3.4 TensorFlow实现神经网络
使用神经网络解决分类问题可以分为以下四步:
1.提取问题中实体的特征向量作为神经网络的输入
2.定义神经网络的结构,并定义如何从神经网络的输入得到输出(前向传播)
3.通过训练数据来调整神经网络中的参数(反向传播)
4.使用训练好的数据来预测未知的数据
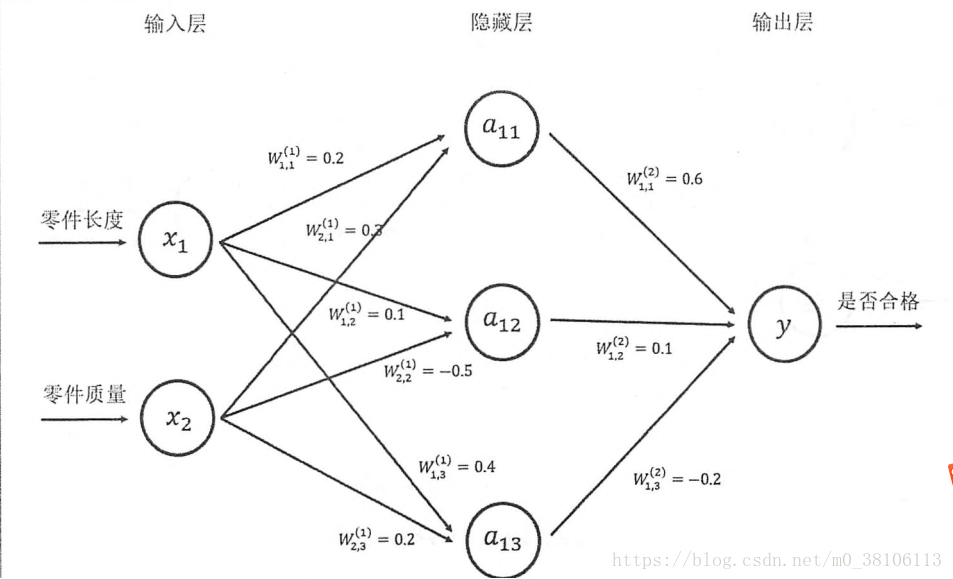
整个过程分需要三部分信息:
第一个部分是神经网络的输入,这个输入就是从实体中获取的特征向量。如上图的x1和x2
第二个部分是神经网络的连接结构。连接结构给出的是上面不同神经元(也可以称为节点)之间输出输入的连接关系
最后一个部分是每个神经元之中的参数,如下:
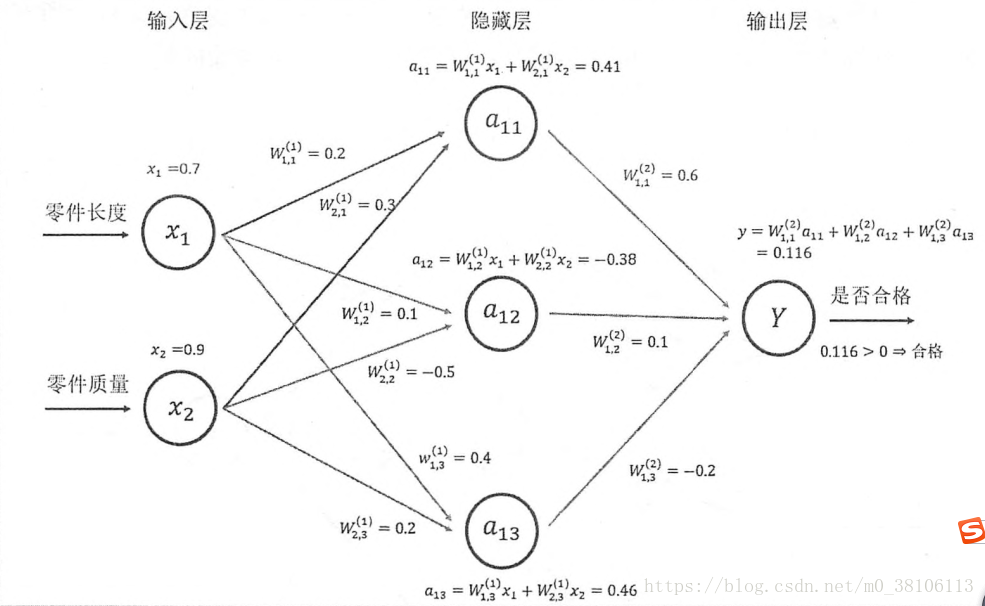
对于上面的计算W*x,可以用下面的方法结果:
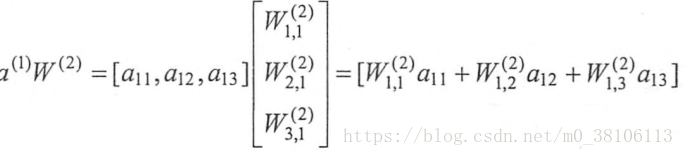
a = tf.matmul(x, w1) # 实现了矩阵的乘法功能
3.4.3 神经网络参数与TensorFlow变量
在TensorFlow中,使用变量(tf.Variable)来保存和更新网络中的参数,需要指定初始值
