文章目录
- 1.简介
- 2. 高级概述
- 3.构建块
- 4、任务
- 5. 总结其他方法和要求
- 6.挑战与研究之路
- 6.1. Time-evolving graphs(随着时间变化的图)
- 6.2. Bias-variance trade-offs(偏差方差的权衡)
- 6.3. A sensible use of edge information(合理使用边缘信息)
- 6.4、超图学习
- 7.应用
- 7.1、化学与药物设计
- 7.2、社交网络
- 7.3. Natural Language Processing
- 7.4. Security
- 7.5. Spatio-temporal forecasting(时空预测)
- 7.6. Recommender Systems
- 8. Conclusions
- References
论文:A Gentle Introduction to Deep Learning for Graphs
作者:Davide Bacciua, Federico Erricaa, Alessio Michelia, Marco Poddaa
意大利比萨大学计算机科学系
来源:Machine Learning (cs.LG)
论文链接:
https://arxiv.org/pdf/1912.12693.pdf
摘要
图形数据的自适应处理是一个长期存在的研究主题,近来已被整合为深度学习社区的主要兴趣主题。相关研究的数量和广度迅速增加是以缺乏知识的系统化和对早期文献的关注为代价的。这篇文章主要是想作为图的深度学习领域的教程。相对于对最新文献的阐释,它主张对主要概念和体系结构方面进行一致且渐进的介绍,读者可参考其中的可用调查。本文从上至下对问题进行了介绍,介绍了一种基于局部和迭代方法来进行结构化信息处理的图形表示学习的广义公式。它介绍了基本的构建基块,可以将其组合起来设计出新颖而有效的图形神经模型。通过对有趣的研究挑战和在该领域中的应用的讨论来补充方法论的论述。
**关键字:**图的深度学习,图神经网络,结构化数据学习,教程
1.简介
图形是表示各种人工和自然交互过程产生的不同性质数据的强大工具。图数据具有组成性质(是原子信息片段的复合)以及关系性质,因为定义其结构的链接表示链接的实体之间的某种形式的关系。图表允许通过链接方向和标签来表示大量的关联:例如离散关系类型、化学性质和分子键的强度。但最重要的是,图形无处不在。在化学和材料科学中,它们代表化合物的分子结构,蛋白质相互作用和药物相互作用网络,生物和生物化学关联。在社会科学中,网络被广泛用于代表人们的关系,而推荐系统则使用复杂的购买行为。
此类数据的丰富性以及大型存储库的可用性不断提高,引起了人们对能够以自适应方式处理图形的深度学习模型的兴趣激增。与这一总体目标相关的方法论和实践挑战是下面几个。首先,图形的学习模型应该能够适应在大小和拓扑结构上不同的样本。除此之外,关于节点标识和跨多个样本排序的信息很少可用。同时,图是离散的对象,这对可微性有一定的限制,而图的组合性质又阻碍了穷举搜索方法的应用。最后,最一般的图类允许出现循环,这是消息传递和节点访问的复杂性来源。换句话说,处理图形数据在表现形式和计算复杂度方面,以及在矢量数据学习方面,都带来了前所未有的挑战。因此,这是一个很好的开发和测试新的神经网络方法的领域。
尽管最近深度学习社区掀起了一阵热潮,但用于图的神经网络领域已有悠久而巩固的历史,它起源于90年代初,涉及树状结构数据的递归神经网络(RecNN)的开创性工作(请参阅[ [98、32、9]及其中的参考文献)。 RecNN方法后来在自然语言处理应用程序的上下文中重新发现[99,97]。同样,它从有向无环图开始逐渐扩展到更复杂和更丰富的结构[75],为此,它已经得到了通用逼近的保证[44]。递归处理结构还被概率论所利用,首先作为一个纯理论模型[32],然后更实际地通过有效的近似分布[6]。
递归模型共享一个(神经)状态转换系统的思想,该系统遍历结构以计算其嵌入。将这种方法扩展到一般图(循环/非循环、有向/无向)的主要问题是循环的处理,因为在神经递归单元中定义的状态变量之间存在相互依赖关系。最早解决这个问题的模型是Graph Neural Network (GNN)[89]和Neural Network for Graphs (NN4G)[74]。GNN模型是基于一个类似于RecNN的状态转换系统,但是它允许在状态计算中循环。相反,NN4G提出了一种想法,即可以通过利用架构中先前层的表示来管理相互依赖关系。通过这种方式,NN4G用多层架构打破了图数据循环中的递归依赖关系。这些模型为图形处理的两种主要方法奠定了基础,即递归(GNN)方法和前馈(NN4G)方法,从而开创了这一领域。特别是后者现在已经成为主流的方法,在graph convolutional (neural) networks的统称下。(以在2015年前后重新引入上述概念的方法命名[59,42])。
本文从这一历史角度出发,对图的神经网络领域进行了简要介绍,在现代术语中也称为图的深度学习。本文旨在作为具有教程性质的论文,赞成对主要概念和构建块进行有充分依据的,一致的和渐进的介绍,以组装图的神经体系结构。因此,它的目的不是要对有关该主题的最新出版作品进行阐述。这种教程方法的动机是多方面的。一方面,近年来关于图形深度学习的著作激增,这是以一定程度的遗忘(如果不是缺乏适当的引用的话)为代价的,这种遗忘是开创性和综合性著作的结果。因此,存在重新发现已知结果和模型的风险。另一方面,社区开始注意到图的深度学习模型评估中令人不安的趋势[93,25],这需要更多的有原则地对待这个话题。最后,文献[7,15,38,43,111,112,126,127]中开始出现一定数量的调查论文,而对方法的介绍似乎比较缓慢。
本教程采用自顶向下的方法,同时对主要概念和思想的引入保持一个清晰的历史视角。为此,在第2节中,我们首先提供了图形表示学习问题的一个通用公式,介绍并激发了我们将在本文其余部分中遵循的体系结构路线图。我们将特别关注处理信息的局部和迭代处理的方法,因为这些方法更符合神经网络的操作机制。在这方面,我们将较少关注基于谱图方法的全局方法(即假设单个固定邻接矩阵)。然后,在第3节中,我们将介绍可以组装和组合的基本构建块,以创建现代的图数据深度学习体系结构。在本文中,我们将介绍图卷积的概念,如局部邻域聚合函数、注意力的使用、在图上定义的抽样和池操作符,最后我们将讨论计算整个结构嵌入的聚合函数。在第4节中,我们将继续讨论图表示学习中的主要学习任务,以及相关的成本函数和相关的归纳偏差的描述。论文的最后一部分是对其他相关方法和任务的综述(第5部分),并讨论了有趣的研究挑战(第6部分)和应用(第7部分)。
2. 高级概述
我们首先从图的深度学习的高级概述开始。为此,我们首先总结必要的数学符号。然后,讨论文学作品中绝大多数借用的动机和主要思想。
图1:
- (a) 显示了带有无向和有向弧的输入图。
- (b) 我们将无向弧转换为有向弧,以获得可行的图形学习方法输入。
- (c)直观表示节点v1的(开)邻域。
2.1、数学符号
形式上,图 是由一组顶点 (也称为节点)和一组连接两个节点 的有向边(或弧)定义的。我们对无向弧进行建模,即, 形式的弧,有两个方向相反的弧。为了方便,我们有时会使用一对 的另一种表示形式,即g的邻接矩阵,定义为 。
节点可以与特征向量 相关联。同样,有向边可以有自己的特征向量 。在监督学习应用程序中,我们可能希望预测单个节点、一条边或整个图的输出,其ground truth标签分别称为 和 。当从上下文中清除时,我们将省略下标g以避免冗长的表示法。
ground truth:在机器学习里面理解为真值、真实的有效值或者是标准的答案。
在机器学习中,术语”ground truth”指的是用于有监督训练的训练集的分类准确性,主要用于统计模型中验证或推翻某种研究假设。术语也指收集准确客观的数据用于验证的过程。
如果定义了节点上的总顺序,则图形是有序的,否则就是无序的。同样,如果存在从每条边到一组自然数的双射映射,则图是有位置的,否则就是无位置的。在本文的其余部分,我们将假设无序和非位置图。
节点 的邻域定义为以有向弧连接到 的节点集合,即, 关闭,如果它总是包括u和开放,否则。如果弧标A的域是离散的、有限的,即, ,我们用弧标签 as 定义 的邻居子集。图1描述了一个具有无向和有向弧的图(1a),以及它可以表示为机器学习模型输入的方式(1b)。相反,节点 的(开放)邻域如图1c所示。
在下面几节中,我们将使用符号 表示一个通用的 的机制,通过它,信息可以在整个图中传播。此外,我们用 表示在 层的节点 的隐藏状态向量,即节点的内部表示,而 表示在 层与整个图 相关的表示。重要的是,我们使用上下文一词来标识直接或间接影响特定节点表示形式 的节点集。
让我们也介绍一个定义在集合上的函数的通用符号,这是至关重要的,因为我们假设了无序邻域。在整个工作中,我们将使用字母
表示置换不变函数,即具有以下属性的函数:
,其中Z是泛型集合,而
是任意值排列运算符。类似地定义了多集合上的置换不变函数。置换不变函数的示例是集合中所有元素的总和,均值和乘积。当集合是可数的(这是我们在实践中期望的)时,可以通过以下[123]近似任何置换不变函数:
其中
和
是任意的函数。
邻域是集合上的一种基础的拓扑结构。有邻域公理(邻域公理是现代数学拓扑结构的基础概念)、开邻域和闭邻域、去心邻域等的研究著作。
邻域是一个特殊的区间,以点a为中心点任何开区间称为点a的邻域,记作U(a)。
拓扑结构
拓扑空间是一个集合 和其上定义的拓扑结构 组成的二元组 。 的元素 通常称为拓扑空间 的点。而拓扑结构 一词涵盖了开集,闭集,邻域,开核,闭包,导集,滤子等若干概念。从这些概念出发,可以给拓扑空间 作出若干种等价的定义。在教科书中最常见的定义是从开集开始的。
而这里的拓扑结构我觉得直接理解为无向图即可。

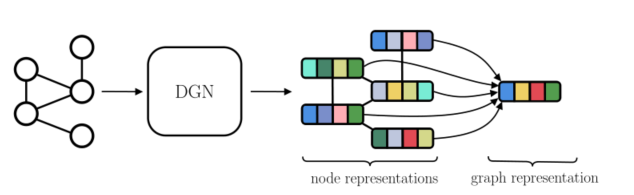
图2:所有图学习方法共享的全局图。 DGN获取输入图并生成节点表示
。可以将这样的表示形式聚合起来以形成单个图形表示形式
。
2.2、动机
由于模型能够自动地从原始数据中提取相关特征来解决问题,因此表示学习在研究领域引起了广泛的兴趣。在这方面,卷积神经网络[61]可能是这种平面数据方法的最佳代表。由于结构化域允许表示比平面数据更清晰的信息,因此考虑实体之间的现有关系至关重要。换句话说,需要对结构进行自适应处理才能最大限度地利用这些附加信息。注意,在图的特定情况下,不能对图的大小或拓扑结构做出任何假设;因此,为了确保它们的普遍适用性,图数据处理方法必须在没有已知的和固定的因果关系的情况下设计。,该机制允许施加适当的顺序来处理图形组件)。
