1、通常的CNN网络结构如下图所示

图1
上图网络是自底向上卷积,然后使用最后一层特征图进行预测,像SPP-Net,Fast R-CNN,Faster R-CNN就是采用这种方式,即仅采用网络最后一层的特征。
以VGG16为例子,假如feat_stride=16,表示若原图大小是1000*600,经过网络后最深一层的特征图大小是60*40,可理解为特征图上一像素点映射原图中一个16*16的区域;那原图中有一个小于16*16大小的小物体,是不是就会被忽略掉,检测不到了呢?
结论:早起最常用的网络结构,缺点就是会造成检测小物体的性能急剧下降。
2、图片金字塔生成特征金字塔
鉴于上面的单层检测会丢失细节特征;就会想到利用图像的各个尺度进行训练和测试,比如下图所展示,将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征
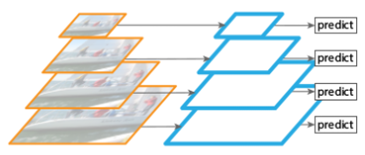
图2
将图片缩放成多个比例,每个比例单独提取特征图进行预测,这样,可以得到比较理想的结果,但是比较耗时,不太适合运用到实际当中。有些算法仅会在测试时候采用图像金字塔。
结论:在机器学习算法中经常使用,例如:HOG+SVM,但是它最大的缺点就是很耗时,很难应用于工程中。
3、多尺度特征融合的方式(特征金字塔)

图3
像SSD(Single Shot Detector)就是采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
结论:目前one-stage目标检测网络最常用的网络结构,对于小目标的检测,需要注意取到的较低层的特征,毕竟底层的特征包含更多的细节信息。
4、FPN(Feature Pyramid Networks)
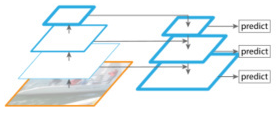
图4
FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。通过高层特征进行上采样和低层特征进行自顶向下的连接,而且每一层都会进行预测。
结论:借鉴了语义分割的思想,将上下层特征进行合并,进一步提升小物体检测率,在Anchor-free的目标检测网络中应用广泛。
5、top-down pyramid w/o lateral
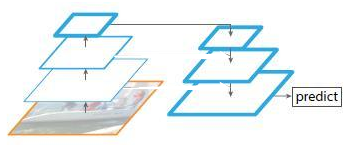
图5
该网络有自顶向下的过程,但是没有横向连接,即向下过程没有融合原来的特征。实验发现这样效果比图1的网络效果更差。结论:效果之所以变差,主要因为目标的location特征在经过多次降采样和上采样过程后变得更加不准确。
6、only finest level
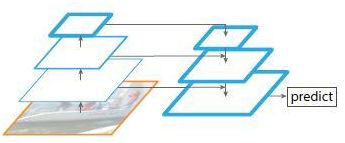
图6
上图带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测,跟FPN的区别是它仅在最后一层预测。
结论:很显然,它没有在多个特征层进行predict,对多尺度目标鲁棒性不够好。
参考链接:https://blog.csdn.net/kk123k/article/details/86566954