一般在神经网络中会给参数赋予随机初始值,如下是声明一个2x3矩阵变量的方法:
weights = tf.Variable(tf.random_normal([2, 3], stddev=2))
# [2, 3]制定了变量的维度是一个2x3的矩阵,stddev表示这些随机数的标准差为2,
# 还可以通过mean来指定所有数的均值,不指定的时候默认是0,所以上面weights的均值是0以下是一些其他随机数生成器:

TensorFlow中变量的初始值可以设置成随机数、常数或者是通过其他变量的初始值计算得到 。
以下是一些常量的定义方法:
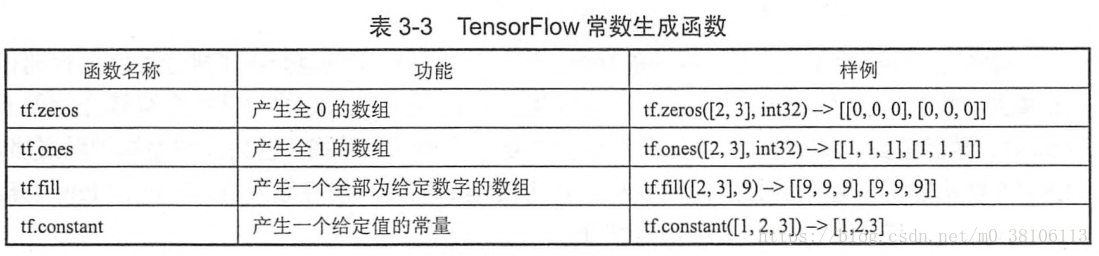
在神经网络中,通常b值通过常数来设置初始值:
b = tf.Variable(tf.zeros([3])) # s生成一个初始值全部为0,长度为3的一维数组通过其他变量的初始值获取新变量的方法如下:
w2 = tf.Variable(weights.initialized_value()) # 与weights是一样的初始值
w3 = tf.Variable(weights.initialized_value() * 2) # 为weights初始值的两倍以下样例介绍如何通过变量实现神经网络参数并实现前向传播的过程
