感谢@铬憨憨师傅提供的题目
感谢ctf show平台提供题目
下载文件后,发现是一张图片。
 且图片大小 比较大,正常图片一般都是1MB以内的,所以猜测可能图片中有其他文件。
且图片大小 比较大,正常图片一般都是1MB以内的,所以猜测可能图片中有其他文件。
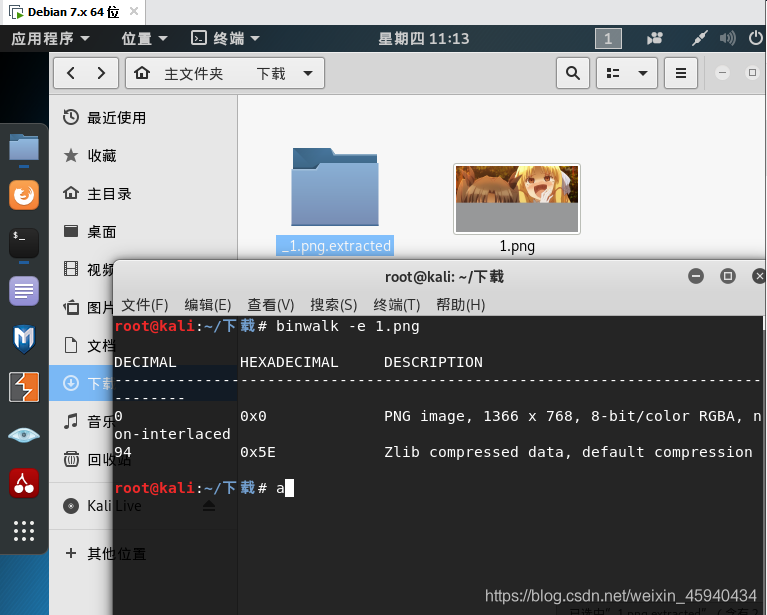
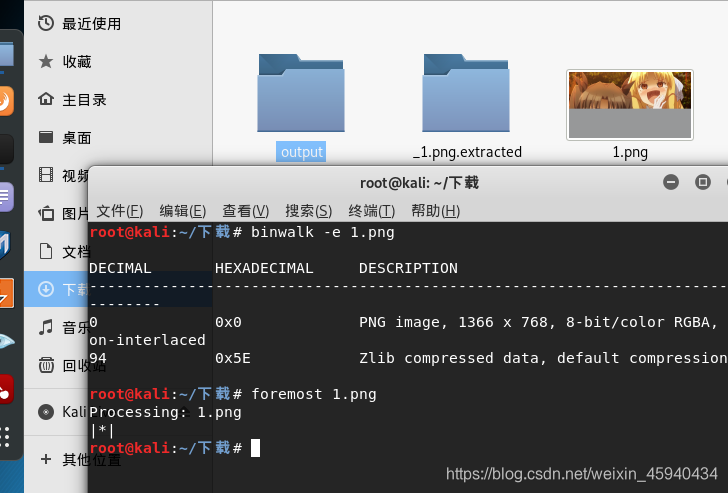
在kali下,尝试binwalk 和 foremost 分离,均没有结果。
于是尝试手动分离文件。
这里推荐一篇文章。
了解常见的文件头 与 文件尾
https://blog.csdn.net/xiangshangbashaonian/article/details/80156865
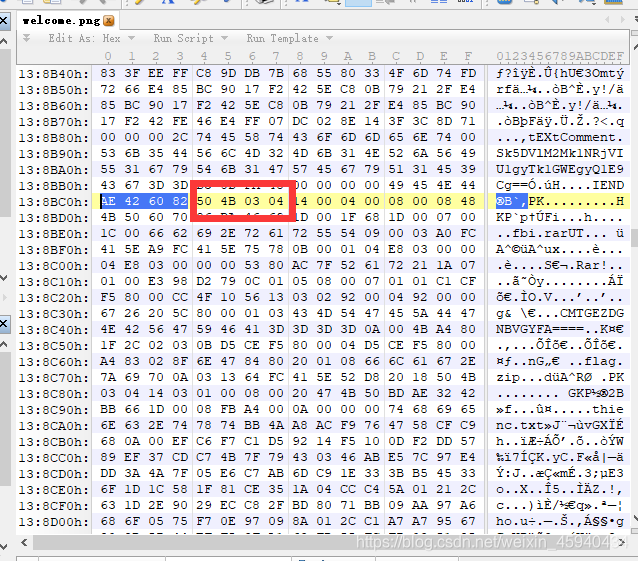
PNG (png), 文件头:89504E47 文件尾:AE 42 60 82
ZIP Archive (zip), 文件头:504B0304
这样就把原本的png,前半部分是png,后半部分是zip压缩包,分离出来了。
1、先分析一下这个分离出来的图片。