自适应就是在处理和分析过程中,根据处理数据的数据特征自动调整处理方法、处理顺序、处理参数、边界条件或约束条件,使其与所处理数据的统计分布特征、结构特征相适应,以取得最佳的处理效果的过程。
自适应过程是一个不断逼近目标的过程,它所遵循的途径以数学模型表示,称为自适应算法。通常采用基于梯度的算法,其中最小均方误差算法(即LMS算法)尤为常用。
2.3、大图
不管我们关心的训练目标是什么,几乎所有用于图的深度学习方法最终都会产生节点表示(状态) 。在[32]中,这个过程被称为执行图的同构转换。这些表示是并行访问图节点的结果;也就是说,在没有任何特定节点或划分的情况下遍历图。图2所示的整体机制非常有用,因为它允许处理节点、边和图相关的任务;例如,图7表示可以很容易地通过将其节点表示聚合在一起来计算。因此,研究人员和实践者的工作围绕着从图中自动提取相关特征的深度学习模型的定义展开。在本教程中,我们将这些模型称为深图网络(DGNs)。一方面,这个通用术语的目的是消除术语图神经网络(Graph Neural Net- work, GNN)和图卷积网络(Graph Convolutional Network, GCN)之间的歧义,图神经网络(Graph Neural Net- work, GNN)指的是[89],而图卷积网络(Graph Convolutional Network, GCN)指的是[59]。这两个术语在文献中经常被用来表示操作在图数据上的整个类神经网络,在从业者中产生了歧义和混淆。另一方面,我们也使用它作为一个说明性分类的基础(如图3所示),它将作为本节和后续部分讨论的路线图。
为了进一步阐明我们对术语的使用,这里DGN指的是产生最终内部节点表示 的体系结构的子集。可以通过将每一层计算得到的所有内部表示连接起来(进行级联),也可以通过获取最后一层生成的内部表示来获得。因此,术语DGN不包括全局节点聚合机制,也不包括最终分类器或回归器。通过这种方式,我们在体系结构上保持了一个模块化的视图,并且我们可以将任何DGN与一个通过使用最终的内部节点表示作为输入来解决任务的预测器相结合。
我们将DGNs分为三类:深度神经图网络(DNGNs),其中包括受神经结构启发的模型;以图的概率模型为代表的深度贝叶斯图网络;还有深度生成图网络(DGGNs),它包括利用神经模型和概率模型的图的生成方法。这种分类法绝不是方法的严格划分;实际上,我们在本教程中所关注的所有方法都是基于局部关系和迭代处理来将节点上下文分散到整个图中,而不考虑它们的神经或概率性质。
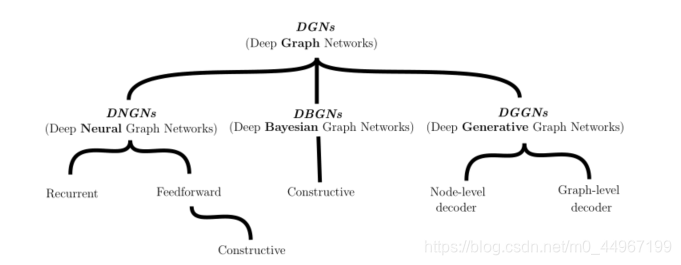 图3:我们将详细讨论的体系结构路线图。
图3:我们将详细讨论的体系结构路线图。
2.4、局部关系和信息的迭代处理
从任意图的总体中学习提出了两个基本问题:第一,对一般图的拓扑结构不作任何假设;第二,结构可能包含循环。现在我们讨论这两点,重点介绍文献中采用的最常见的解决方案。
具有可变拓扑的图。首先,我们需要一种无缝处理大小和形状均变化的图形信息的方法。在文献中,这已经通过构建在节点级别而不是图级别本地工作的模型来解决[98]。换句话说,模型只关心节点及其附近的关系。这回想起卷积模型中图像的局部处理,在该模型中,焦点集中在单个像素及其有限邻居(无论如何定义)上。这种平稳性假设可以极大地减少模型所需的参数数量,因为它们可在所有节点上重复使用(类似于卷积滤波器在像素上的重复使用方式)。此外,它有效且高效地结合了数据集中所有节点和图形的“经验”,以学习单个功能。同时,平稳性假设要求引入一些机制,这些机制也可以从图的全局结构中学习,我们将在下一节中讨论这些机制。
尽管有这些优点,但仅进行局部处理并不能解决可变邻域形状的图的问题。在非位置图的情况下会出现此问题,在这种情况下,没有一致的方式来排序邻域中的节点。在这种情况下,一种常见的解决方案是使用对每个节点的邻居集起作用的置换不变函数。
图4:显示了深度为3的网络在无向图中的上下文传播,其中波浪箭头表示上下文流。具体来说,我们通过从右到左查看图,重点关注最后一层节点 的上下文。很容易看出,节点 在 时的上下文取决于其唯一邻居 在 时的上下文,后者又取决于节点 在 (包括u)处的表示形式。因此,图的几乎所有节点都给出了 的上下文。添加一点个人的理解,这里是否就是说,在考虑 u 和 v 的关系的时候,u 可以通过 v 考虑v 的领域节点的信息。
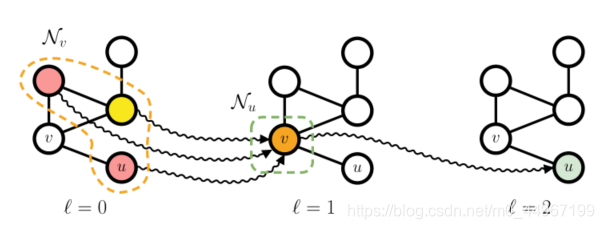
。图的自适应局部处理意味着任何节点的中间状态都是其邻居状态的函数。因此,如果一个图包含一个循环,则需要处理节点状态之间的相互因果关系。解决这个问题的方法是假设一个迭代方案,即 是通过在上一次迭代中计算出的邻居状态定义的。这样,我们就可以近似出属于一个循环的节点之间的相互依赖关系。正如我们将看到的,这样的迭代定义可以很好地并入深层架构。
2.5、语境扩散的三种机制
本节介绍了上下文扩散,它可以说是局部图学习方法中最重要的概念。顾名思义,上下文扩散的目标是在整个图上传播信息。在更广泛环境中为节点提供与其有关的知识,而不是仅限于其直接邻域。这对于节点的更好的表达是很有必要的。
图4描述了通过迭代和局部方法扩散上下文的方式,其中我们显示了节点 u 在迭代 时对图具有的“视图”。首先,我们观察到 u 的邻域。是由节点 v 给出的,因此 u 接收的所有上下文信息都必须经过v。如果从右向左看图片,则根据 定义的 , ,这又是通过聚合三个不同颜色的节点(其中一个是u本身)来计算的。因此,通过迭代计算相邻特征的局部聚合,我们能够间接地向 u 提供有关图中更远的节点的信息。很容易看出迭代次数为3的时候,即 时,足以增加上下文以包括图中的所有节点。换句话说,深度学习技术不仅对自动特征提取有用,而且对上下文扩散也起作用。上下文扩散的正式的描述在[74]中给出。
根据不同的上下文扩散机制,我们可以将大多数深度图学习模型划分为递归、前馈和构造方法。我们现在讨论它们是如何工作的以及它们之间的区别。
。该系列模型将节点信息的迭代处理实现为动态系统。这个家族中最受欢迎的两个代表是图神经网络[89]和图回波状态网络[35]。两种方法都依赖于施加收缩动力学来确保迭代过程的收敛。前者在(监督的)损失函数中施加了这样的约束,而后者则从(未经训练的)储层动力学的收缩性继承了收敛性。门控图神经网络[63]是循环体系结构的另一个示例,与[89]不同,迭代次数是先验固定的,无论是否达到收敛。在[69]中引入了一种基于集体推理的迭代方法,该方法不依赖任何特定的收敛标准。
这一系列模型通过建模节点状态相互依存关系,以迭代的方式来处理图循环。在这些情况下,我们可以将图4的符号 解释为递归状态转换函数的“迭代步骤”,用来计算每一个节点的状态。
。与递归模型不同的是,前馈模型没有利用递归单元在同一层上的迭代扩散机制,而是将多层叠加起来,以构成每一步学习的局部上下文。结果,由循环引起的相互依赖通过不同的参数化层进行管理,不需要约束来确保编码过程的收敛。为了与图4进行对比(这里对应的是一个层的索引),这种组合性会影响每个节点的上下文,上下文随着网络深度的增加而增加,直到包含整个图[74]。
毫不奇怪,这种上下文扩散与CNNs的局部接受域有密切的相似性,这种相似性随着架构中添加更多层而增加。CNNs的不同之处在于,图没有固定的结构,因为邻居的大小可能不同,而且很少给出节点排序。特别是CNNs的局部接受域可以看作是图数据中一个节点的上下文,而平面数据上的卷积算子则回忆起图数据中节点的无序并行访问(即使参数化技术不同)。这就是 这一术语在文献中经常使用的原因。
前馈模型系列因其简单、高效、适用于多种不同的任务而广受欢迎。但是,图的深层网络与其他深层神经网络同样面临与梯度相关的问题,尤其是与整个架构中的“端到端”学习过程相关时。
。我们确定的最后一个族可以看作是前馈模型的特例,其中的训练是逐层进行的。建设性架构的主要好处是,深层网络不会因设计而导致消失/爆炸梯度问题,因此上下文可以更有效的在节点之间传播。在有监督的情况下,这种构造技术甚至可以自动确定完成一项任务所需的层数[26,72]。就像在图4中解释的那样,在图形模型中,该特性也与当前问题所需的上下文相关,因此,无需先验确定它,如[74]所示,其中层的深度和上下文形状已得到正式证明。此外,建设性模型的一个重要特征是它们以“分而治之”的方式解决问题,将任务逐步拆分为更简单的子任务(从而放宽了“端到端”方法)。每一层都有助于解决子问题,随后的层使用此结果逐步解决全局任务。
在这些建设性的方法中,我们提到了图数据的神经网络(NN4G)74,而最近的一种概率变体是上下文图数据马尔科夫模型(CGMM)[3]。
3.构建块
现在我们将注意力转向局部图学习模型的主要组成部分。这些构建块施加的体系结构偏差决定了模型可以计算的表示形式。本节的目的不是给出最全面,最笼统的表述,而在此表述下可以对所有模型进行形式化。相反,它的目的是展示许多体系结构共有的主要组成部分,以及如何将这些组成一个有效的图形学习模型。
3.1、邻域(邻居)聚集
局部图处理的核心是对邻居进行模型聚合以计算隐藏节点表示的方法。我们将遵循图是非位置的普遍假设,因此我们需要使用置换不变函数来实现聚合。为了便于注释,我们将假设在节点 v 上运行的任何函数都可以访问其特征向量 以及入射弧特征向量集 。
以其最一般的形式,可以表示节点 v 在层/步骤 处的邻域聚合如下:
其中 可以打开或关闭。在大多数情况下, 的基本情况对应于不依赖于结构信息的节点特征 的可能的非线性变换。
重要的是要意识到上述公式包括神经和贝叶斯DGN。例如,上面介绍的邻域聚合方案的一个流行的具体实例是图卷积网络[59],它是DNGN,其执行聚合的过程如下:
其中
是归一化图拉普拉斯算子,
是权重矩阵,
是和sigmoid差不多的非线性激活函数。
处理图形边缘。前面提到的一般的邻域聚合方案要求弧是不带属性的,或者包含相同的信息。这种假设通常不成立,因为图中的弧通常包含有关关系性质的附加信息。这些信息可以是离散的(例如,在一个分子中连接两个原子的化学键的类型),也可以是连续的(例如,原子间的节点距离)。因此,我们需要利用弧标签来丰富节点表示的机制。如果 是有限且离散的,我们可以重新定义公式1,以说明不同的弧标签。如下:
其中
是一个可学习的参数,权衡带有标签
的弧的贡献。该公式表示在共享相同弧标记的邻居之间的内部聚集,以及每个可能的弧标记上的外部总和。这样,可以分别了解每个弧形标签的作用。 NN4G [74]和R-GCN [90]实现了等式。明确地参见图2,而CGMM [3]使用开关父母近似[88]来达到相同的目标。与连续弧标签一起使用的更通用的解决方案是重新公式化公式 1作为
