Attention-Guided Pyramid Context Networks for Infrared Small Target Detection
1.红外小目标方法的不足与本文的亮点
MDvsFA与ACM
-
优点
MDvsFAcGan将生成器分为漏检和虚警两个子任务,提出了一种生成式对抗网络。
ACM侧重于特征融合。它通过编码器-解码器结构获得特征映射,然后根据所包含信息的特征,利用非对称结构将低层语义和深层语义融合,获得更高效的特征表示。
两者分别从生成对抗网络和特征融合的角度来处理检测任务 -
不足
首先,叠卷积运算限制了网络的感知域,而判别目标位置通常需要全局信息。
另一方面,一些方法在获取全局信息时局限于单尺度测量,这也限制了网络的检测精度。
此外,特征融合过程对底层语义和深层语义的单独约束会造成特征不匹配的问题,降低网络的特征表示能力
本文的几个亮点
- 在获取图像时,提出了注意引导上下文块( AGCB)算法,该算法将特征映射划分为多个小块,计算特征的局部相关性,然后通过全局上下文注意(GCA)算法计算小块之间的全局相关性,获得像素之间的全局信息
- 在多尺度特征获取方面,我们提出了上下文金字塔模块(CPM),该模块将多尺度的AGCBs与原始特征映射融合在一起,以获得更准确的特征表示
- 对于特征融合,我们提出了非对称融合模块(AFM),该模块在融合后进行非对称特征滤波以解决不匹配问题。
2.网络结构解析
AGPCNet整体网络结构
下图是原论文中的图2,该图展示了整个AGPCNet网络的结构。通过下图可以看到网络的主体是由两大块结构组成(CPM+AFM),网络的中的CPM模块是由多个不同尺度的AGCB模块组成,而AGCB中又包含了GCA模块,也就是在大的CPM中嵌入了一堆小AGCB和GCA。通过不断的下采样和上采样,使输入图像的大小与输出图像的大小保持一致
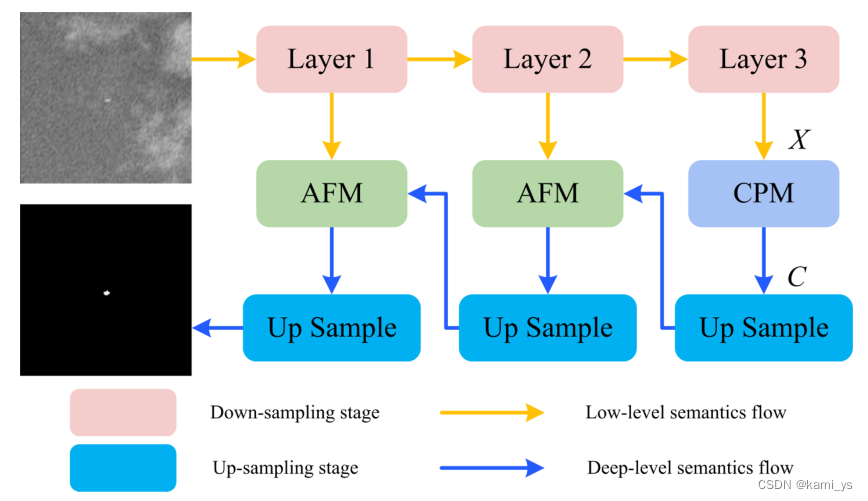
由上图可以得知,AGPCNet可以分成AGCB、CPM、AFM这三个模块进行分析
Attention-Guided Context Block – AGCB
AGCB是网络的一个基本模块。它的上分支和下分支分别表示语义的全局关联和局部关联
局部关联
将输入的 feature map X’ 划分成 s×s 个大小为 w×h 的 patch,其中 w = ceil( W s \frac{W}{s} sW),h = ceil( H s \frac{H}{s} sH)。通过非局部操作计算局部范围内像素的依赖关系,所有patch共享权重。随后,将输出的特征图集中在一起,形成新的局部关联特征图 P∈ R W × H \R^{W×H} RW×H。
这样做的主要目的是将网络的感知场限制在一个局部范围内,利用局部范围内像素之间的依赖关系将属于同一类别的像素聚集起来,计算目标出现的可能性。这样既可以得到局部区域的判别结果,又可以排除patch内部结构噪声对目标的影响。同时,局部关联的计算也可以节省计算资源,加快网络的训练和推理速度。
全局关联
将输入的 feature map X’ ∈ R W × H \R^{W×H} RW×H先通过自适应最大池化提取每个patch的特征,得到 s×s 大小的特征,其中每个像素代表每个patch的特征。然后通过非局部块分析每个patch之间的上下文信息。随后,为了整合通道间的信息,获得更准确的注意引导,将特征通过像素注意力模块,得到引导图 G∈ R s × s \R^{s×s} Rs×s
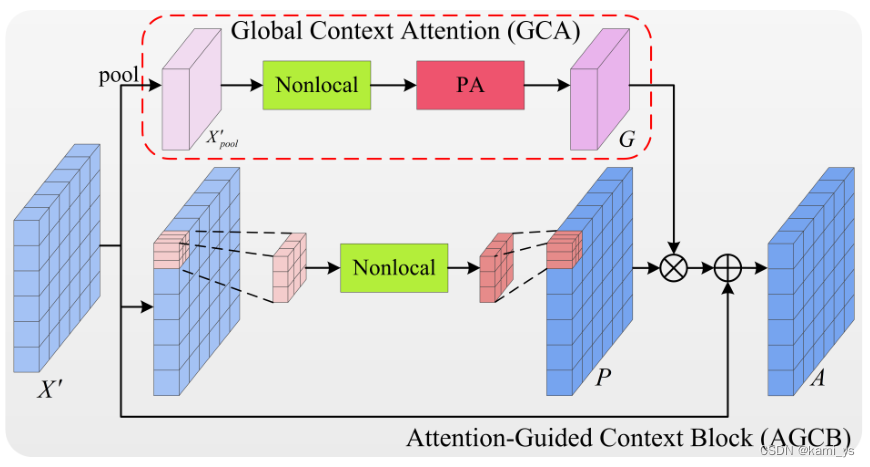
论文中在局部关联特征 P∈ R W × H \R^{W×H} RW×H 上加引导图 G∈ R s × s \R^{s×s} Rs×s 的方式给出了两种解。第一种是Patch-wise GCA,如公式4所示,它通过自适应最大池化下采样得到s × s的特征后,用双线性插值将特征上采样至与输入X’相同大小。然后将G中的每个patch与P中的每个patch进行点乘操作。最后将每个patch与G的对应位置的patch点乘后的结果集中在一起,再经过一层 k=3 padding=1 stride=1的卷积层和BN层后与X’相加得到最后的输出A。