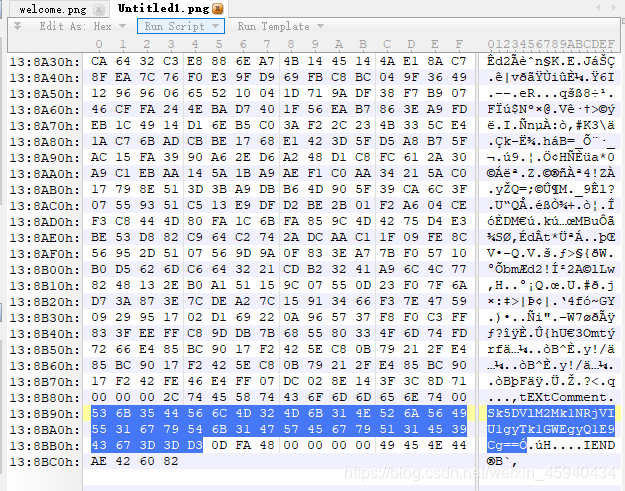
在文件尾发现base64编码,

Sk5DVlM2Mk1NRjVIU1gyTk1GWEgyQ1E9Cg==
base64解码后是
JNCVS62MMF5HSX2NMFXH2CQ=
再进行base32解密
KEY{Lazy_Man}
至于这个有什么用,现在暂时用不到。
2、分析分离后的压缩包
依次解压,在fbi.rar 中发现注释。
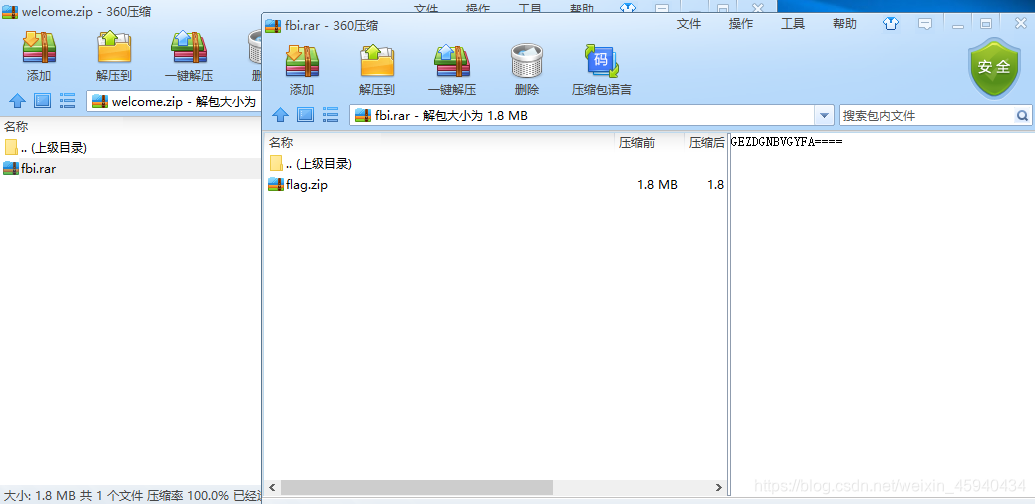
GEZDGNBVGYFA====
base32解密后
123456
解压密码输入123456,得到里面的txt文件。
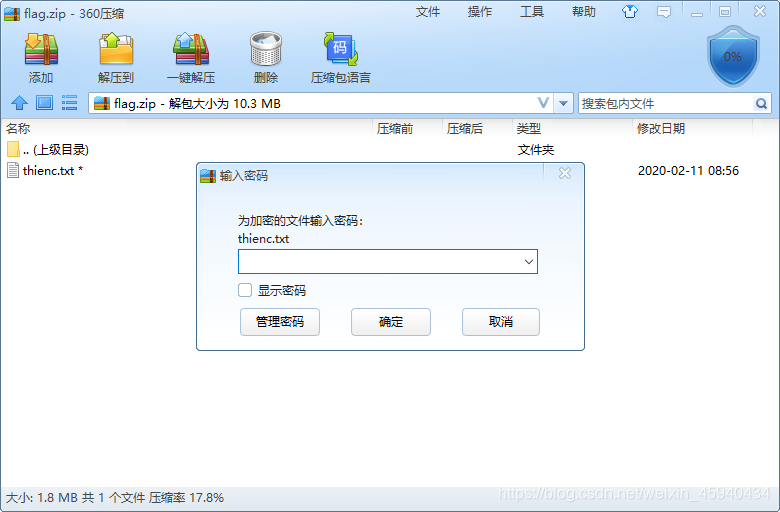
打开发现txt里面的内容,是一堆数字。且3078重复出现。每俩位16进制转字符,发现
3078 就是0x
那么使用脚本,进行批量转换。得到一堆0x 0x的文本。
分析前几个字符串0x37 0x7a,发现37 7a 是7z压缩包的文件头。
那么思路来了:批量删除0x,转换为7z文件。
下面是python的脚本。
import re
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