其中
可以是任何函数。请注意,我们是如何在邻域(居)聚集中显式引入对弧
的依赖性的:这将根据每个邻居(可能是多维的)弧标记对其贡献进行加权,而不管它是连续的还是离散的。例如,在[38]中,
被实现为输出权重矩阵的神经网络。
注意机制[101]为神经层输入的每个部分分配一个相关性分数,并且它们在与语言相关的任务中得到了普及。当输入为图结构时,我们可以注意聚合函数。这导致邻居的加权平均值,其中各个权重是节点 v 及其邻居 的函数。更正式地讲,我们用以下列方式扩展了等式1的卷积:
其中
是与
相关的注意力得分。通常,此分数与边缘信息无关,因此,边缘处理和注意力是两种截然不同的技术。实际上,图注意力网络(GAT)[102]对其邻居施加注意,但它没有考虑边缘信息。为了计算注意力得分,GAT计算注意力系数
如下:
其中
是共享注意力函数,
是图层权重。注意力系数衡量当前节点
与它的每个邻居
之间的某种形式的相似性。此外,GAT将关注函数a实现为:
其中
是可学习的参数,
表示连接,而LeakyReLU是[68]中提出的非线性激活函数。根据注意力系数,可以通过将它们传递给softmax函数来获得注意力得分:
GAT将该注意方案概括为多头注意,其中将多个注意机制的结果连接在一起或取平均。
图5:采样技术通过选择邻居的一个子集[18]或图形中的一个子集[42]来计算 ,从而影响邻域聚集过程。在这里,红色节点已被随机从节点 的邻域聚合中排除,并且上下文仅通过波浪箭头流动。
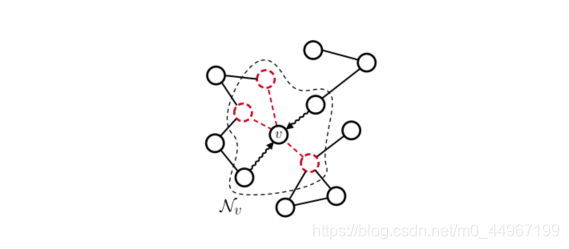
。当图较大且密集时,由于边的数量在 基础上变为二次方,因此无法对每个节点的所有邻居执行聚合。因此,需要替代策略来减少计算负担,并且邻域采样是其中之一。在这种情况下,仅使用邻居的随机子集来计算 。当子集大小固定时,我们还获得了每个图的聚合成本的上限。图5描述了通用采样策略如何在节点级别起作用。在对邻居进行抽样的模型中,我们提到了FastGCN [18]和GraphSAGE [42]。具体地,FastGCN通过重要性采样在每层 上采样 个节点,从而减小了梯度估计器的方差。与FastGCN不同,GraphSAGE考虑邻域函数 将每个节点与给定图中的节点的任何(固定)子集相关联。在实践中,GraphSAGE可以对多个距离的节点进行采样并将其视为节点v的直接邻居。因此,该技术不是在本地学习,而是利用更广泛且异构的邻域,以潜在的性能提升来换取额外(但有界)的计算成本。
3.2、池化
与CNN处理图像类似,可以定义图池化操作符来重新生成经过DGN层的图的维数。图池化主要用于三个目的,即在图中发现重要的群落,在已学习的表示中注入这些知识,以及在大规模结构中降低计算成本。池化机制可以分为两大类:自适应的和拓扑的。前者依赖于一种参数化的(因此是可训练的)池化机制。这种方法的一个显著的例子是DiffPool[120],它使用一个参数化的神经层来学习基于当前节点在前一层的嵌入的聚类。这种聚类是通过一个DNGN层实现的,然后通过一个softmax获得一个软成员矩阵
,该软成员矩阵将节点与集群关联起来
其中
和
是层
的邻接和编码矩阵。然后,使用
矩阵将当前图形重新组合为(理想情况下)尺寸更小的图:
在实践中,由于群集分配很容易保留可微性,因此其应用会产生密集的邻接矩阵。 TopKPool [37]通过学习投影矢量
克服了这一限制,该投影矢量 p 用于使用点积来计算节点嵌入矩阵的投影得分,即
然后,使用这些分数来选择排名最高的节点的索引,并对原始图的矩阵进行切片,以仅保留与顶部节点相对应的条目。通过建立在投影分数上的门控机制,可以使节点选择变得不同。 SAGPool [62]通过使用GCN将得分向量计算为注意力得分来扩展TopKPool [59]。
EdgePool[33]从不同的角度进行操作,以边缘代替节点作为目标。边缘的排序基于一个参数评分函数,该函数输入入射节点的级联嵌入,也就是:
然后将排名最高的边缘及其入射节点收缩到具有适当连接性的单个新节点中,并重复该过程。
另一方面,拓扑池是不自适应的,它通常会影响图本身的结构及其群落。注意,由于不是自适应的,这些机制不需要是可微的,它们的结果不依赖于任务。因此,这些方法可能在多任务场景中可重用。GRACLUS[22]是一种广泛使用的图形划分算法,它利用了一种有效的频谱聚类方法。有趣的是,GRACLUS不需要对邻接矩阵进行特征分解。从类似的角度来看,NMFPool[2]使用邻接矩阵的非负因数分解提供了一个软节点聚类。
图6:我们展示了一个用于图分类的池的例子。每个池化层通过将同一社区的节点聚类在一起使图粗化,使每个组成为粗化图的一个节点。如果我们将图简化为单个节点,我们可以将其解释为表示整个图的超源节点。此时,可以使用标准分类器输出一个图预测 。
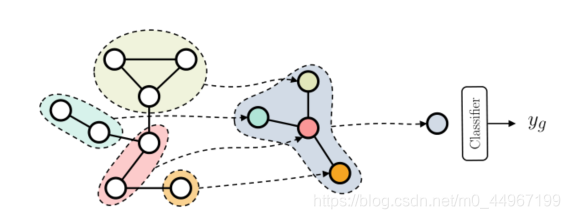
池化方法也可以用来执行图分类,如图6所示。在实践中,通常在几个DNGN层之后应用池化操作,这样上下文信息就可以在图缩小之前扩散。
3.3 、用于图嵌入的节点聚合
如果要执行的任务需要它,例如图分类,则可以汇总节点表示以生成全局图嵌入。再次,由于通常没有关于给定图的大小的假设成立,因此聚合需要是置换不变的。更正式地讲,在
层的图嵌入表示可以按以下方式计算:
常见的设置是将
作为恒等函数,在所有元素的均值、总和、最大值。另一种更复杂的聚合方案借鉴了[123]的工作,其中定义了(多)集上的一组自适应置换不变函数。它将f作为应用到图中所有节点表示的神经网络来实现,
是元素求和,然后是最终的非线性变换。
对于下游任务,有多种方法可以利用不同层上的图嵌入。一种简单的方法是使用最后一层的图嵌入作为整个图的代表。更常见的情况是,将所有中间嵌入连接起来或作为输入提供给置换不变聚合器。[64]的工作提出了一种不同的策略,将所有的中间表示视为一个序列,该模型将最终的图嵌入作为长短时记忆(LSTM)[48]网络对该序列的输出。另一方面,SortPool[125]使用在所有层上获得的节点嵌入连接作为节点着色算法的连续等效,并使用它们来定义整个图上节点的字典顺序。然后选择最上面的有序节点,并将其作为一个序列提供给一维卷积层,该层计算聚合的图形编码。
3.4、总结
在本节中,我们讨论了基于局部和迭代处理的DGN如何利用可用信息。特别是,我们展示了如何聚合邻居并考虑边缘信息。更高级的技术包括注意力,汇集(池化?)和采样,所有这些都可以出于不同的目的而引入。通过组合这些构件,我们可以开发可以扩散上下文信息的新图形处理方法。表1总结了一些代表性模型的邻域聚合方法。图7提供了一个可视示例,说明如何配置和组合不同的构建基块以构建可进行端到端训练的前馈或循环模型。
4、任务
在介绍了生成节点和图表示的主要构建块和最常见的技术之后,我们现在讨论可以处理的不同学习任务。我们将重点介绍无监督、有监督、生成性和对抗性学习任务,对这一领域的研究进行全面综述。
4.1、无监督学习
图7:用于节点和图分类的两种可能的架构(前馈和递归)。在每一层内部,可以应用本节中介绍的注意力和采样技术。应用池化之后,就无法再执行节点分类,这就是为什么用于节点分类的潜在模型可以简单地组合图卷积层的原因。循环体系结构(底部)迭代地应用相同的邻域聚合,直到满足收敛标准为止。
我们的讨论从无监督的图形表示学习开始,因为其中定义的某些损失经常在有监督的生成任务中得到利用。本节的基本原理是提供一种直观的认识,即每一项损失都会对构建纯粹的无监督节点和图表示造成偏差。
。图神经网络使用的最常见的无监督损失是所谓的链接预测或重建损失。该学习目标旨在构建与弧相连的关联节点相似的节点表示,并且可用于链接预测任务。形式上,重构损失可定义为[59]
| Model | Neighborhood Aggregation |
|---|---|
| NN4G [74] | |
| GNN [89] | |
| GraphESN [35] | |
| GCN [59] | |
| GAT [102] | |
| ECC [95] | 1 |
| R-GCN [90] | 2 |
| GraphSAGE [42] | 3 |
| CGMM [3] | 4 |
| GIN [113] |
- 1:
- 2:
- 3:
- 4:
表1:我们报告了文献中存在的一些邻域聚合。在这里,方括号表示串联,并且 , 和 是可学习的参数。请注意,GraphESN假定邻域的最大大小。 GAT的注意力机制由权重 来实现,该权重取决于相关节点。至于GraphSAGE,我们描述了它的均值变体,尽管作者也提出了其他变体。最后,回想一下, 表示GNN[89]中的一个迭代步骤,而不是一个层。
也存在这种损失的概率公式,它用于图形[58]的变分自动编码器,其中解码器只关注结构重建
其中
是sigmoid函数(范围在[0,1])。
重要的是,链路预测损失反映了以下假设:相邻节点应与同一类别/社区相关联,这也被称为同形[69]。从这个意义上讲,这种无监督的损失可以看作是与其他有监督的损失函数组合的正则化器。在所有满足同构假设的任务中,我们希望该损失函数会有所帮助。
。当目标是构建反映相邻状态分布的无监督表示时,将采用不同的方法。在这种情况下,概率模型可能会有所帮助。的确,我们可以计算出节点u具有某个标签的可能性,这个标签是根据邻近的信息确定的。这种可能性可以通过已知的无监督概率学习方法最大化。CGMM[3]给出了这种损失的一个例子,CGMM[3]将深度网络构建为简单贝叶斯网络的堆栈。每一层使下列可能性最大化:
其中
是与节点
关联的
状态的分类潜在变量,
是迄今为止计算的相邻状态集合。另一方面,有一些混合方法可以结合变分近似和DNGN来最大化难处理的可能性[83,58]。
互信息。另一种生成节点表示的方法侧重于图对之间的局部互信息最大化。特别是(DGI)[103]使用损坏函数来生成图 的失真版本,称为 。然后,训练一个鉴别器来区分这两个图,通过使用在节点和图表示上的双线性评分。这种无监督方法需要每次手动定义一个破坏函数,例如,在图中注入随机的结构噪声,因此它会对学习过程造成偏差。
。在使用自适应池方法时,鼓励模型将每个节点分配到单个社区是很有用的。实际上,自适应池可以很容易地将节点u的贡献分散到多个社区,这导致了信息量较低的社区。熵损失[120]就是为了解决这个问题而提出的。形式上,如果我们用
定义软聚类分配矩阵(3.2节,其中C是池化层的聚类数,熵损失计算如下
其中
是熵,
是与节点
群集分配关联的行。请注意,从实际的角度来看,设计一种不产生密集表示的可微分池方法仍然具有挑战性。但是,鼓励对节点进行一站式社区分配可以增强对所学集群的视觉解释,并且它可以充当强制实施良好分隔的社区的规则化器。
4.2、监督学习
