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
这之后再使用print(sess.run(W))打印就可以看到我们之前赋的初始值:
[ 0.1]
变量初始化完之后,我们可以先用上面对W和b设置的初始值0.1和-0.1运行一下我们的线性模型看看结果:
print(sess.run(linear_model, {x: [1, 2, 3, 6, 8]}))
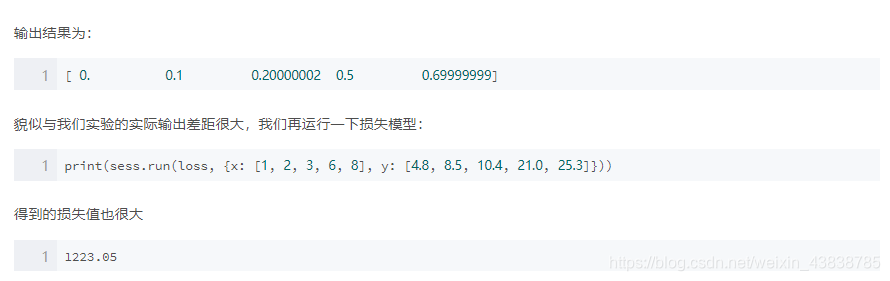
我们可以用tf.assign()对W和b变量重新赋值再检验一下:
# 给 W 和 b 赋新值
fixW = tf.assign(W, [2.])
fixb = tf.assign(b, [1.])
# run 之后新值才会生效
sess.run([fixW, fixb])
# 重新验证损失值
print(sess.run(loss, {x: [1, 2, 3, 6, 8], y: [4.8, 8.5, 10.4, 21.0, 25.3]}))
输出的损失值比之前的小了很多:
159.94
我们需要不断调整变量W和b的值,找到使损失值最小的W和b。这肯定是一个very boring的过程,因此 TensorFlow 提供了训练模型的方法,自动帮我们进行这些繁琐的训练工作。
3.使用 TensorFlow 训练模型
TensorFlow 提供了很多优化算法来帮助我们训练模型。最简单的优化算法是梯度下降(Gradient Descent)算法,它通过不断的改变模型中变量的值,来找到最小损失值。
如下的代码就是使用梯度下降优化算法帮助我们训练模型:
# 创建一个梯度下降优化器,学习率为0.001
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)
# 用两个数组保存训练数据
x_train = [1, 2, 3, 6, 8]
y_train = [4.8, 8.5, 10.4, 21.0, 25.3]
# 训练10000次
for i in range(10000):
sess.run(train, {x: x_train, y: y_train})
# 打印一下训练后的结果
print('W: %s b: %s loss: %s' % (sess.run(W), sess.run(b), sess.run(loss, {x: x_train , y: y_train})))
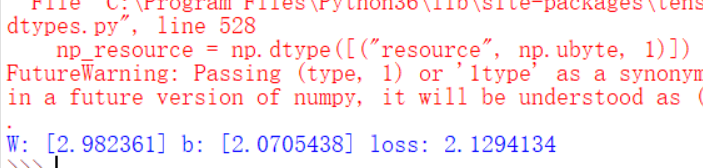
打印出来的训练结果如下,可以看到损失值已经很小了:
W: [ 2.98236108] b: [ 2.07054377] loss: 2.12941
我们整理一下前面的代码,完整的demo代码如下,将下面的代码保存在一个demo.py文件里,通过python3 demo.py执行一下就可以看到训练结果了:
import tensorflow as tf
# 创建变量 W 和 b 节点,并设置初始值
W = tf.Variable([.1], dtype=tf.float32)
b = tf.Variable([-.1], dtype=tf.float32)
# 创建 x 节点,用来输入实验中的输入数据
x = tf.placeholder(tf.float32)
# 创建线性模型
linear_model = W * x + b
# 创建 y 节点,用来输入实验中得到的输出数据,用于损失模型计算
y = tf.placeholder(tf.float32)
# 创建损失模型
loss = tf.reduce_sum(tf.square(linear_model - y))
# 创建 Session 用来计算模型
sess = tf.Session()
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
# 创建一个梯度下降优化器,学习率为0.001
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)
# 用两个数组保存训练数据
x_train = [1, 2, 3, 6, 8]
y_train = [4.8, 8.5, 10.4, 21.0, 25.3]
# 训练10000次
for i in range(10000):
sess.run(train, {x: x_train, y: y_train})
# 打印一下训练后的结果
print('W: %s b: %s loss: %s' % (sess.run(W), sess.run(
b), sess.run(loss, {x: x_train, y: y_train})))
不断调整w和b,10000次之后,学习率为0.01.最后得到了训练结果