另一种是像素级GCA (Pixel-wise GCA),如公式4所示,它不使用插值上采样到H × W,直接用P中的每个patch与相应位置的像素点点乘。用I(·)表示。
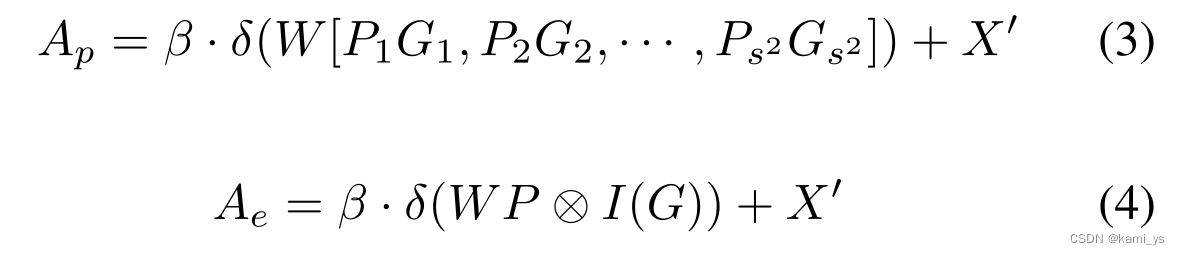
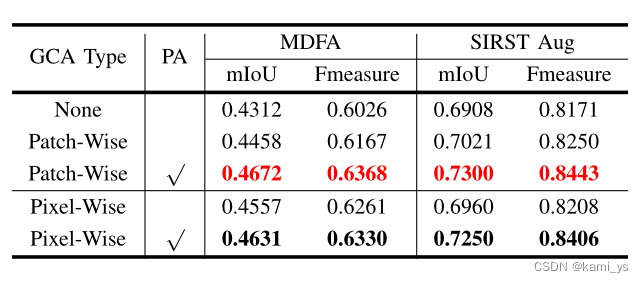
论文中也给出了GCA类型(Patch-Wise和Pixel-Wise)和 PA 对训练效果的影响
AGCB和GCA对应代码
GCA
class GCA_Channel(nn.Module):
def __init__(self, planes, scale, reduce_ratio_nl, att_mode='origin'):
super(GCA_Channel, self).__init__()
assert att_mode in ['origin', 'post']
self.att_mode = att_mode
if att_mode == 'origin':
self.pool = nn.AdaptiveMaxPool2d(scale)
self.non_local_att = NonLocalBlock(planes, reduce_ratio=reduce_ratio_nl)
self.sigmoid = nn.Sigmoid()
elif att_mode == 'post':
self.pool = nn.AdaptiveMaxPool2d(scale)
self.non_local_att = NonLocalBlock(planes, reduce_ratio=1)
self.conv_att = nn.Sequential(
nn.Conv2d(planes, planes // 4, kernel_size=1),
nn.BatchNorm2d(planes // 4),
nn.ReLU(True),
nn.Conv2d(planes // 4, planes, kernel_size=1),
nn.BatchNorm2d(planes),
nn.Sigmoid(),
)
else:
raise NotImplementedError
def forward(self, x):
if self.att_mode == 'origin':
gca = self.pool(x)
gca = self.non_local_att(gca)
gca = self.sigmoid(gca)
elif self.att_mode == 'post':
gca = self.pool(x)
gca = self.non_local_att(gca)
gca = self.conv_att(gca)
else:
raise NotImplementedError
return gca
AGCB
class AGCB_Patch(nn.Module):
def __init__(self, planes, scale=2, reduce_ratio_nl=32, att_mode='origin'):
super(AGCB_Patch, self).__init__()
# patch size w = h,对应的尺度是s
self.scale = scale
self.non_local = NonLocalBlock(planes, reduce_ratio=reduce_ratio_nl)
self.conv = nn.Sequential(
nn.Conv2d(planes, planes, 3, 1, 1),
nn.BatchNorm2d(planes),
# nn.Dropout(0.1)
)
self.relu = nn.ReLU(True)
self.attention = GCA_Channel(planes, scale, reduce_ratio_nl, att_mode=att_mode)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
