一、Tensorflow框架
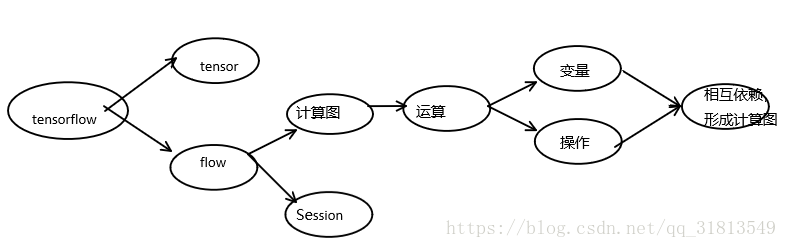
Tensorflow框架的基本组成:数据模型(Tensor),计算模型(计算图),运行模型(Session)
1. 计算图:
Tensorflow中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。系统会自动维护一个默认的计算图,通过tf.get_default_graph()可以获得默认的计算图。可以通过a.graph is tf.get_default_graph()判断张量a所属的图是不是默认图。也可以通过tf.Graph()生成新的计算图。不同计算图中的张量和运算都不会共享。不仅可以隔离张量和计算,而且还可以管理张量和计算的机制和设备。
import tensorflow as tf
g1 = tf.Graph()
with g1.as_default():
v = tf.get_variable("v", [1], initializer = tf.zeros_initializer()) # 设置初始值为0
g2 = tf.Graph()
with g2.as_default():
v = tf.get_variable("v", [1], initializer = tf.ones_initializer()) # 设置初始值为1
with tf.Session(graph = g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
with tf.Session(graph = g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
2. Tensor:
张量,即多维数组(处理类型)。零阶张量——>标量;1阶张量——>向量;n阶张量——>n维数组。张量中并没与保存具体的数字,而是保存的这些数字的计算过程,其中张量包括三种属性:a. 名字(唯一的标识符"node:src_output",其中node表示计算图中的结点,src_output表示该结点的第几个输出(0表示第1个));b. 维度(get_shape函数可以获得维度信息);c. 类型(张量运算必须保持类型一致)。张量的使用主要分为两类:a. 计算图构造阶段,对中间结果的引用;b. 计算图构造完成后,可以通过在会话中使用 sess.run()或者在默认会话中使用Tensor.eval()函数获得张量的取值。
3. 会话(session):
拥有并管理tensorflow此程序运行时的所有资源,计算完成后,需要关闭会话,否则资源泄露。
# 创建一个会话。需要用sess.close()释放资源
sess = tf.Session() print(sess.run(result)) sess.close()
#创建一个可以自动释放资源的会话,with结束之后,自动释放资源
with tf.Session() as sess:
print(sess.run(result))
#创建一个默认会话,方便张量的取值。
sess = tf.InteractiveSession () print(result.eval()) sess.close()
#配置会话,可以配置并行的线程数,GPU分配策略,运算超时等
config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True) sess1 = tf.InteractiveSession(config=config) sess2 = tf.Session(config=config)
二、神经网络的参数和Tensorflow变量:
Tensorflow中变量的作用就是保存和更新神经网络中的参数,变量通过tf.Variable,tf.get_variable,tf.constant函数实现,变量的初始化可以通过两种方式实现:
A:计算图中的初始化
1.可以通过随机数生成函数,来对变量初始化,例如tf.random_normal(正态分布)、tf.truncated_normal(正太分布,但如果随机出来的值偏离平均值超过两个标准差,那么这个数将会被重新随机)、tf.random_uniform(平均分布)、tf.random_gamma(Gamma分布)
2.也可以通过常数来初始化一个变量。例如tf.zeros(产生全零的数组)、tf.ones(产生全1的数组)、tf.fill(产生一个全部为给定数字的数组)、tf.constant(产生一个给定值的常量)。
3. 对于0阶tensor可以直接tf.Variable(0)
B:运算时的初始化
虽然在变量定义时给出了变量初始化的方法,但是这个方法并没有真正运行。在会话中需要将其运行。在会话中运行初始化主要有两种方式:
1.sess.run(w1.initializer) 这种方式的缺点:当变量的数目增多时,或者变量之间存在依赖关系式,单个调用的方案就比较麻烦。
2.可以通过tf.global_variables_initializer函数实现所有变量的初始化
init_op=tf.global_variables_initializer() sess.run(init_op) 优点:不需要对变量一个一个初始化,同时这种方式会自动处理变量之间的依赖关
import tensorflow as tf
# 定义了变量的命名空间,同一命名空间不能同名
with tf.variable_scope("foo"):
# 变量的定义1
# tf.get_variable(name,shape,initializer)
v = tf.get_variable("v", [1], initializer=tf.constant_initializer(1.0))
# 变量的定义2
# tf.Variable(初始化)
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]),name='b')
# 变量的定义3
# 直接定义1阶tensor
a=tf.Variable(0)
# 变量的名字输出1
print(v.name)
# 变量的名字输出2
for vars in tf.trainable_variables():
print(vars)
# 变量的初始化1
# 这种方式的缺点:当变量的数目增多时,或者变量之间存在依赖关系式,单个调用的方案就比较麻烦。
sess.run(v.initializer)
# 变量的初始化2
# 优点:不需要对变量一个一个初始化,同时这种方式会自动处理变量之间的依赖关
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 变量的运行1
sess.run(v)
# 操作的运行1
sess.run(v,feed_back={})