将监督图学习任务分为节点学习任务、图分类学习任务和图回归学习任务。一旦学习了节点或图的表示,预测步骤就与标准的向量机器学习没有区别,常见的损失函数是分类的交叉熵/负对数似然和回归的均方误差。
。正如术语所示,节点分类的目标是为图中的每个节点分配正确的目标标签。可以有两种不同的设置:归纳节点分类(包括对属于未见图的节点进行分类)和转换节点分类(只需要学习一个图,并且只需要对一小部分节点进行分类)。需要注意的是,节点分类的基准测试结果受到了实验设置的严重影响;这个问题后来在严格的设置下通过重新评估最先进的体系结构得到了解决[93]。
。要解决图分类和回归任务,首先必须应用24节3.3中讨论的节点聚合技术。获得单个图形表示后,可以通过标准的机器学习技术直接进行分类或回归。与节点分类类似,图分类字段遭受模棱两可,不可复制和有缺陷的实验程序的困扰,这在研究界引起了极大的混乱。然而,最近,已经提出了对一致数量的数据集[25]进行最新模型的严格重新评估,旨在抵消这一令人担忧的趋势。
4.3、生成学习
与以前的任务相比,学习如何从可用的样本数据集生成图形无疑是一项更复杂的工作。要对图g进行采样,必须能够访问底层的生成分布 。然而,由于图形结构是离散的、组合的和可变大小的,基于梯度的方法来学习数据的边际概率就不那么适用了。因此,生成过程取决于一个图形或一组节点的潜在表示,从这个潜在代表中可以解码实际的结构。现在我们介绍两种最流行的DGGNs解码图潜在样本的方法,如图8所示。为了便于理解,我们将重点讨论具有非属性节点和边的图。最重要的是,我们假定我们知道正确的采样技术;稍后,我们将讨论如何学习这些抽样机制。
。这些方法一次性采样图邻接矩阵。更详细地,解码器以图表示作为输入,输出一个密集的概率邻接矩阵 , 其中 是允许的最大节点数,每个条目 指定观察节点 和 之间的弧的概率。这对应于最小化以下对数似然:
图8:显示了图级(顶行(上边的))和节点级(底行(下边的额))生成解码器的简化模式。箭头上的波浪符号表示采样。虚线箭头表示相应的采样过程一般是不可微的。蓝色的阴影表示可能性更高。
其中 ,这里的 是采样图表示。要获得新的图形,可以执行以下任一操作:
- 1.用连接概率 对概率邻接矩阵的每个条目进行抽样;
- 2.如[96,60]中所示,在概率矩阵和基本事实矩阵之间执行近似图匹配;
- 3.通过使用Gumbel-Softmax [51]进行分类重新参数化,使采样过程变得可微,例如在[20]中探讨的那样。
注意,前两个选项是不可微的;在这种情况下,实际的重建损失不能在训练期间反向传播。因此,重构损失是在概率矩阵上计算的,而不是在实际矩阵上计算[96]。图级解码器不是置换不变的(除非使用近似的图匹配),因为输出矩阵的顺序假设是固定的
。节点级解码器从一组k个节点表示形式开始生成图。根据它们的概率分布的近似值对它们进行采样。为了在该设置下解码图,需要26生成以采样节点集为条件的邻接矩阵。这是通过将所有可能的k(k + 1)/2无序节点对作为输入引入解码器来实现的,用来优化以下的对数似然。
其中
和等式11中的一样,并且类似于[58、41]和
是采样节点表示。与图级解码相反,此方法是置换不变的,尽管通常计算比单次邻接矩阵生成更昂贵。
为了补充我们的讨论,下面,我们总结那些生成模型,这些模型可以优化解码目标,同时共同学习如何对潜在表示空间进行采样。我们将那些显式学习其(可能是近似的)概率分布的方法与那些隐式学习如何从该分布中进行采样的方法区分开来。前者基于生成自动编码器(AE)[57,100],而后者则利用生成对抗网络(GAN)[39]。
。图的生成AE通过学习潜在空间中节点(或图)表示的概率分布来工作。然后将这种分布的样本提供给解码器以生成新的图。通过生成式AE对图进行优化的损失函数的一般公式如下:
其中
如上所述,是解码器的重构误差,
是一种发散度量,它迫使潜伏空间中的点分布类似于“易处理的”先验值(通常是各向同性的高斯
)。例如,基于变分AE的模型[57]使用以下编码器损耗:
其中
是Kullback-Leibler散度,编码分布的两个参数计算为
和
[96,66,87]。诸如[14]等更新的方法建议用相应的Wasserstrain AE [100]项代替AE损失中的编码器误差项。
生成对抗网络。基于GAN的方法特别方便,因为它们不能直接与P(g)一起使用,而只能学习一种自适应机制来从中采样。 GAN使用两种不同的功能:生成器G(生成新的图)和鉴别器D,经过训练以识别其输入是来自生成器还是来自数据集。生成器和鉴别器都经过共同训练,以最大程度地最小化以下目标:
其中
为数据的真实未知概率分布,
为潜在空间上的先验分布(通常为各向同性(等向性)高斯分布或均匀分布)。注意,这个过程提供了一种隐式的方法来从感兴趣的概率分布中取样,而不直接操作它。在图生成的情况下,
可以是一个图或节点级解码器,它以潜在空间中的一个随机点作为输入,生成一个图,而
以一个图作为输入并且生成一个伪图的概率取决于生成器。例如,[27]将
实现为一个图形级解码器,该解码器同时输出一个概率邻接矩阵
和一个节点标签矩阵
。鉴别器以邻接矩阵
和节点标号矩阵
为输入,对其应用Jumping Knowledge Network(跳跃知识网络)[114],判断图数据是来自生成器还是来自MLP数据集。相反,[107]在节点级工作。具体地说,具体而言,
生成结构感知的节点表示(基于从训练集中采样的随机图的BFS树的连通性),而鉴别器将两个节点表示作为输入,并确定它们是否来自训练集或生成器,优化类似于方程式15的目标函数。
4.4、总结
- Continuous:连续的
- Discrete:离散的
- Topological:拓扑的
- Adaptive:自适应的
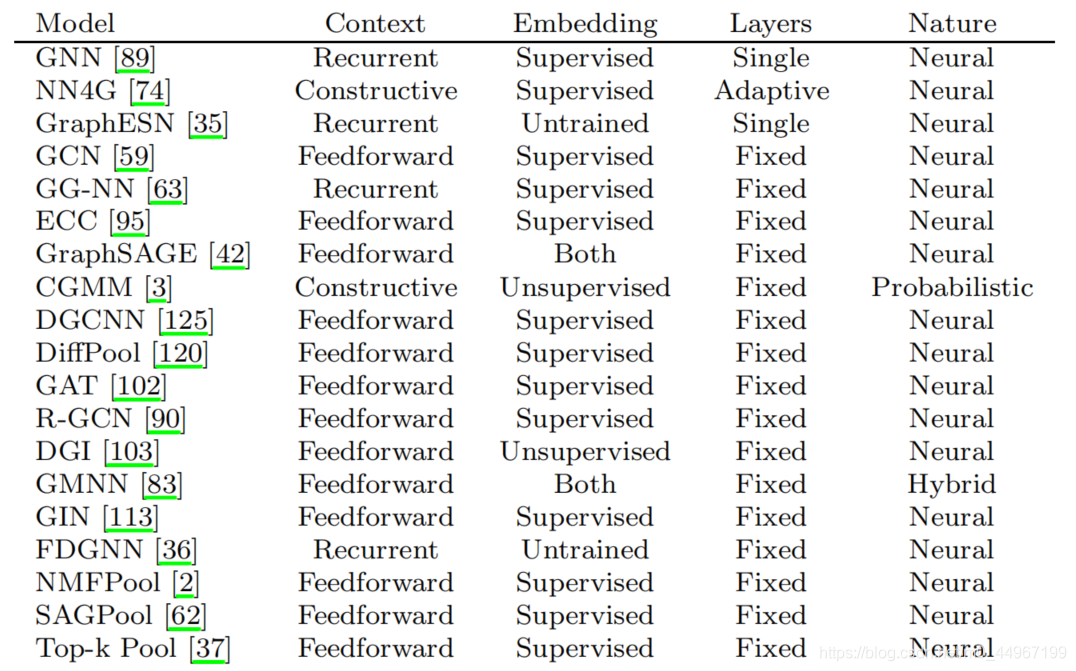
表2:根据我们到目前为止所讨论的内容,我们在这里概述DGNs的主要特性。为了清楚起见, 意味着不适用,因为该模型是一个依赖于任何通用学习方法的框架。Layers列描述了一个架构使用了多少个层,这些层可以是一个固定的数字,或者由学习过程自适应地决定。另一方面,“上下文”指的是特定层的上下文扩散方法,如2.5节所述。
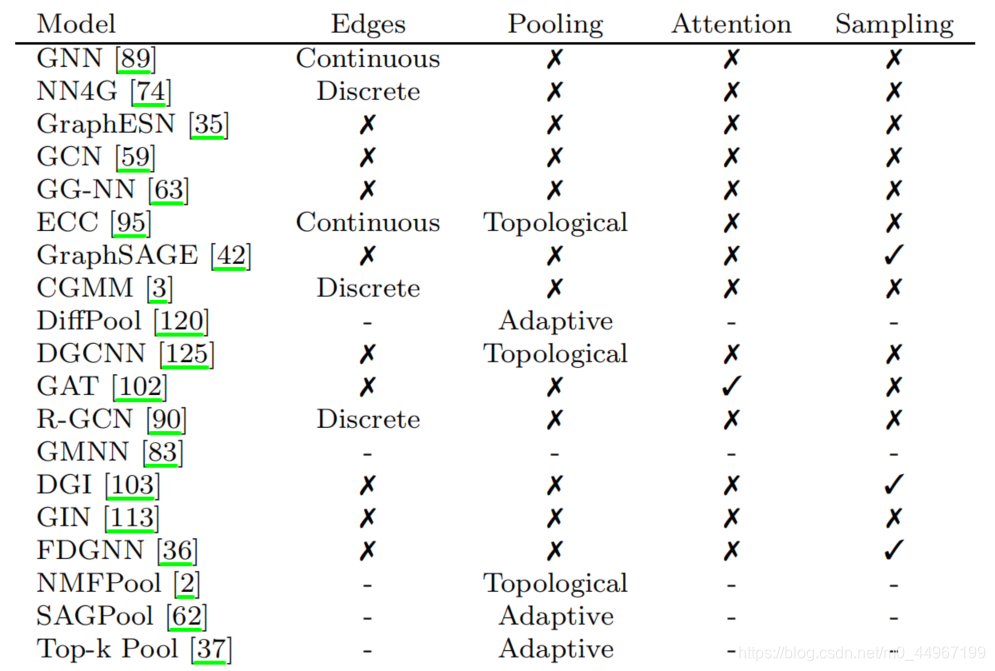
在本节的最后,我们将根据到目前为止讨论的构建块和任务提供一些局部迭代模型的特征。具体来说,表2针对四个关键属性对模型进行了区分:上下文扩散方法、如何计算嵌入、如何构造层以及方法的性质。然后,我们添加了模型可能具有或不具有的其他属性,例如处理边缘、执行池化、参与邻居和对邻居进行采样的能力。
5. 总结其他方法和要求
有许多方法和主题在前面几节讨论的分类法中没有涉及。我们特别关注图的深度学习方法,这些方法大多基于局部和迭代处理。为了完整的阐述,我们现在简要回顾一些被排除在外的主题。
5.1. Kernels
关于应用于图的内核方法有一个长期的和统一的研究路线[94,84,115,31,104]。核被非正式地定义为正定函数的一种广义形式,它计算输入对之间的相似度得分。内核方法的一个重要方面是,它们通常是非局部的、非自适应的,也就是说,它们会影响到图的应用。,它们需要人来设计核函数。当应用于图数据时,当已知感兴趣的属性时,内核方法工作得特别好,但是使用自适应方法仍然很难更好地执行。然而,如上所述,不自适应是内核的主要缺点,因为我们并不总是清楚我们想从图中提取哪些特性。此外,当数据集中的输入数量过大时(尽管有一些例外,参见[94]),内核会遇到可伸缩性问题。将核相似矩阵与支持向量机[19]相结合进行图分类。
5.2. Spectral methods(谱方法)
频谱图理论通过相关的邻接关系和拉普拉斯矩阵研究图的性质。这些技术可以解决许多机器学习问题,例如拉普拉斯平滑[86],图半监督学习[81,17]和频谱聚类[105]。图还可以使用信号处理工具进行分析,例如图傅立叶变换[46]和相关的自适应技术[16]。一般而言,光谱技术旨在基于相同形状的图,因为它们基于邻接和拉普拉斯矩阵的特征分解。但是,存在从节点数抽象的多项式逼近,GCN模型[59]就是这样一个例子。
5.3、随机游走
为了捕获图的局部和全局特性,经常使用随机游走创建节点嵌入,并且已经对其进行了长时间的研究[67,104,85,50]。简单地将随机游走定义为连接图中两个节点的随机路径。根据可到达的节点,我们可以设计不同的框架来学习节点表示:例如,Node2Vec [40]通过使用随机游走来探索图,从而根据给定的环境最大化了节点的可能性。此外,在深度优先搜索比广度优先搜索更可取的情况下,可学习的参数指导行走的偏向。类似地,DeepWalk [82]通过将随机游走建模为句子并最大化似然目标来学习连续的节点表示。最近,随机游走也已用于生成图[12],并且已经探索了GCN的上下文信息传播与随机游走之间的形式联系[114]。
5.4、图的对抗训练和攻击
考虑到使用图数据结构的实际应用的重要性,最近人们对研究DGNs对恶意攻击的鲁棒性越来越感兴趣。对抗性训练这个术语是在深层神经网络的背景下使用的,它用于识别基于输入扰动的模型的正则化策略。关键是要让网络对[10]的攻击具有弹性。最近,神经DGNs也被证明有对抗攻击的倾向[131],而使用对抗训练进行正规化是相对较新的[28]。对抗性训练的目标函数被表述为一个最小化对抗性例子的有害影响的最大博弈。简单地说,模型是用来自训练集的原始图和对抗性图进行训练的。使一个图具有对抗性的扰动的例子包括弧的插入和删除[117]或向节点表示[54]添加对抗性噪声。对抗性图是根据其在数据集中最接近的匹配程度进行标记的,以保持损失函数空间的平滑性,并在存在扰动图的情况下保持模型的预测能力。
5.5、图的顺序生成模型
生成图的另一个可行选择是将生成过程建模为一系列动作。事实证明,这种方法能够概括来自非常不同的训练分布的图形。但是,它依赖于图节点的固定顺序。文献[65]中的方法是一种开创性的方法,其中图的生成被建模为决策过程。具体来说,共同训练一堆神经网络,以了解是否要添加新节点,是否要添加新边缘以及要关注下一个迭代的节点。另一个有趣的工作是[121],其中将生成公式化为自回归过程,其中将节点顺序添加到现有图。每次添加新节点时,节点级别的门控循环单元(GRU)网络都会预测其相对于现有节点的邻接矢量。同时,图级GRU网络跟踪整个图的状态,以调节邻接矢量的生成。最后,[5,4]通过学习使用两个GRU网络预测图的有序边集来对生成任务进行建模。第一个生成边缘的第一个端点,而第二个则根据这些信息预测缺失的端点。
6.挑战与研究之路
尽管图学习方法学的作品数量稳步增长,但仍有一些研究尚未得到广泛研究。下面,我们提到其中的一些内容,以便为从业者提供有关潜在研究途径。