## long context
gca = self.attention(x)
## single scale non local
batch_size, C, height, width = x.size()
local_x, local_y, attention_ind = [], [], []
step_h, step_w = height // self.scale, width // self.scale # 每个patch的w h
for i in range(self.scale):
for j in range(self.scale):
start_x, start_y = i * step_h, j * step_w # 当前patch的左上坐标
end_x, end_y = min(start_x + step_h, height), min(start_y + step_w, width) # 算出当前的patch最右下坐标
if i == (self.scale - 1):
end_x = height
if j == (self.scale - 1):
end_y = width
local_x += [start_x, end_x]
local_y += [start_y, end_y]
attention_ind += [i, j] # index
index_cnt = 2 * self.scale * self.scale # 所有index
assert len(local_x) == index_cnt
context_list = []
for i in range(0, index_cnt, 2):
block = x[:, :, local_x[i]:local_x[i+1], local_y[i]:local_y[i+1]]
attention = gca[:, :, attention_ind[i], attention_ind[i+1]].view(batch_size, C, 1, 1)
context_list.append(self.non_local(block) * attention)
tmp = []
for i in range(self.scale):
row_tmp = []
for j in range(self.scale):
row_tmp.append(context_list[j + i * self.scale])
tmp.append(torch.cat(row_tmp, 3))
context = torch.cat(tmp, 2)
context = self.conv(context) # W = (W_input + 2p - w_kernel)/s + 1 = (32 + 2 - 3)/1 + 1 = 32
context = self.gamma * context + x
context = self.relu(context)
return context
Context Pyramid Module – CPM
下面介绍论文中提出的用于红外小目标检测的上下文金字塔模块,其结构如图所示。将输入特征图 X 并行输入到多个不同尺度的AGCBs中,经过1 × 1卷积降维,得到的结果用 A = { A S 1 A^{S1} AS1, A S 2 A^{S2} AS2,···} 表示,其中S为尺度向量。然后将多个聚合特征图 { A i A^{i} Ai} 与原始特征图集中在一起。最后,对信道信息进行1 × 1卷积,这是CPM的输出结果,使不同尺度的AGCBs形成上下文金字塔。
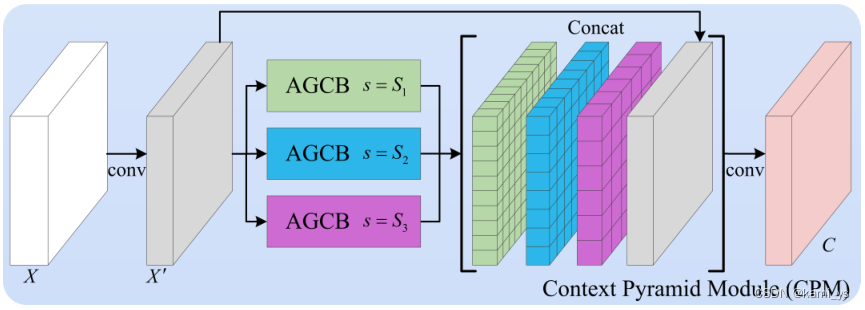
CPM代码
class CPM(nn.Module):
def __init__(self, planes, block_type, scales=(3,5,6,10), reduce_ratios=(4,8), att_mode='origin'):