number = read_file('1.txt')
result = []
result.append(re.findall(r'.{2}', number))
result = result[0]
strings =''
for i in result:
y = bytearray.fromhex(i)
z = str(y)
z= re.findall("b'(.*?)'",z)[0]
strings += z
b= strings.split('0x')
strings=''
for i in b:
if len(i) ==1:
i= '0' + i
strings +=i
with open('test.txt', 'w') as f:
f.write(strings)
把得到的test.txt文件,按16进制转换为7z。发现压缩包有密码。
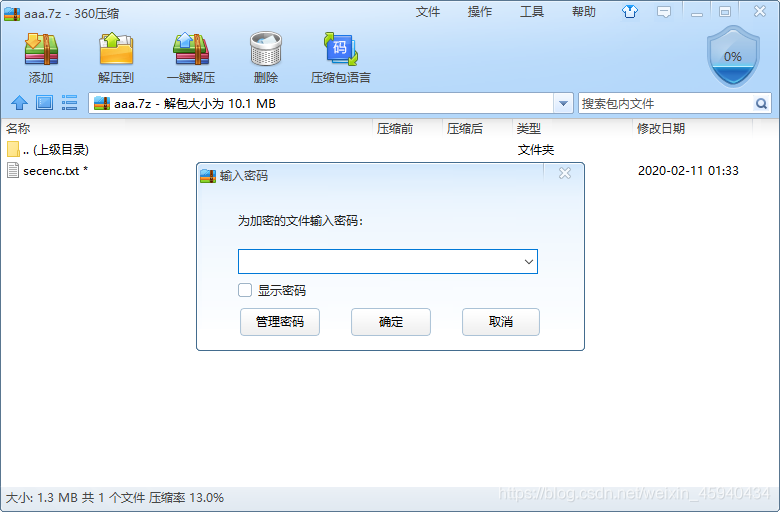
输入我们之前得到的:
KEY{Lazy_Man}
解压出来了里面的文本。
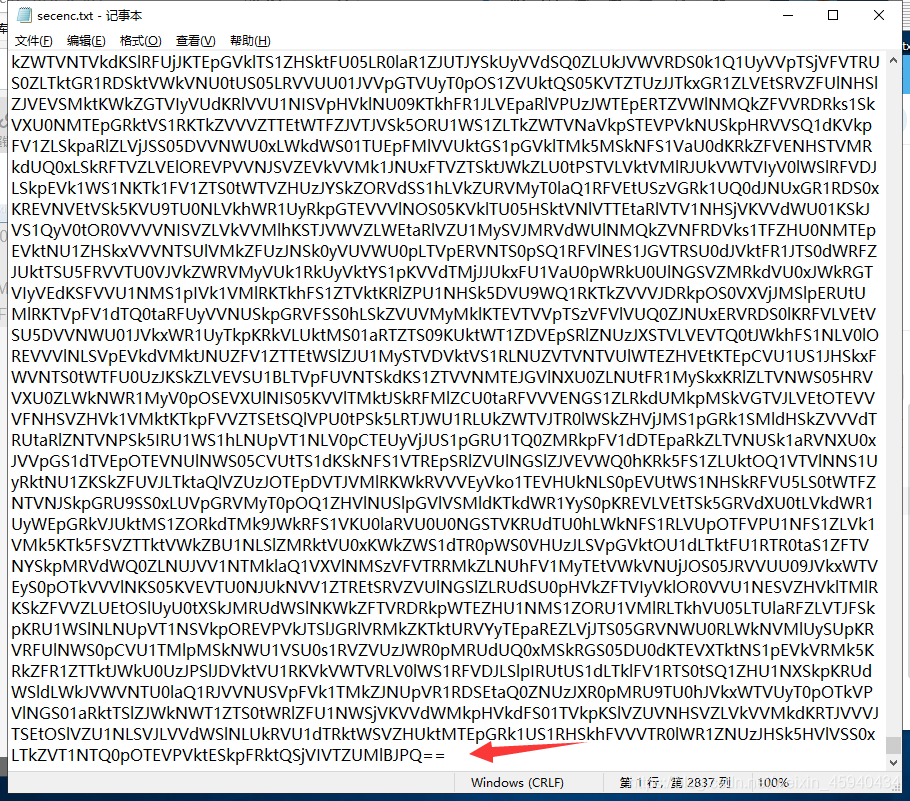
末尾发现==,那么进行base64解密。