6.1. Time-evolving graphs(随着时间变化的图)
目前的研究主要集中在从静态图中自动提取特征的方法上。然而,能够对动态变化的图进行建模是本研究中所讨论的技术的进一步推广。文献中已经有一些有监督[63,110]和无监督[124]的建议,但这条研究线发展的限制因素似乎是,目前缺乏大型数据集,尤其是非合成性质的数据集。
6.2. Bias-variance trade-offs(偏差方差的权衡)
第3.1节中描述的不同节点聚合机制在确定模型可以区分的结构类型方面起着至关重要的作用。例如,已经证明[113],GIN在理论上与图同构的1维Weisfeiler Lehman测试一样强大。结果,GIN模型能够适合它所应用的大多数数据集。尽管该模型非常灵活,但要学习一个泛化效果好的函数可能会很困难:这是通常的偏差-方差折衷的结果[34]。因此,需要根据结构区分能力来表征所有节点聚合技术。 DGN的更原则性定义对于能够为特定应用选择正确的模型至关重要。
6.3. A sensible use of edge information(合理使用边缘信息)
在信息源方面,边缘通常被视为二等公民。实际上,大多数处理附加边缘特征的模型[74、95、3、90]都会计算加权聚合,其中权重是通过对边缘信息进行适当的转换来给出的。但是,还有一些有趣的问题尚未得到回答。例如,将上下文扩展技术应用于边缘是否合理?这种方法的优点仍然不清楚。此外,表征利用边缘信息的方法的辨别力将是有趣的。
6.4、超图学习
超图是图的一般化(泛化),其中边连接到的是节点的子集,而不仅仅是连接两个节点。最近已经出版了一些有关从超图学习的著作[129,128,29,53],而最新的著作则从图的局部和迭代处理中获得启发。像时间演变图一样,基准数据集的稀缺可用性使得难以凭经验评估这些方法。
7.应用
在这里,我们给出了可以应用图学习的领域示例。我们想强调的是,将更通用的方法应用于通常使用平面或顺序表示法解决的问题可能会带来性能上的好处。由于图在本质上无处不在,因此以下列表并非详尽无遗。尽管如此,我们还是总结了一些最常见的应用程序,以便为读者提供介绍性的概述。
7.1、化学与药物设计
化学信息学可能是成功应用DGN的突出领域,并且化学化合物数据集通常用于对新模型进行基准测试。从高层次上讲,该领域的预测任务涉及学习分子结构与目标结果之间的直接映射。例如,定量结构-活性关系(QSAR)分析处理化合物生物活性的预测。同样,定量结构-性质关系(QSPR)分析着重于化学性质(如毒性和溶解度)的预测。结构化数据模型在QSAR / QSPR分析中的先驱应用实例在[9]中,有关调查请参见[76]。 DNGN也已用于发现化合物之间的结构相似性[24,52]。另一个有趣的研究领域是计算药物设计,例如,药物副作用识别[130]和药物发现。关于后面的任务,有几种方法使用深层生成模型来发现新化合物。这些模型也是提供寻找具有所需化学性质的分子的机制[55,87,66]。就图分类的基准而言,用于评估DGN性能的化学数据集数量稳定。其中,我们提到了NCI1 [106],蛋白质,[13] D&D [23],MUTAG [21],PTC [47]和酶[91]。为了完整起见,我们在表3中报告了[25]的结果,其中对一组重要的DGN进行了严格的经验评估。
表3:化学数据集的结果(平均准确度和标准偏差)。最佳表现以粗体突出显示

7.2、社交网络
社交图将用户表示为节点,并将关系(如友谊或共同创作)表示为弧。用户表示法在各种任务中引起了极大的兴趣,例如,检测图中的参与者是否是错误信息或不健康行为的潜在来源[77,80]。由于这些原因,社交网络可以说是图形学习方法最丰富的信息源,因为每个用户都可以使用大量功能。同时,对此类信息的利用引起了隐私和道德方面的关注,这就是数据集不可公开获得的原因。社交图上的大多数监督任务都涉及节点和图的分类。在节点分类中,通常使用文献中的三个主要数据集来评估DGN的性能:Cora,Citeseer [92]和PubMed [79]。在[93]中进行了严格的评估,我们在表5中总结了它们对大量DGN的结果。相反,(二进制和多类)图分类最流行的社会基准是IMDB-BINARY,IMDB-MULTI,REDDIT -BINARY,REDDIT-MULTI和COLLAB [116]。在表5,我们报告了对这些数据集上几个DGN进行严格评估的结果,其中图使用了非信息性的节点特征,如[25]中所做的。
表4:我们报告了社交数据集上节点分类的平均准确度和标准差,如[93]。所有模型都在具有无信息节点特征的社交图上进行训练。最佳表现以粗体突出显示
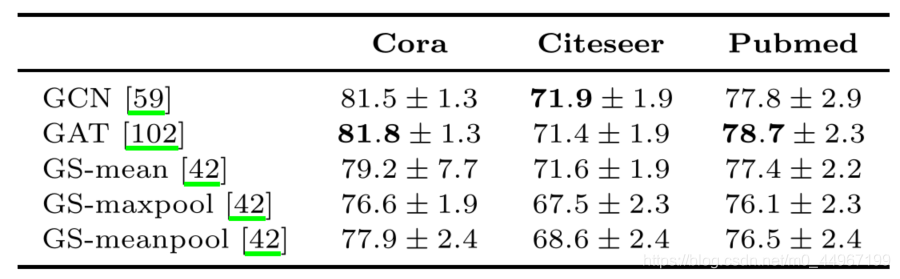
表5:我们报告了社会数据集上的图分类的平均精度和标准偏差,如[25]。所有的模型都是在具有非信息性节点特征的社交图上训练的。基线是一个基于[123]的结构不可知网络。最好的表演用粗体突出显示。OOR表示资源不足,要么是时间(单次训练>
72小时),要么是GPU内存。
7.3. Natural Language Processing
另一个有趣的应用领域将图学习方法用于自然语言处理(NLP)任务,其中输入通常表示为tokens(标记?)序列。通过依赖解析器,我们可以将输入增加为树[1]或图,并学习一个模型,该模型考虑了文本中标记之间的句法[71]和语义[70]关系。神经机器翻译就是一个例子,可以将其表达为图序问题[8],以考虑源句和目标句中的句法依存关系。
7.4. Security
静态代码分析领域是图学习方法的一个有希望的新应用途径。实际应用包括:i)确定两个源自同一源代码的两个汇编程序是否通过不同的优化技术进行了编译;ii)通过扩充抽象语法树[49]预测特定类型的bug;iii)预测一个程序是否可能是另一个程序的混淆版本;iv)从控制流程图中自动提取特征[73]。
7.5. Spatio-temporal forecasting(时空预测)
DGN解决图形结构随时间变化的任务也很有趣。在这种情况下,人们不仅对捕获节点之间的空间结构相关性感兴趣,而且还对这些相关性在时域上的演变感兴趣。解决此问题的方法通常结合使用DGN(以提取图的结构特性)和递归神经网络(以建模时间依存关系)。应用示例包括对道路网络中交通的预测[122],动作识别[109]和供应链[56]任务。
7.6. Recommender Systems
在推荐系统(RSs)域[11]中,图形是对用户和推荐项目之间的关系进行编码的自然选择。例如,典型的RSs用户-项目矩阵可以看作是一个二部图,而用户-用户和项目-项目矩阵可以表示为标准的无向图。向用户推荐一个项目是一个矩阵完成任务。,学习填充用户-项目矩阵的未知项,可以等价地表示为一个链接预测任务。基于这些类比,最近发展了几种DGN模型来从图数据中学习RSs[78,118]。目前的主要问题是计算的可伸缩性。因此,为了减少计算开销,人们提出了类似于邻域抽样的技术[119]。
8. Conclusions
经过数千年早期的一个开创性阶段后,用于图形处理的神经网络现在是一个统一的、充满活力的研究领域。在这个扩展阶段,研究工作的速度很快,产生了过多的模型和变体,较少关注系统化和跟踪早期和近期的文献。为了使这一领域进一步进入成熟阶段,我们认为,某些方面应得到深化和更优先的追求。从这个意义上说,第一个挑战是在一个统一的框架下形式化几种自适应图形处理模型,可能来自不同的范例(基于内核的、神经的和概率的),该框架强调了不同方法的相似性、差异性和新奇性。这样的框架还应该允许在更高的层次上对模型的理论和表达特性进行推理[113]。在这个意义上,[38]做了一个值得注意的尝试,但它没有考虑到最新的发展和发布的各种机制(例如,池操作符、图生成等)。关于这一目标的一个很好的参考资料是[32]的开创性工作,它为树结构数据处理提供了一个通用框架。该框架具有足够的表现力,可以将监督学习推广到树与树之间的非同形转导,并产生了后续的理论研究[45,44],巩固了递归神经网络领域。第二个挑战涉及定义一组丰富而健壮的基准,以便在公平、一致和可重复的条件下测试和评估模型。一些工作[25,93]已经引起了社会的注意,一些令人不安的趋势和陷阱,如文献中用于评估DGNs的数据集和方法。我们相信社会应积极接纳这些批评意见,以促进该领域的发展。一些提供一套标准化数据和方法的尝试现在正在发展中。与这一挑战相关的是,由于用于图形自适应处理的现代软件包的增长和社区的广泛采用,促进了最近的进展。特别是,PyTorch geometry的[30]和Deep Graph Library[108]包提供了标准化的接口来操作图形,以便于开发。此外,它们还允许使用更深入的交易技巧,如GPU兼容性和图形的批处理。。最后一个挑战与应用程序有关。我们相信,当一种方法将研究知识转化为对社会有影响的创新时,它就成熟了。同样,这种意义上的尝试已经开始了,化学[14]和生命科学领域都有很好的候选者[130]。最后,我们希望这篇论文能够对这个领域做出贡献,为新来者提供一个慢节奏的介绍,同时为有经验的从业者提供一个在早期文献中有充分根据的综合参考。
- : 高斯分布
- 表示GNN[89]中的一个迭代步骤,而不是一个层。
- : 投影矢量
- :是层 的编码矩阵
- :是层 的邻接矩阵
- 软成员矩阵
- 表示连接
- 是可学习的参数
- 是共享注意力函数
- 是与 相关的注意力得分。
- 符号 : 解释为递归状态转换函数的“迭代步骤”
- : 表示在 层的节点 的隐藏状态向量,即节点的内部表示.
- : 表示在 层与整个图 相关的表示。在 层的图嵌入表示
- : 表示置换不变函数,表示置换不变函数,即具有以下属性的函数: ,其中Z是泛型集合,而 是任意值排列运算符。
- 和 是任意的函数。
- : 节点 的邻域定义为以有向弧连接到 的节点集合
- :单个图形表示形式
- :单个图形表示形式
- = 即g的邻接矩阵,定义为
References
[1] Davide Bacciu and Antonio Bruno. Deep tree transductions - a short
survey. In Luca Oneto, Nicol` o Navarin, Alessandro Sperduti, and Davide
Anguita, editors, Recent Advances in Big Data and Deep Learning, pages
236–245. Springer International Publishing, 2020.
[2] Davide Bacciu and Luigi Di Sotto. A non-negative factorization approach