super(CPM, self).__init__()
assert block_type in ['patch', 'element']
assert att_mode in ['origin', 'post']
self.reduce_test = reduce_ratios
inter_planes = planes // reduce_ratios[0] # 降维比,在CPM和Nonlocal Block中分别有两个维度的降维。在网络中,降维不仅减少了冗余信息,而且大大加快了网络训练推理的速度,但这也可能导致信息的丢失
self.conv1 = nn.Sequential(
nn.Conv2d(planes, inter_planes, kernel_size=1),
nn.BatchNorm2d(inter_planes),
nn.ReLU(True),
)
if block_type == 'patch':
self.scale_list = nn.ModuleList(
[AGCB_Patch(inter_planes, scale=scale, reduce_ratio_nl=reduce_ratios[1], att_mode=att_mode)
for scale in scales])
elif block_type == 'element':
self.scale_list = nn.ModuleList(
[AGCB_Element(inter_planes, scale=scale, reduce_ratio_nl=reduce_ratios[1], att_mode=att_mode)
for scale in scales])
else:
raise NotImplementedError
channels = inter_planes * (len(scales) + 1)
self.conv2 = nn.Sequential(
nn.Conv2d(channels, planes, 1),
nn.BatchNorm2d(planes),
nn.ReLU(True),
)
def forward(self, x):
reduced = self.conv1(x)
blocks = []
for i in range(len(self.scale_list)):
blocks.append(self.scale_list[i](reduced))
out = torch.cat(blocks, 1)
out = torch.cat((reduced, out), 1)
out = self.conv2(out)
return out
Asymmetric Fusion Module – AFM
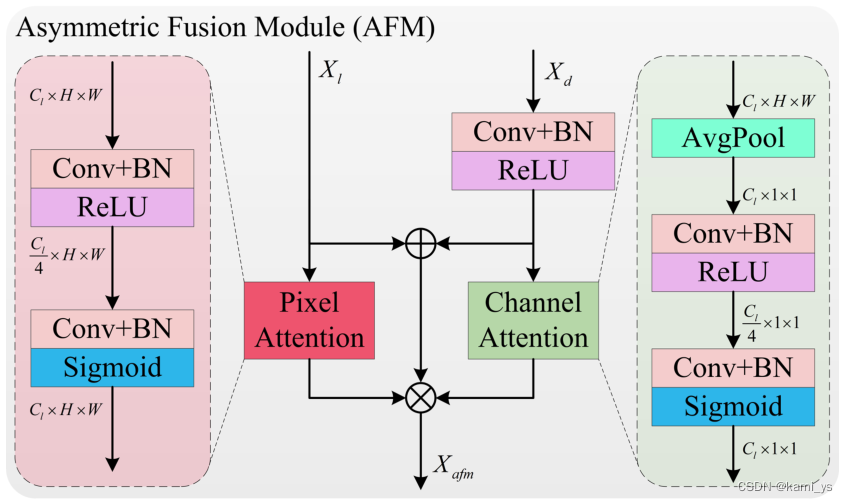
在特征融合方面,论文中借鉴CBAM和ACM,提出了一种新的非对称语义融合模块来融合低级语义和深层语义。如图所示,将低级语义 Xl 和深层语义 Xd 作为输入,我们对它们包含的不同信息类别进行单独处理
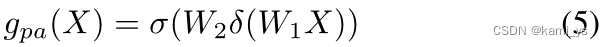
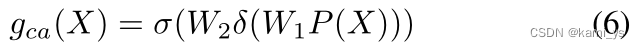
低级语义 Xl 包含大量目标位置信息,使用公式5中的点注意机制。另一方面,深度语义Xd首先使用1 × 1卷积降维,包含更多的信息,使用公式6中的注意机制来选择最重要的通道。将特征直接用求和融合后,分别对gpa和gca进行约束,如式7所示,可以解决单独约束导致特征不匹配的困扰。其中⊗和⊙分别为对应的单元乘法和对应的矢量张量乘法,σ为Sigmoid函数。
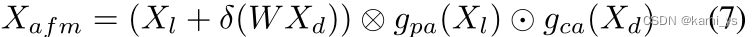
AFM代码
class AsymFusionModule(nn.Module):
def __init__(self, planes_high, planes_low, planes_out):