import tensorflow as tf
# 定义w1和w2
# 通过设定seed=1可以确保每次运行这一行代码得到的结果都是一样的,这是常用的手段!记住!
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 定义输入值x,用一个常量来定义
x = tf.constant([[0.7, 0.9]])
# 向前传播
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
sess.run(w1.initializer) # 初始化w1,
# 在变量被定义的时候还没有真正运行初始化,只是定义好计算过程,只有在run()里面才能真正的得到计算结果,给变量赋值
sess.run(w2.initializer) # 初始化w2
print(sess.run(y))
sess.close()
# init = tf.global_variables_initializer() # 设置全局初始化参数
# with tf.Session() as sess: # 打开会话进行计算
# sess.run(init) # 初始化全局,不再需要一个一个参数初始化
# print(sess.run(y)) # 输出[[ 3.95757794]]变量的类型是不可变的,一旦定义了类型float32,就不能再次修改
其次,有些方法是有默认类型的,不能随便定义,发现报类型不匹配错误的时候要注意是不是这个错了
变量的维度则是可以修改的,但是需要设置参数validate_shape=False,如下所示:
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1), name='w1')
w2 = tf.Variable(tf.random_normal([2, 2], stddev=1), name='w2')
# 下面这句会报错维度不匹配:ValuValueError:Shape(2, 3) and (2, 2) are not compatible
# tf.assign(w1, w2) # tf.assign(A, new_number): 这个函数的功能主要是把A的值变为new_number
# 这句不会报错
tf.assign(w1, w2, validate_shape=False)<tf.Tensor 'Assign_1:0' shape=(2, 2) dtype=float32_ref>3.4.4 通过TensorFlow训练神经网络模型
定义计算图中的一个节点位置而不设定节点的值:placeholder()
下面是placeholder()的使用:
import tensorflow as tf
w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 定义placeholder作为数据输入的位置,维度可以不定义
# 但是如果能确定维度,给出维度可以降低错误风险
x = tf.placeholder(tf.float32, shape=(1, 2), name='input')
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 下面一行会报错,因为没有输入数据到x中
# print(sess.run(y))
# 喂入数据,数据是二维的,shape是(1,2)
print(sess.run(y, feed_dict={x: [[0.7, 0.9]]})) # 输出结果为[[ 3.95757794]]feed_dict是一个字典,在字典中需要给出每个placeholder的值,缺少了会报错
前向传播之后,需要定义损失函数来估测真实值和预测值之间的差距,然后通过反向传播来调整参数减小差距
以下代码简单定义了损失函数,并通过TensorFlow定义了方向传播
# 定义损失函数
# reduce_mean表示用最小值来衡量差距
# clip_by_value(y, a, b)函数可以将一个张量y中的数值限制在(a, b)范围之内,避免一些运算错误(如log0是无效的)
# tf.log()对张量中的所有元素依次求对数的功能
cross_entropy = -tf.reduce_mean(yhat * tf.log(tf.clip_by_value(y, le-10, 1.0)))
# 定义学习率
learning_rate = 0.001
# 定义反向传播
# 使用AdamOptimizer表示使Adam算法,输入学习率,然后通过minimize设置要求方向传播接入的节点
train_step = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cross_entropy)最后通过sess.run(train_step)就可以进行整个计算
3.4.5 完整神经网络样例程序
以下是一个简单的二分类神经网络
import tensorflow as tf
from numpy.random import RandomState # 可以生成模拟数据包
# 定义batch的大小
batch_size = 8
# 定义参数
w1 = tf.Variable(tf.random_normal([2,3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3,1], stddev=1, seed=1))
# 定义x和yhat
# 在shape维度上使用None可以方便batch_seize的使用
x = tf.placeholder(tf.float32, shape=(None, 2), name='x_input')
yhat = tf.placeholder(tf.float32, shape=(None, 1), name='y_input')
# 定义向前传播
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 定义损失函数
cross_entropy = - tf.reduce_mean(yhat * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
# 定义反向传播
train_step = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cross_entropy)
# 通过随机数生成一个模拟数据集
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size, 2) # 创建一个shape为[1,2]的,数量共128的数据集X
Y = [[int(x1 + x2 < 1)] for (x1, x2) in X]
#创建一个会话来执行
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
print(sess.run(w1))
print(sess.run(w2))
print('----------------')
# 设定训练的次数
steps = 5000
for i in range(steps):
start = (i * batch_size) % dataset_size
# print(start)
end = min(start + batch_size, dataset_size)
# 开始更新网络
sess.run(train_step, feed_dict={x: X[start: end], yhat: Y[start: end]})
# 每个1000次计算在所有数据上的交叉熵(损失函数的值)并输出
if i % 1000 == 0:
total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, yhat:Y})
print("Afer %d traing steps,所有数据的损失函数为%g" % (i, total_cross_entropy))
print('----------------')
print(sess.run(w1))
print(sess.run(w2))运行结果
[[-0.81131822 1.48459876 0.06532937]
[-2.4427042 0.0992484 0.59122431]]
[[-0.81131822]
[ 1.48459876]
[ 0.06532937]]
----------------
Afer 0 traing steps,所有数据的损失函数为0.0674925
Afer 1000 traing steps,所有数据的损失函数为0.0163385
Afer 2000 traing steps,所有数据的损失函数为0.00907547
Afer 3000 traing steps,所有数据的损失函数为0.00714436
Afer 4000 traing steps,所有数据的损失函数为0.00578471
----------------
[[-1.96182752 2.58235407 1.68203771]
[-3.46817183 1.06982315 2.11788988]]
[[-1.82471502]
[ 2.68546653]
[ 1.41819501]]总结TensorFlow训练神经网络的过程
1.定义神经网络的结构和前向传播的输出结果
2.定义损失函数以及反向传播的优化算法
3.生成会话并开始训练