Dense Nested Attention Network for Infrared Small Target Detection
Target Detection)
1.红外小目标的特点与本文的贡献
红外小目标检测的特点
-
目标很小
由于成像距离长,红外目标一般都很小,在图像中从一个像素到几十个像素不等。 -
昏暗
红外目标通常信杂比较低,容易陷入强噪声和杂波背景中。 -
无形状
红外小目标形状特征有限。 -
可变
不同场景下红外目标的大小和形状变化很大。 -
不能使用为通用对象设计的网络
由于红外小目标的尺寸比一般目标小得多,直接应用这些方法进行SIRST检测容易导致深层小目标的丢失。
本文的几个贡献
- 提出了一个DNANet来维护深层的小目标。通过反复的特征融合和增强,可以很好地融合和充分利用小目标的背景信息。
- 提出了密集嵌套交互模块和通道-空间注意模块,实现了逐级特征融合和自适应特征增强。
- 开发了一个红外小目标数据集(即,NUDT-SIRST)。
- 在公共数据集和NUDT数据集上的实验都证明了本论文的方法的优越性能。与现有方法相比,本论文的方法对杂波背景、目标大小和目标形状的变化具有更强的鲁棒性。
2.网络结构解析
DNANet整体网络结构
DNANet的整体网络结构如下图所示。(a)特征提取模块。首先将输入图像送入密集嵌套交互模块(DNIM),实现逐级特征融合。然后,利用通道与空间注意模块(CSAM)对不同语义层次的特征进行自适应增强。(b)特征金字塔融合模块(FPFM)。对增强后的特征进行上采样和拼接,实现多层输出融合。©八连通邻域聚类算法。对分割图进行聚类,最终确定每个目标区域的质心
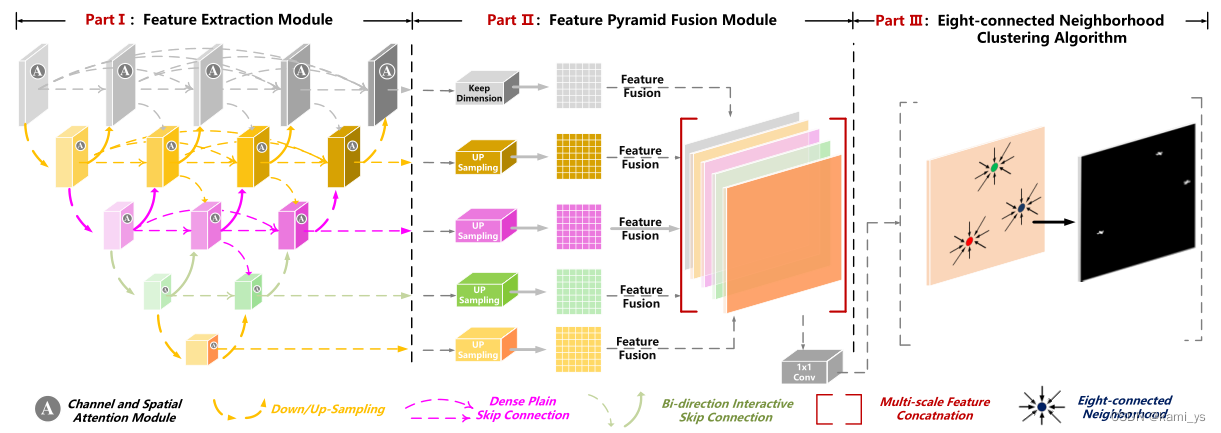
特征提取模块
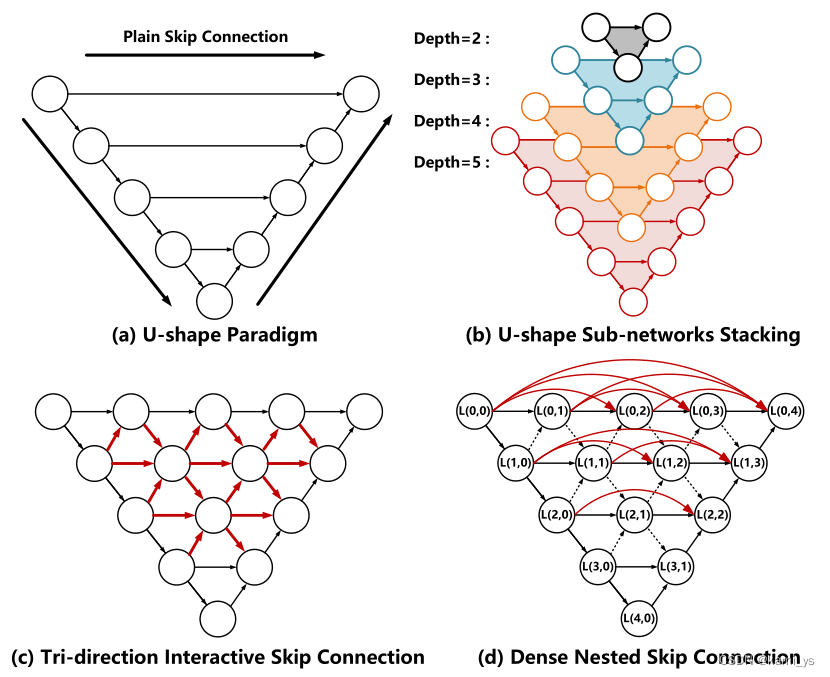
作者从U-Net中得到启发,以U-Net作为基本网络结构,不断增加其网络的层次,以获得更深层的语义信息,获得更大的感受野。考虑到红外小目标的小的特性,作者设计了一个专门的模块来提取深层特征的同时维护深层小目标的表示。
DNIM – The Dense Nested Interactive Module