super(AsymFusionModule, self).__init__()
self.pa = nn.Sequential(
nn.Conv2d(planes_low, planes_low//4, kernel_size=1),
nn.BatchNorm2d(planes_low//4),
nn.ReLU(True),
nn.Conv2d(planes_low//4, planes_low, kernel_size=1),
nn.BatchNorm2d(planes_low),
nn.Sigmoid(),
)
self.plus_conv = nn.Sequential(
nn.Conv2d(planes_high, planes_low, kernel_size=1),
nn.BatchNorm2d(planes_low),
nn.ReLU(True)
)
self.ca = nn.Sequential(
# 通道注意力,需要先通过平均池化下采样
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(planes_low, planes_low//4, kernel_size=1),
nn.BatchNorm2d(planes_low//4),
nn.ReLU(True),
nn.Conv2d(planes_low//4, planes_low, kernel_size=1),
nn.BatchNorm2d(planes_low),
nn.Sigmoid(),
)
self.end_conv = nn.Sequential(
nn.Conv2d(planes_low, planes_out, 3, 1, 1),
nn.BatchNorm2d(planes_out),
nn.ReLU(True),
)
def forward(self, x_high, x_low):
x_high = self.plus_conv(x_high)
pa = self.pa(x_low)
ca = self.ca(x_high)
feat = x_low + x_high
feat = self.end_conv(feat)
feat = feat * ca
feat = feat * pa
return feat
3.损失计算
拟议的FCN的输出是代表像素成为对象一部分的可能性的概率值。因此,我们无法直接从网络的输出中准确测量IoU得分。我们建议使用概率值来近似IoU得分。更正式地说,设V ={1,2,…, N}为训练集中所有图像的所有像素的集合,X为网络(sigmoid层以外)的输出,表示像素在集合V上的概率,Y∈ { 0 , 1 } v {\{0, 1}\}^{v} { 0,1}v 为集合V的ground-truth赋值,其中0表示背景像素,1表示对象像素。那么,IoU计数可以定义为:

式中,I(X)和U(X)可以近似表示为:
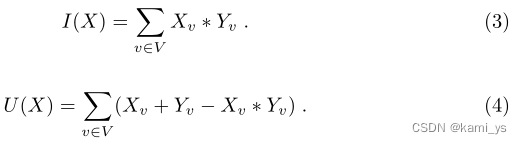
因此,IoU loss LIoU可以定义为:
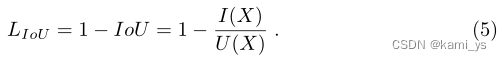
当Yv为1时,某一像素的loss为 1 - X v Y v \frac{Xv}{Yv} YvXv,即为1 - Xv。
4.评价指标
在评价指标方面,作者主要列举了两种常用指标:F-measure和mIoU。
F-measure是结合了Precision和Recall的综合指标,计算公式如下:
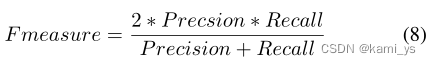
mIoU是mean Intersection over Union 的缩写,计算公式如下:
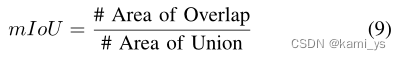
其中,分子为重叠区域,分母为并集区域
5.论文信息
论文下载地址:https://arxiv.org/pdf/2111.03580v1.pdf
论文源码(PyTorch实现):https://github.com/Tianfang-Zhang/AGPCNet
附有数据集