解密后发现还是一堆字母,且末尾仍是 =,猜测可能是base循环加密才导致文本这么长,使用python脚本。
base64解密:
import base64
import re
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
url = read_file('test11.txt')
url = re.findall("b'(.*?)'",url)[0]
url = base64.b64decode(url)
with open('test12.txt', 'w') as f:
f.write(str(url))
base32解密:
import base64
import re
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
url = read_file('test15.txt')
url = re.findall("b'(.*?)'",url)[0]
url = base64.b32decode(url)
with open('test16.txt', 'w') as f:
f.write(str(url))
经过作者的测试,这串字符一共 经历了16次的base32 与 base64混合加密。
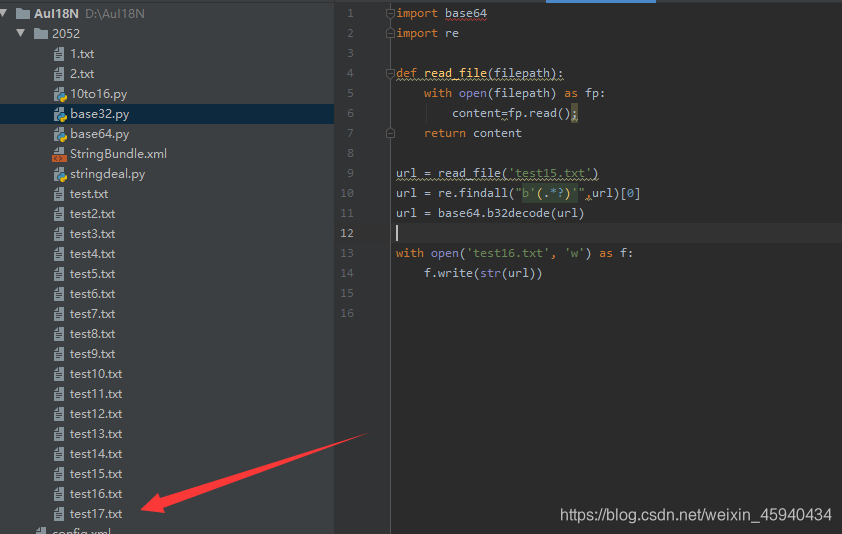
得到的test16.txt 并不是很规范。
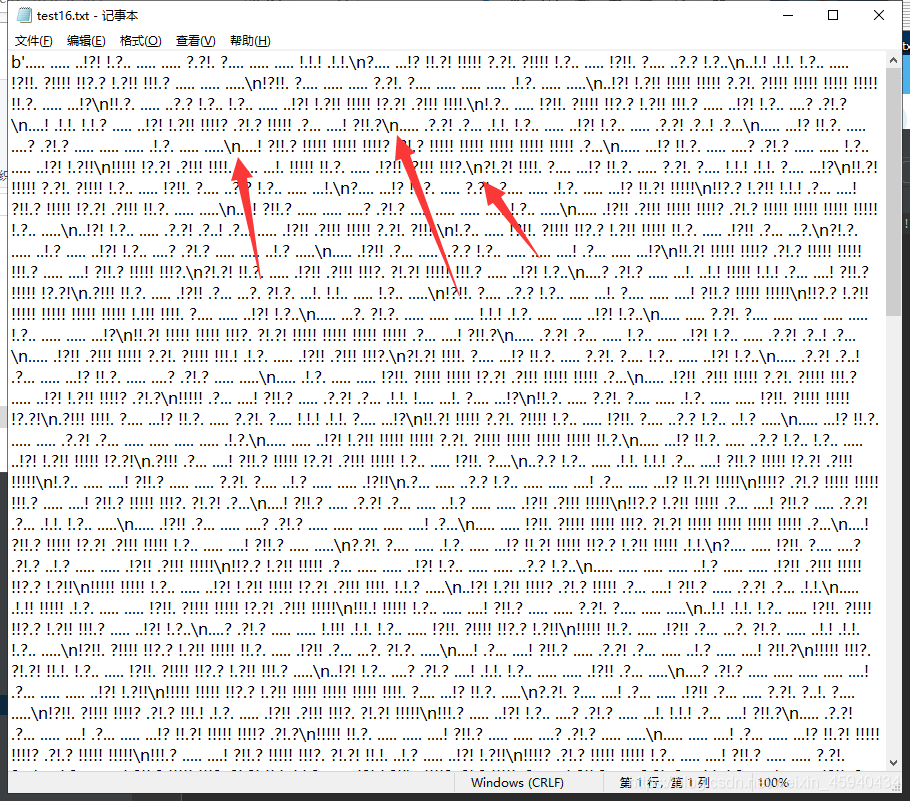
再写一个脚本,把\n 替换为 空格。
脚本如下:
def read_file(filepath):
with open(filepath) as fp:
content=fp.read();
return content
result = read_file('test16.txt')
result = result.replace(r'\n',' ')
with open('test17.txt', 'w') as f:
f.write(result)
得到规范的test17.txt
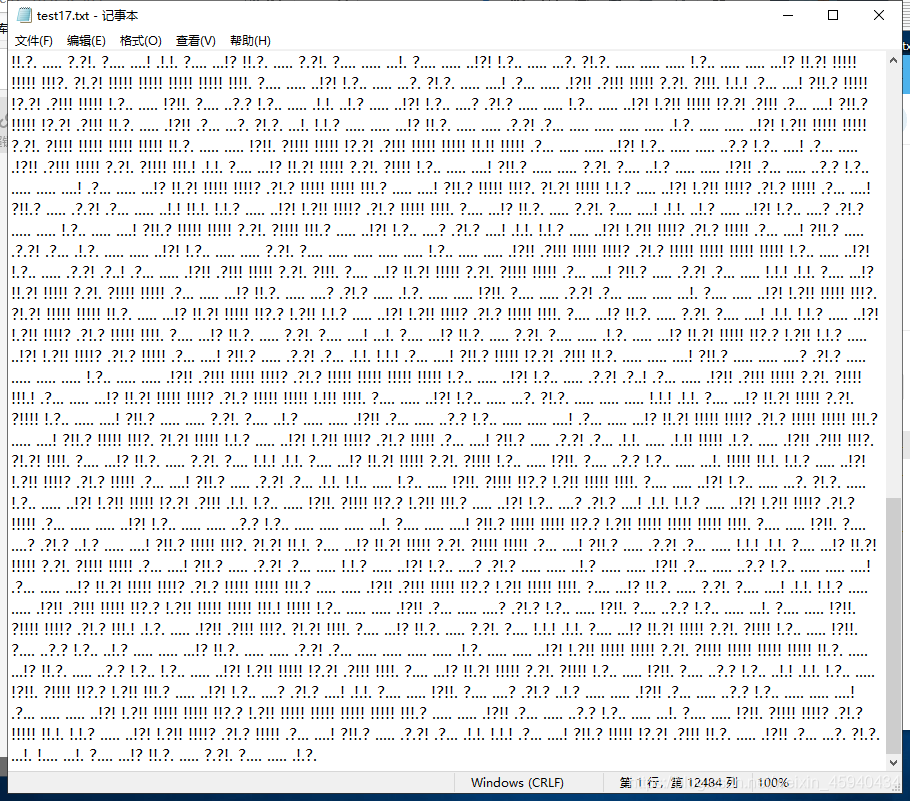
在线brain fuck/Ook! 解密地址:
https://www.splitbrain.org/services/ook
点击ook! to text

点击 brainfuck to text

得到flag。

写文章不容易,点个赞再走吧。