作者基于上面的思路设计了DNIM模块。作者将多个U型结构堆叠在一起,并在网络中设置了多个节点,将所有节点连接在一起,每个节点可以从自己和相邻层接收特征,实现重复的多层的特征融合。这样可以在深层保持小目标的表示
这里设 I 为DNIM层。取 i t h i^{th} ith(i = 0, 1, 2, …, I)。Li,j表示节点Li,j的输出。其中 i 为沿编码器的第 I 个下采样层,j 为沿平原跳跃路径的稠密块的第 j 个卷积层。当 j = 0时,每个节点只接收到来自密集素跳连接的特征。
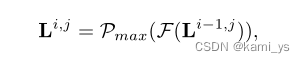
其中F表示多个级联卷积层,Pmax 表示最大池化层。当 j > 0 时,每个节点接收到三个方向的输出,即
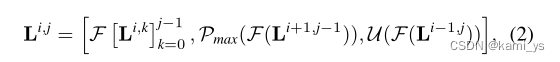
U(·) 表示上采样层
CSAM – Channel and Spatial Attention Module
在DNIM的多层特征融合阶段,采用CSAM进行自适应特征增强,减小语义差距。如下图所示。
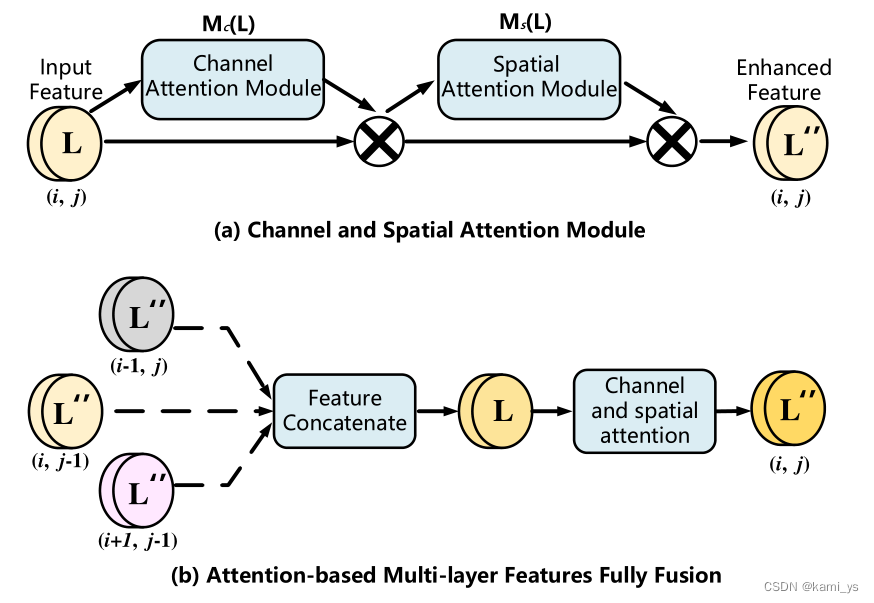
由上图,CSAM由通道注意力和空间注意力这两个级联注意单元组成。节点 L i , j L^{i,j} Li,j依次由一维通道注意力图 Mc∈ R C i × 1 × 1 \R^{Ci×1×1} RCi×1×1 和二维空间注意力图 Ms∈ R 1 × H i × W i \R^{1×Hi×Wi} R1×Hi×Wi 进行处理
通道注意力
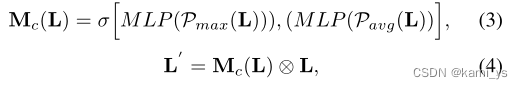
- 特征图分别经过MaxPool和AvgPool,形成两个[ C , 1 , 1 ]的权重向量
- 两个权重向量分别经过同一个MLP网络(由于是同一个网络,因此也可看作是网络参数共享的MLP),映射成每个通道的权重
- 将映射后的权重相加,后接Sigmoid输出
- 将得到的通道权重[ C , 1 , 1 ] 与原特征图[ C , H , W ] 按通道相乘
空间注意力
