tf.estimator是TensorFlow提供的高级库,提供了很多常用的训练模型,可以简化机器学习中的很多训练过程,如:
运行训练循环
运行评估循环
管理训练数据集
1.评估模型
https://blog.csdn.net/weixin_43838785/article/details/104432177
上一篇文章的demo中我们构建了一个线性模型,通过使用一组实验数据训练我们的线性模型,我们得到了一个自认为损失最小的最优模型,根据训练结果我们的最优模型可以表示为下面的方程:
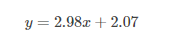
但是这个我们自认为的最优模型是否会一直是最优的?我们需要通过一些新的实验数据来评估(evaluation)模型的泛化性能(generalization performance),如果新的实验数据应用到到这个模型中损失值越小,那么这个模型的泛化性能就越好,反之就越差。下面的demo中我们也会看到怎么评估模型。
2.使用LinearRegressor
前面我们构建了一个线性模型,通过训练得到一个线性回归方程。tf.estimator中也提供了线性回归的训练模型tf.estimator.LinearRegressor,下面的代码就是使用LinearRegressor训练并评估模型的方法:
# 我们会用到NumPy来处理各种训练数据
import numpy as np
import tensorflow as tf
# 创建一个特征向量列表,该特征列表里只有一个特征向量,
# 该特征向量为实数向量,只有一个元素的数组,且该元素名称为 x,
# 我们还可以创建其他更加复杂的特征列表
feature_columns = [tf.feature_column.numeric_column("x", shape=[1])]
# 创建一个LinearRegressor训练器,并传入特征向量列表
estimator = tf.estimator.LinearRegressor(feature_columns=feature_columns)
# 保存训练用的数据
x_train = np.array([1., 2., 3., 6., 8.])
y_train = np.array([4.8, 8.5, 10.4, 21.0, 25.3])
# 保存评估用的数据
x_eavl = np.array([2., 5., 7., 9.])
y_eavl = np.array([7.6, 17.2, 23.6, 28.8])
# 用训练数据创建一个输入模型,用来进行后面的模型训练
# 第一个参数用来作为线性回归模型的输入数据
# 第二个参数用来作为线性回归模型损失模型的输入
# 第三个参数batch_size表示每批训练数据的个数
# 第四个参数num_epochs为epoch的次数,将训练集的所有数据都训练一遍为1次epoch
# 低五个参数shuffle为取训练数据是顺序取还是随机取
train_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=2, num_epochs=None, shuffle=True)
# 再用训练数据创建一个输入模型,用来进行后面的模型评估
train_input_fn_2 = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=2, num_epochs=1000, shuffle=False)
# 用评估数据创建一个输入模型,用来进行后面的模型评估
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_eavl}, y_eavl, batch_size=2, num_epochs=1000, shuffle=False)
# 使用训练数据训练1000次
estimator.train(input_fn=train_input_fn, steps=1000)
# 使用原来训练数据评估一下模型,目的是查看训练的结果
train_metrics = estimator.evaluate(input_fn=train_input_fn_2)
print("train metrics: %r" % train_metrics)
# 使用评估数据评估一下模型,目的是验证模型的泛化性能
eval_metrics = estimator.evaluate(input_fn=eval_input_fn)
print("eval metrics: %s" % eval_metrics)
运行上面的代码输出为:

评估数据的loss比训练数据还要小,说明我们的模型泛化性能很好。
3.自定义Estimator模型
tf.estimator库中提供了很多预定义的训练模型,但是有可能这些训练模型不能满足我们的需求,我们需要使用自己构建的模型。
我们可以通过实现tf.estimator.Estimator的子类来构建我们自己的训练模型,LinearRegressor就是Estimator的一个子类。另外我们也可以只给Estimator基类提供一个model_fn的实现,定义我们自己的模型训练、评估方法以及计算损失的方法。
下面的代码就是使用我们最开始构建的线性模型实现自定义Estimator的实例。
import numpy as np
import tensorflow as tf
# 定义模型训练函数,同时也定义了特征向量
def model_fn(features, labels, mode):
# 构建线性模型
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W * features['x'] + b
# 构建损失模型
loss = tf.reduce_sum(tf.square(y - labels))
# 训练模型子图
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# 通过EstimatorSpec指定我们的训练子图积极损失模型
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=y,
loss=loss,
train_op=train)
# 创建自定义的训练模型
estimator = tf.estimator.Estimator(model_fn=model_fn)
# 后面的训练逻辑与使用LinearRegressor一样
x_train = np.array([1., 2., 3., 6., 8.])
y_train = np.array([4.8, 8.5, 10.4, 21.0, 25.3])
x_eavl = np.array([2., 5., 7., 9.])
y_eavl = np.array([7.6, 17.2, 23.6, 28.8])
train_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=2, num_epochs=None, shuffle=True)
train_input_fn_2 = tf.estimator.inputs.numpy_input_fn(
{"x": x_train}, y_train, batch_size=2, num_epochs=1000, shuffle=False)
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
{"x": x_eavl}, y_eavl, batch_size=2, num_epochs=1000, shuffle=False)
estimator.train(input_fn=train_input_fn, steps=1000)
train_metrics = estimator.evaluate(input_fn=train_input_fn_2)
print("train metrics: %r" % train_metrics)
eval_metrics = estimator.evaluate(input_fn=eval_input_fn)
print("eval metrics: %s" % eval_metrics)
上面代码的输出为
train metrics: {'loss': 0.8984344, 'global_step': 1000}
eval metrics: {'loss': 0.48776609, 'global_step': 1000}