to node pooling in graph convolutional neural networks. In Mario Al-
viano, Gianluigi Greco, and Francesco Scarcello, editors, AI*IA 2019 –
Advances in Artificial Intelligence, pages 294–306. Springer International
Publishing, 2019.
[3] Davide Bacciu, Federico Errica, and Alessio Micheli. Contextual graph
Markov model: A deep and generative approach to graph processing. In
Proceedings of the 35th International Conference on Machine Learning,
volume 80, pages 294–303. PMLR, 2018.
[4] Davide Bacciu, Alessio Micheli, and Marco Podda. Edge-based sequen-
tial graph generation with recurrent neural networks. Neurocomputing.
Accepted, 2019.
[5] Davide Bacciu, Alessio Micheli, and Marco Podda. Graph generation by
sequential edge prediction. In Proceedings of the European Symposium
on Artificial Neural Networks, Computational Intelligence and Machine
Learning (ESANN’19). i6doc.com, 2019.
[6] Davide Bacciu, Alessio Micheli, and Alessandro Sperduti. Compositional
generative mapping for tree-structured data; part I: Bottom-up proba-
bilistic modeling of trees. IEEE Transactions on Neural Networks and
Learning Systems, 23(12):1987–2002, 2012.
[7] Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-
Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti,
David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational in-
ductive biases, deep learning, and graph networks. arXiv preprint
arXiv:1806.01261, 2018.
[8] Daniel Beck, Gholamreza Haffari, and Trevor Cohn. Graph-to-sequence
learning using gated graph neural networks. In Proceedings of the 56th
Annual Meeting of the Association for Computational Linguistics (Volume
1: Long Papers), pages 273–283, 2018.
[9] Anna Maria Bianucci, Alessio Micheli, Alessandro Sperduti, and Anton-
ina Starita. Application of cascade correlation networks for structures to
chemistry. Applied Intelligence, 12(1-2):117–147, 2000.
[10] Battista Biggio and Fabio Roli. Wild patterns: Ten years after the rise of
adversarial machine learning. Pattern Recognition, 84:317 – 331, 2018.
[11] J. Bobadilla, F. Ortega, A. Hernando, and A. Guti´ errez. Recommender
systems survey. Knowledge-Based Systems, 46:109 – 132, 2013.
[12] Aleksandar Bojchevski, Oleksandr Shchur, Daniel Z¨ ugner, and Stephan
G¨ unnemann. Netgan: Generating graphs via random walks. In Interna-
tional Conference on Machine Learning, pages 609–618, 2018.
[13] Karsten M Borgwardt, Cheng Soon Ong, Stefan Sch¨ onauer, SVN Vish-
wanathan, Alex J Smola, and Hans-Peter Kriegel. Protein function pre-
diction via graph kernels. Bioinformatics, 21(suppl 1), 2005.
[14] John Bradshaw, Brooks Paige, Matt J Kusner, Marwin Segler, and
Jos´ e Miguel Hern´ andez-Lobato. A model to search for synthesizable
molecules. In Advances in Neural Information Processing Systems 32,
pages 7935–7947. 2019.
[15] Michael M. Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and
Pierre Vandergheynst. Geometric deep learning: going beyond euclidean
data. IEEE Signal Processing Magazine, 34(4):25. 18–42, 2017.
[16] Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spec-
tral networks and locally connected networks on graphs. International
Conference on Learning Representations, 2014.
[17] Daniele Calandriello, Ioannis Koutis, Alessandro Lazaric, and Michal
Valko. Improved large-scale graph learning through ridge spectral sparsifi-
cation. In International Conference on Machine Learning, pages 687–696,
2018.
[18] Jie Chen, Tengfei Ma, and Cao Xiao. FastGCN: Fast learning with graph
convolutional networks via importance sampling. In International Con-
ference on Learning Representations, 2018.
[19] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine
learning, 20(3):273–297, 1995.
[20] Nicola De Cao and Thomas Kipf. MolGAN: An implicit generative model
for small molecular graphs. ICML 2018 workshop on Theoretical Founda-
tions and Applications of Deep Generative Models, 2018.
[21] Asim Kumar Debnath, Rosa L Lopez de Compadre, Gargi Debnath,
Alan J Shusterman, and Corwin Hansch. Structure-activity relationship
of mutagenic aromatic and heteroaromatic nitro compounds. correlation
with molecular orbital energies and hydrophobicity. Journal of medicinal
chemistry, 34(2):786–797, 1991.
[22] Inderjit S. Dhillon, Yuqiang Guan, and Brian Kulis. Weighted graph
cuts without eigenvectors a multilevel approach. IEEE Transactions on
Pattern Analysis and Machine Intelligence, 29(11):1944–1957, 2007.
[23] Paul D Dobson and Andrew J Doig. Distinguishing enzyme structures
from non-enzymes without alignments. Journal of molecular biology,
330(4), 2003.