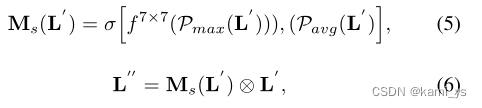
- 特征图分别经过MaxPool和AvgPool,形成两个[ 1 , H , W ]的权重向量,即按通道最大池化和平均池化。通道数从[ C , H , W ] 变为[ 1 , H , W ] ,对同一特征点的所有通道池化。
- 得到的两张特征图进行堆叠,形成[ 2 , H , W ]的特征图空间权重
- 经过一层7×7的卷积层,特征图维度从[ 2 , H , W ]变为[ 1 , H , W ] ,这[ 1 , H , W ] 的特征图表征了特征图上的每个点的重要程度,数值大的更重要
- 将得到的空间权重[ 1 , H , W ] 与原特征图[ C , H , W ] 相乘,即特征图上[ H , W ]的每一个点都赋予了权重
我们可以看成大小为[ H , W ]的特征图,在每一个点( x , y ) , x ∈ ( 0 , H ) , y ∈ ( 0 , W ) 上,都有C个数值,数值表征了特征图该点的重要程度,通过感受野反推回原图像,即表示了该区域的重要程度。我们需要让网络自适应关注需要关注的地方(数值大的地方更易受到关注)
特征金字塔融合模块
对增强后的特征进行上采样和拼接,实现多层输出融合,将包含丰富空间和剖面信息的浅层特征和包含丰富语义信息的深层特征深化连接起来,生成全局鲁棒特征图。
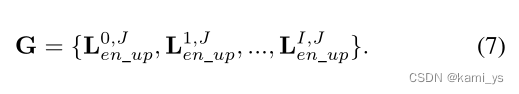
就是将 L 4 , 0 L^{4,0} L4,0、 L 3 , 1 L^{3,1} L3,1、 L 2 , 2 L^{2,2} L2,2、 L 1 , 3 L^{1,3} L1,3、 L 0 , 4 L^{0,4} L0,4 上采样至 [ C i , j C^{i,j} Ci,j, H 0 , 4 H^{0,4} H0,4, W 0 , 4 W^{0,4} W0,4 ],再按通道拼接,最后经过一个残差块得到 [ C 0 , 4 C^{0,4} C0,4, H 0 , 4 H^{0,4} H0,4, W 0 , 4 W^{0,4} W0,4 ] 的输出
八连通邻居聚类模块
