物体检测的应用已经深入到我们的日常生活中,包括安全、自动车辆系统等。对象检测模型输入视觉效果(图像或视频),并在每个相应对象周围输出带有标记的版本。这说起来容易做起来难,因为目标检测模型需要考虑复杂的算法和数据集,这些算法和数据集在我们说话的时候就已经被完善和开发了。
以下是我们今天要介绍的内容,为您全面介绍目标检测:
Introduction to object detection with deep learning
1、目标检测基础
在深入研究对象检测应用程序、用例和基本对象检测方法之前,对对象检测本身有一个明确的理解是至关重要的。该术语通常与图像分类、对象识别、分割等技术交替使用。然而,必须承认,上面提到的许多任务都是单独的任务,通常属于目标检测。将它们彼此等同使用是不准确的,因为它们都涉及同样重要的任务。

什么是目标检测
目标检测是一种深刻的计算机视觉技术,专注于识别和标记图像、视频甚至实时镜头中的对象。为了在新数据中执行这一过程,目标检测模型使用剩余的带注释的视觉图像进行训练。它变得像输入视觉效果和接收完全标记的输出视觉效果一样简单。稍后我们将更深入地讨论目标检测模型。一个关键组件是对象检测边界框,它识别带有清晰四边形标记的对象的边缘-通常是正方形或矩形。它们都伴随着对象的标签,无论是人、车还是狗来描述目标对象。边界框可以重叠以显示给定镜头中的多个对象,只要模型对其标记的项目有先验知识。
对象检测与其他任务
让我们单独分解其他计算机视觉任务,以便更好地理解每个任务:
- 图像分类(Image classification) :这是对图像中项目类别的预测。例如,当您在Google上执行反向图像搜索时,您可能会收到一条提示“可能包含’ x ‘,其中’ x '是该技术检测到的图像的主要对象。图像分类可以显示图像中存在一个特定的对象,但它涉及一个主要对象,并且不提供对象在视觉中的位置。
- 分割(Segmentation):也称为语义分割,它是将具有可比属性的像素分组在一起的任务,而不是用边界框来识别对象。
- 目标定位(Object localization ):与目标检测的区别非常微妙但很明显。对象定位旨在识别图像中一个或多个对象的位置,而对象检测则识别所有对象及其边界,而不太关注位置。
2、深度学习vs机器学习
现在你已经掌握了我们对对象检测的基本介绍,现在是时候看看对象检测的两个主要模型:深度学习和机器学习。数据分析师通常认为深度学习方法是相对先进的方法,因为它被认为更直观,不需要太多的人为干预。最终,这两种方法都会产生准确的结果,但这次我们将专注于用深度学习进行对象检测。
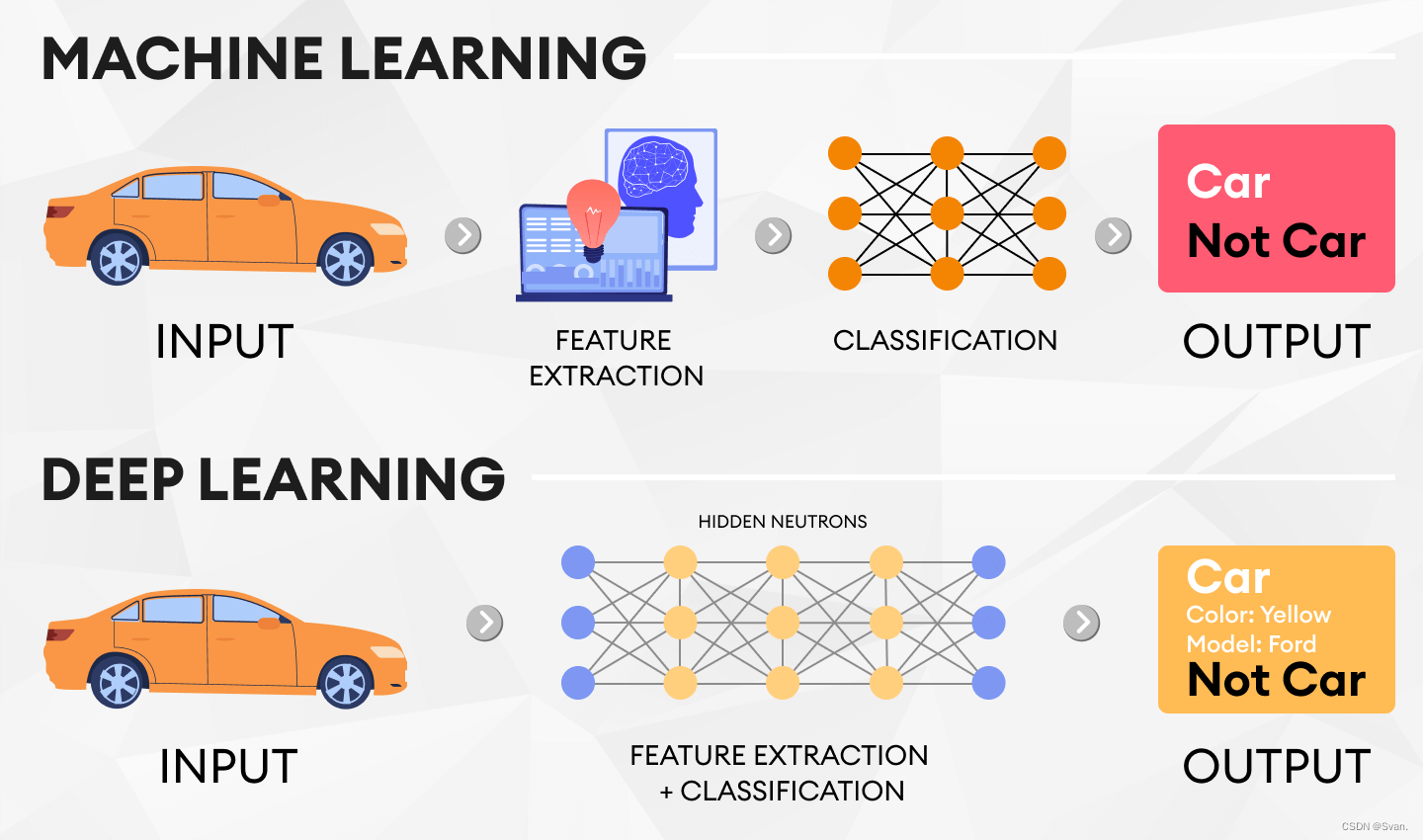
什么是深度学习的目标检测?