[24] David K. Duvenaud, Dougal Maclaurin, Jorge Iparraguirre, Rafael Bom-
barelli, Timothy Hirzel, Alan Aspuru-Guzik, and Ryan P. Adams. Con-
volutional Networks on Graphs for Learning Molecular Fingerprints. In
Advances in Neural Information Processing Systems 28, pages 2224–2232.
Curran Associates, Inc., 2015.
[25] Federico Errica, Marco Podda, Davide Bacciu, and Alessio Micheli. A fair
comparison of graph neural networks for graph classification. In Interna-
tional Conference on Learning Representations, 2020.
[26] Scott E. Fahlman and Christian Lebiere. The cascade-correlation learning
architecture. In D. S. Touretzky, editor, Advances in Neural Information
Processing Systems 2, pages 524–532. Morgan-Kaufmann, 1990.
[27] S. Fan and B. Huang. Conditional labeled graph generation with gans. In
ICLR Workshop on Representation Learning on Graphs and Manifolds,
2019.
[28] Fuli Feng, Xiangnan He, Jie Tang, and Tat-Seng Chua. Graph adversar-
ial training: Dynamically regularizing based on graph structure. CoRR,
abs/1902.08226, 2019.
[29] Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao.
Hypergraph neural networks. In Proceedings of the AAAI Conference on
Artificial Intelligence, volume 33, pages 3558–3565, 2019.
[30] Matthias Fey and Jan E. Lenssen. Fast graph representation learning with
PyTorch Geometric. In ICLR Workshop on Representation Learning on
Graphs and Manifolds, 2019.
[31] Paolo Frasconi, Fabrizio Costa, Luc De Raedt, and Kurt De Grave. klog:
A language for logical and relational learning with kernels. Artificial In-
telligence, 217:117–143, 2014.
[32] Paolo Frasconi, Marco Gori, and Alessandro Sperduti. A general frame-
work for adaptive processing of data structures. IEEE transactions on
Neural Networks, 9(5):768–786, 1998.
[33] Michael Truong Le Frederik Diehl, Thomas Brunner and Alois Knoll. To-
wards graph pooling by edge contraction. In ICML 2019 Workshop on
Learning and Reasoning with Graph-Structured Data, 2019.
[34] Jerome Friedman, Trevor Hastie, and Robert Tibshirani. The elements of
statistical learning, volume 1. Springer series in statistics New York, 2001.
[35] Claudio Gallicchio and Alessio Micheli. Graph echo state networks. In
Neural Networks (IJCNN), The 2010 International Joint Conference on,
pages 1–8. IEEE, 2010.
[36] Claudio Gallicchio and Alessio Micheli. Fast and deep graph neural net-
works. In Proceedings of AAAI, 2020. (To Appear).
[37] Hongyang Gao and Shuiwang Ji. Graph u-nets. In International Confer-
ence on Machine Learning, pages 2083–2092, 2019.
[38] Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals,
and George E. Dahl. Neural message passing for quantum chemistry. In
Proceedings of the 34th International Conference on Machine Learning,
volume 70 of Proceedings of Machine Learning Research, pages 1263–1272.
PMLR, 2017.
[39] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David
Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Gen-
erative adversarial nets. In Advances in Neural Information Processing
Systems 27, pages 2672–2680. 2014.
[40] Aditya Grover and Jure Leskovec. node2vec: Scalable feature learning for
networks. In Proceedings of the 22nd ACM SIGKDD international con-
ference on Knowledge discovery and data mining, pages 855–864. ACM,
2016.
[41] Aditya Grover, Aaron Zweig, and Stefano Ermon. Graphite: Iterative gen-
erative modeling of graphs. In Kamalika Chaudhuri and Ruslan Salakhut-
dinov, editors, Proceedings of the 36th International Conference on Ma-
chine Learning, volume 97 of Proceedings of Machine Learning Research,
pages 2434–2444, Long Beach, California, USA, 09–15 Jun 2019. PMLR.
[42] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation
learning on large graphs. In Advances in Neural Information Processing
Systems, pages 1024–1034, 2017.
[43] William L. Hamilton, Rex Ying, and Jure Leskovec. Representation
learning on graphs: Methods and applications. IEEE Data Eng. Bull.,
40(3):52–74, 2017.
[44] Barbara Hammer, Alessio Micheli, and Alessandro Sperduti. Universal
approximation capability of cascade correlation for structures. Neural
Computation, 17(5):1109–1159, 2005.
[45] Barbara Hammer, Alessio Micheli, Alessandro Sperduti, and Marc
Strickert. Recursive self-organizing network models. Neural Networks,
17(8):1061 – 1085, 2004. New Developments in Self-Organizing Systems.
[46] David K Hammond, Pierre Vandergheynst, and R´ emi Gribonval. Wavelets
on graphs via spectral graph theory. Applied and Computational Harmonic
Analysis, 30(2):129–150, 2011.
[47] Christoph Helma, Ross D. King, Stefan Kramer, and Ashwin Srinivasan.
The predictive toxicology challenge 2000–2001. Bioinformatics, 17(1):107–
108, 2001.
[48] Sepp Hochreiter and J¨ urgen Schmidhuber. Long short-term memory. Neu-
ral Comput., 9(8):1735–1780, November 1997.
[49] Giacomo Iadarola. Graph-based classification for detecting instances of
bug patterns. Master’s thesis, University of Twente, 2018.
[50] Sergey Ivanov and Evgeny Burnaev. Anonymous walk embeddings. In
International Conference on Machine Learning, pages 2191–2200, 2018.
[51] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparametrization
with gumbel-softmax. In Proceedings International Conference on Learn-
ing Representations, 2017.
[52] Woosung Jeon and Dongsup Kim. FP2VEC: a new molecular featurizer
for learning molecular properties. Bioinformatics, 35(23):4979–4985, 2019.
[53] Jianwen Jiang, Yuxuan Wei, Yifan Feng, Jingxuan Cao, and Yue Gao. Dy-
namic hypergraph neural networks. In Proceedings of the Twenty-Eighth
International Joint Conference on Artificial Intelligence (IJCAI), pages
2635–2641, 2019.
[54] H. Jin and X. Zhang. Latent adversarial training of graph convolution
networks. In ICML Workshop on Learning and Reasoning with Graph-
Structured Representations, 2019.
[55] Wengong Jin, Regina Barzilay, and Tommi S. Jaakkola. Junction tree
variational autoencoder for molecular graph generation. In Proceedings
of the 35th International Conference on Machine Learning, ICML 2018,
tockholmsm¨ assan, Stockholm, Sweden, July 10-15, 2018, pages 2328–
2337, 2018.
[56] Tae San Kim, Won Kyung Lee, and So Young Sohn. Graph convolu-
tional network approach applied to predict hourly bike-sharing demands
considering spatial, temporal, and global effects. PLOS ONE, 14(9), 09
2019.
[57] Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In
2nd International Conference on Learning Representations, ICLR 2014,
2014.
[58] Thomas N Kipf and Max Welling. Variational graph auto-encoders. In
NIPS Workshop on Bayesian Deep Learning, 2016.
[59] Thomas N Kipf and Max Welling. Semi-supervised classification with
graph convolutional networks. In ICLR, 2017.
[60] Youngchun Kwon, Jiho Yoo, Youn-Suk Choi, Won-Joon Son, Dongseon
Lee, and Seokho Kang. Efficient learning of non-autoregressive graph vari-
ational autoencoders for molecular graph generation. Journal of Chemin-
formatics, 11:70, 2019.
[61] Yann LeCun, Yoshua Bengio, et al. Convolutional networks for images,
speech, and time series. The handbook of brain theory and neural networks,
3361(10):1995, 1995.
[62] Junhyun Lee, Inyeop Lee, and Jaewoo Kang. Self-attention graph pooling.
In International Conference on Machine Learning, pages 3734–3743, 2019.
[63] Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. Gated
graph sequence neural networks. International Conference on Learning
Representations, 2016.
[64] Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard S. Zemel.
Gated graph sequence neural networks. In 4th International Conference
on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May
2-4, 2016, Conference Track Proceedings, 2016.
[65] Yujia Li, Oriol Vinyals, Chris Dyer, Razvan Pascanu, and Peter W.
Battaglia. Learning deep generative models of graphs. ArXiv,
abs/1803.03324, 2018.
[66] Qi Liu, Miltiadis Allamanis, Marc Brockschmidt, and Alexander Gaunt.
Constrained graph variational autoencoders for molecule design. In Ad-
vances in Neural Information Processing Systems 31, pages 7795–7804.
2018.
[67] L´ aszl´ o Lov´ asz et al. Random walks on graphs: A survey. Combinatorics,
Paul erdos is eighty, 2(1):1–46, 1993.
[68] Andrew L. Maas, Awni Y. Hannun, and Andrew Y. Ng. Rectifier nonlin-
earities improve neural network acoustic models. In ICML Workshop on
Deep Learning for Audio, Speech and Language Processing, 2013.
[69] Sofus A Macskassy and Foster Provost. Classification in networked data:
A toolkit and a univariate case study. Journal of machine learning re-
search, 8(May):935–983, 2007.
[70] Diego Marcheggiani, Joost Bastings, and Ivan Titov. Exploiting seman-
tics in neural machine translation with graph convolutional networks. In
Proceedings of the 2018 Conference of the North American Chapter of the
Association for Computational Linguistics: Human Language Technolo-
gies, Volume 2 (Short Papers), pages 486–492, 2018.
[71] Diego Marcheggiani and Ivan Titov. Encoding sentences with graph con-
volutional networks for semantic role labeling. In Proceedings of the 2017
Conference on Empirical Methods in Natural Language Processing, pages
1506–1515, 2017.
[72] Enrique S Marquez, Jonathon S Hare, and Mahesan Niranjan. Deep cas-
cade learning. IEEE Transactions on Neural Networks and Learning Sys-
tems, 2018.
[73] Luca Massarelli, Giuseppe Antonio Di Luna, Fabio Petroni, Roberto Bal-
doni, and Leonardo Querzoni. Safe: Self-attentive function embeddings for
binary similarity. In International Conference on Detection of Intrusions
and Malware, and Vulnerability Assessment, pages 309–329. Springer,
2019.
[74] Alessio Micheli. Neural network for graphs: A contextual constructive
approach. IEEE Transactions on Neural Networks, 20(3), 2009.
[75] Alessio Micheli, Diego Sona, and Alessandro Sperduti. Contextual pro-
cessing of structured data by recursive cascade correlation. IEEE Trans-
actions on Neural Networks, 15(6):1396–1410, Nov 2004.
[76] Alessio Micheli, Alessandro Sperduti, and Antonina Starita. An introduc-
tion to recursive neural networks and kernel methods for cheminformatics.
Current pharmaceutical design, 13(14):1469–1496, 2007.
[77] Pushkar Mishra, Helen Yannakoudakis, and Ekaterina Shutova. Neural
character-based composition models for abuse detection. In Proceedings
of the 2nd Workshop on Abusive Language Online (ALW2), pages 1–10,
2018.
[78] Federico Monti, Michael M. Bronstein, and Xavier Bresson. Geomet-
ric matrix completion with recurrent multi-graph neural networks. In
Proceedings of the 31st International Conference on Neural Information
Processing Systems, NIPS’17, pages 3700–3710, 2017.