在特征金字塔融合模块之后,引入八连通邻域聚类模块对所有像素点进行杂波处理,并计算每个目标的质心。如果特征图g中任意两个像素g(m0,n0), g(m1,n1)在它们的八个邻域内(如公式8)有交集区域,且具有相同的值(0或1)(如公式9),则认为这两个像素处于连通区域。连接区域中的像素属于相同的目标。一旦图像中所有目标确定,质心作为它们的坐标计算。
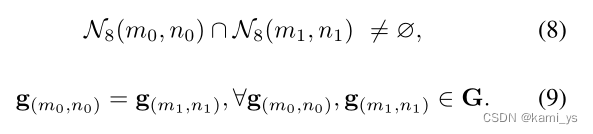
3.损失计算
这里的网络是使用Soft-IoU loss进行训练的。与AGPCNet一致。
关于Soft-IoU loss在AGPCNet有过讲解
https://blog.csdn.net/weixin_33538887/article/details/126401466
4.评价指标
在评价指标方面,这里主要列举了两种常用指标:检测率 Pd 和 虚警率 Fa。
检测率 Pd 一个目标级的评估指标。它度量正确预测的目标数比所有目标数的比率。定义如下:

其中,Tcorrect 和 TAll 分别表示正确预测目标的数量和所有正确目标的数量。如果目标的质心导数小于最大允许导数,则认为这些目标是正确预测的目标。本文设最大质心导数为3。
虚警率Fa 是另一个目标级评估指标。它用于测量错误预测像素占所有图像像素的比例。定义如下:
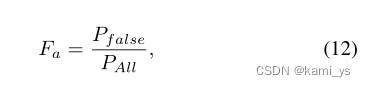
其中,其中 Pfalse 和 PAll 分别表示错误预测像素的个数和所有图像像素的个数。
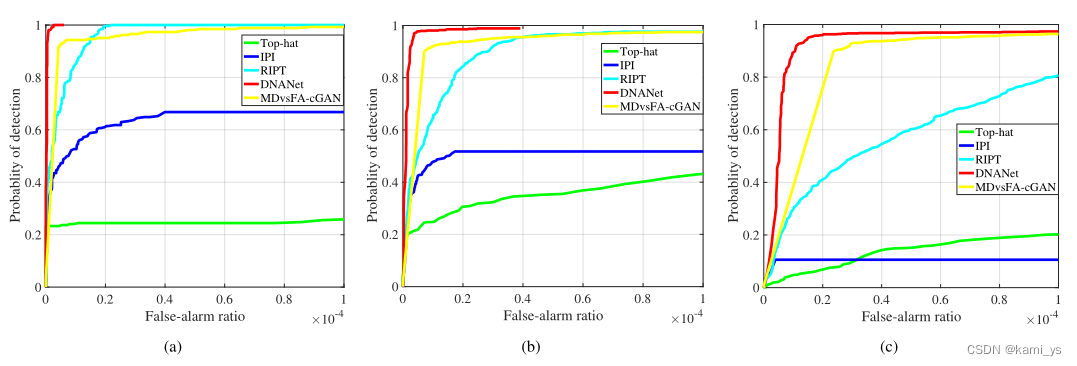
ROC曲线用来描述检测概率(Pd)在不同误报率(Fa)下的变化趋势。
以虚警率为横轴,检测率为纵轴作图,就能够得到一个序列的ROC曲线。ROC序列越凸,代表该检测方法对序列的检测效果越好,即曲线与横轴所围成的面积越大,则检测性能越佳。
5.论文信息
论文下载地址:https://arxiv.org/pdf/2106.00487v3.pdf
论文源码(PyTorch实现): https://github.com/YeRen123455/Infrared-Small-Target-Detection
附有数据集