[79] Galileo Mark Namata, Ben London, Lise Getoor, and Bert Huang. Query-
driven active surveying for collective classification. In Workshop on Mining
and Learning with Graphs, 2012.
[80] Yaroslav Nechaev, Francesco Corcoglioniti, and Claudio Giuliano. So-
ciallink: exploiting graph embeddings to link dbpedia entities to twitter
profiles. Progress in Artificial Intelligence, 7(4):251–272, 2018.
[81] Chapelle Olivier, S Bernhard, and Zien Alexander. Semi-supervised learn-
ing. In IEEE Transactions on Neural Networks, volume 20, pages 542–542.
2006.
[82] Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. Deepwalk: Online learn-
ing of social representations. In Proceedings of the 20th ACM SIGKDD
international conference on Knowledge discovery and data mining, pages
701–710. ACM, 2014.
[83] Meng Qu, Yoshua Bengio, and Jian Tang. GMNN: Graph Markov neural
networks. In Proceedings of the 36th International Conference on Machine
Learning, 2019.
[84] Liva Ralaivola, Sanjay J Swamidass, Hiroto Saigo, and Pierre Baldi.
Graph kernels for chemical informatics. Neural networks, 18(8):1093–1110,
2005.
[85] Leonardo F.R. Ribeiro, Pedro H.P. Saverese, and Daniel R. Figueiredo.
Struc2vec: Learning node representations from structural identity. In Pro-
ceedings of the 23rd ACM SIGKDD International Conference on Knowl-
edge Discovery and Data Mining, KDD ’17, pages 385–394, New York,
NY, USA, 2017. ACM.
[86] Veeru Sadhanala, Yu-Xiang Wang, and Ryan Tibshirani. Graph sparsifi-
cation approaches for laplacian smoothing. In Artificial Intelligence and
Statistics, pages 1250–1259, 2016.
[87] Bidisha Samanta, Abir De, Gourhari Jana, Pratim Kumar Chattaraj,
Niloy Ganguly, and Manuel Gomez Rodriguez. Nevae: A deep generative
model for molecular graphs. In The Thirty-Third AAAI Conference on
Artificial Intelligence, AAAI, pages 1110–1117, 2019.
[88] Lawrence K Saul and Michael I Jordan. Mixed memory markov models:
Decomposing complex stochastic processes as mixtures of simpler ones.
Machine learning, 37(1):75–87, 1999.
[89] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and
Gabriele Monfardini. The graph neural network model. IEEE Transac-
tions on Neural Networks, 20(1):61–80, 2009.
[90] Michael Sejr Schlichtkrull, Thomas N. Kipf, Peter Bloem, Rianne van den
Berg, Ivan Titov, and Max Welling. Modeling relational data with graph
convolutional networks. In Proceedings of the 15th International Confer-
ence on The Semantic Web ESWC, pages 593–607, 2018.
[91] Ida Schomburg, Antje Chang, Christian Ebeling, Marion Gremse, Chris-
tian Heldt, Gregor Huhn, and Dietmar Schomburg. Brenda, the enzyme
database: updates and major new developments. Nucleic acids research,
32(suppl 1), 2004.
[92] Prithviraj Sen, Galileo Mark Namata, Mustafa Bilgic, Lise Getoor, Brian
Gallagher, and Tina Eliassi-Rad. Collective classification in network data.
AI Magazine, 29(3):93–106, 2008.
[93] Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and
Stephan G¨ unnemann. Pitfalls of graph neural network evaluation. Re-
lational Representation Learning Workshop, NeurIPS, 2018.
[94] Nino Shervashidze, Pascal Schweitzer, Erik Jan van Leeuwen, Kurt
Mehlhorn, and Karsten M Borgwardt. Weisfeiler-lehman graph kernels.
Journal of Machine Learning Research, 12(Sep):2539–2561, 2011.
[95] Martin Simonovsky and Nikos Komodakis. Dynamic edge-conditioned
filters in convolutional neural networks on graphs. In CVPR, 2017.
[96] Martin Simonovsky and Nikos Komodakis. Graphvae: Towards genera-
tion of small graphs using variational autoencoders. In Artificial Neural
Networks and Machine Learning - ICANN 2018 - 27th International Con-
ference on Artificial Neural Networks, pages 412–422, 2018.
[97] Richard Socher, Cliff C Lin, Chris Manning, and Andrew Y Ng. Pars-
ing natural scenes and natural language with recursive neural networks.
In Proceedings of the 28th international conference on machine learning
(ICML-11), pages 129–136, 2011.
[98] Alessandro Sperduti and Antonina Starita. Supervised neural networks for
the classification of structures. IEEE Transactions on Neural Networks,
8(3):714–735, 1997.
[99] Kai Sheng Tai, Richard Socher, and Christopher D. Manning. Improved
semantic representations from tree-structured long short-term memory
networks. In Proc. of the 53rd Annual Metting on ACL and the 7th IJC-
NLP, pages 1556–1566, 2015.
[100] Ilya Tolstikhin, Olivier Bousquet, Sylvain Gelly, and Bernhard Scholkopf.
Wasserstein auto-encoders. 2018.
[101] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion
Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is
all you need. In Advances in neural information processing systems, pages
5998–6008, 2017.
[102] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero,
Pietro Lio, and Yoshua Bengio. Graph attention networks. In Interna-
tional Conference on Learning Representations (ICLR), 2018.
[104] S Vichy N Vishwanathan, Nicol N Schraudolph, Risi Kondor, and
Karsten M Borgwardt. Graph kernels. Journal of Machine Learning Re-
search, 11(Apr):1201–1242, 2010.
[105] Ulrike Von Luxburg. A tutorial on spectral clustering. Statistics and
computing, 17(4):395–416, 2007.
[106] Nikil Wale, Ian A Watson, and George Karypis. Comparison of descriptor
spaces for chemical compound retrieval and classification. Knowledge and
Information Systems, 14(3), 2008.
[107] Hongwei Wang, Jia Wang, Jialin Wang, Miao Zhao, Weinan Zhang,
Fuzheng Zhang, Xing Xie, and Minyi Guo. Graphgan: Graph repre-
sentation learning with generative adversarial nets. In Proceedings of the
Thirty-Second AAAI Conference on Artificial Intelligence, pages 2508–
2515, 2018.
[108] Minjie Wang, Lingfan Yu, Da Zheng, Quan Gan, Yu Gai, Zihao Ye,
Mufei Li, Jinjing Zhou, Qi Huang, Chao Ma, Ziyue Huang, Qipeng Guo,
Hao Zhang, Haibin Lin, Junbo Zhao, Jinyang Li, Alexander J Smola,
and Zheng Zhang. Deep graph library: Towards efficient and scalable
deep learning on graphs. ICLR Workshop on Representation Learning on
Graphs and Manifolds, 2019.
[109] Xiaolong Wang and Abhinav Gupta. Videos as space-time region graphs.
In Computer Vision – ECCV 2018, pages 413–431. Springer International
Publishing, 2018.
[110] Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bron-
stein, and Justin M Solomon. Dynamic graph cnn for learning on point
clouds. ACM Transactions on Graphics (TOG), 38(5):146, 2019.
[111] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang,
and Philip S Yu. A comprehensive survey on graph neural networks. arXiv
preprint arXiv:1901.00596, 2019.
[112] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang,
and Philip S. Yu. A comprehensive survey on graph neural networks, 2019.
[113] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How pow-
erful are graph neural networks? International Conference on Learning
Representations (ICLR), 2019.
[114] Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi
Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs
with jumping knowledge networks. In International Conference on Ma-
chine Learning, pages 5449–5458, 2018.
[115] Pinar Yanardag and SVN Vishwanathan. Deep graph kernels. In Proceed-
ings of the 21th ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pages 1365–1374. ACM, 2015.
[116] Pinar Yanardag and SVN Vishwanathan. Deep graph kernels. In
SIGKDD, 2015.
[117] Liang Yang, Zesheng Kang, Xiaochun Cao, Di Jin, Bo Yang, and Yuan-
fang Guo. Topology optimization based graph convolutional network. In
Proceedings of the 28th International Joint Conference on Artificial Intel-
ligence, IJCAI’19, pages 4054–4061. AAAI Press, 2019.
[118] Ruiping Yin, Kan Li, Guangquan Zhang, and Jie Lu. A deeper graph
neural network for recommender systems. Knowledge-Based Systems,
185:105020, 2019.
[119] Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L.
Hamilton, and Jure Leskovec. Graph convolutional neural networks
for web-scale recommender systems. In Proceedings of the 24th ACM
SIGKDD International Conference on Knowledge Discovery & Data
Mining, KDD ’18, pages 974–983, 2018.
[120] Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton,
and Jure Leskovec. Hierarchical graph representation learning with differ-
entiable pooling. In Advances in Neural Information Processing Systems
31, 2018.
[121] Jiaxuan You, Rex Ying, Xiang Ren, William L. Hamilton, and Jure
Leskovec. GraphRNN: Generating Realistic Graphs with Deep Auto-
regressive Models. In ICML, 2018.
[122] Bing Yu, Haoteng Yin, and Zhanxing Zhu. Spatio-Temporal Graph Con-
volutional Networks: A Deep Learning Framework for Traffic Forecasting.
In IJCAI, 2018.
[123] Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos,
Russ R Salakhutdinov, and Alexander J Smola. Deep sets. In Advances
in Neural Information Processing Systems 30, pages 3391–3401. 2017.
[124] Daniele Zambon, Cesare Alippi, and Lorenzo Livi. Concept drift and
anomaly detection in graph streams. IEEE transactions on neural net-
works and learning systems, (99):1–14, 2018.
[125] Muhan Zhang, Zhicheng Cui, Marion Neumann, and Yixin Chen. An end-
to-end deep learning architecture for graph classification. In Proceedings
of AAAI Conference on Artificial Inteligence, 2018.
[126] Si Zhang, Hanghang Tong, Jiejun Xu, and Ross Maciejewski. Graph
convolutional networks: a comprehensive review. Computational Social
Networks, 6(1):11, Nov 2019.
[127] Ziwei Zhang, Peng Cui, and Wenwu Zhu. Deep learning on graphs: A
survey. CoRR, abs/1812.04202, 2018.
[128] Zizhao Zhang, Haojie Lin, Yue Gao, and KLISS BNRist. Dynamic hyper-
graph structure learning. In IJCAI, pages 3162–3169, 2018.
[129] Dengyong Zhou, Jiayuan Huang, and Bernhard Sch¨ olkopf. Learning with
hypergraphs: Clustering, classification, and embedding. In Advances in
neural information processing systems, pages 1601–1608, 2007.
[130] Marinka Zitnik, Monica Agrawal, and Jure Leskovec. Modeling polyphar-
macy side effects with graph convolutional networks. Bioinformatics,
34(13):i457–i466, 06 2018.
[131] Daniel Z¨ ugner, Amir Akbarnejad, and Stephan G¨ unnemann. Adversarial
attacks on neural networks for graph data. In Proceedings of the 24th
ACM SIGKDD International Conference on Knowledge Discovery &
Data Mining, KDD ’18, pages 2847–2856. ACM, 2018.