将深度学习的目标检测与其他方法区分开来的是卷积神经网络(CNN)的使用。神经网络模仿了人类大脑的复杂神经结构。它们主要由输入层、隐藏内层和输出层组成。这些神经网络的学习可以是有监督的、半监督的和无监督的,指的是有多少训练数据被注释了,如果有的话(无监督)。由于cnn能够在较少的人工工程的情况下自动学习,因此用于对象检测的深度神经网络产生了迄今为止最快和最准确的单个和多个对象检测结果。有一个关于深度学习和cnn的世界需要解开,但今天我们只关注关于目标检测算法和模型的关键点。
3、方法与算法
如果没有专门为处理该任务而设计的模型,对象检测是不可能的。这些目标检测模型是用成千上万的视觉内容来训练的,以便在以后的自动基础上优化检测精度。通过随时可用的数据集(如COCO(上下文中的公共对象))的帮助,可以有效地训练和精炼模型,从而帮助您在扩展注释管道方面领先一步。
让我们仔细看看几种最突出的目标检测算法和方法。
R-CNN, Fast R-CNN, Faster R-CNN
第一个很大程度上成功的方法家族是R-CNN(基于区域的卷积神经网络),该方法于2014年提出。它超越了之前的方法,只从图像中提取了2000个区域,这被称为区域建议,而不是之前的大量区域。R-CNN的流程图如下:选择输入图像,从中提取2000个区域建议。接下来,将从每个单独的区域中提取特征,然后将其分类为已知的类之一。R-CNN的主要缺点在于,虽然提取了2000个地区的提案,但过程很长。这就是为新的和改进的快速R-CNN铺平了道路。
不仅具有大量区域的目标检测过程非常耗时,而且具有如此多区域的CNN训练也非常耗时。Fast R-CNN通过将图像输入到预训练的CNN中以生成卷积特征映射,从而大大减少了处理时间,消除了将图像分解为2000个区域建议的过程。相反,区域建议可以很容易地从特征映射中识别出来,将它们发送到RoI池层,后者从给定的区域中提取特征。然后,前一层的输出由一个完全连接的层处理,其中模型分为两个输出:一个用于通过softmax层进行类预测,另一个用于通过线性输出进行边界框预测。
从R-CNN到快速R-CNN的跳跃有多重要?CNN的训练时间从84小时下降到9小时。此外,测试时间从50秒下降到2.5秒。
后来又推出了第三款,也是更加升级的型号,被称为Faster R-CNN。该架构类似于Fast R-CNN,但有一些值得注意的调整。更快的R-CNN不使用选择性搜索,这是基于相似区域的分层分组。区域提案网络将取而代之,以便以创纪录的速度确定区域提案。它将2.5秒的测试速度从快速R-CNN降低到无与伦比的0.2秒,使其成为其前身中最快的,并且是实时目标检测的最佳选择。
YOLO
如果我们说有一个比R-CNN更快的卷积神经网络呢?嗯,有!2015年,一个神经网络家族被提出,缩写为YOLO,参考了著名的短语“你只活一次”。这依赖于一个简单的事实,即网络在输出最终图像之前只“看一眼”或通过网络一次。这允许对象检测与实时镜头,这是相当可取的监视相关的应用。由于其特殊的速度,检测到的物体的准确性低于前面提到的模型,但它仍然成功地成为其他模型中的顶级竞争者。

4、用例和应用程序
深度学习的目标检测在我们的日常生活中非常普遍,正如我们已经看到的一些例子。它在现代世界的重要性远远超过许多人最初的设想。
监视、安全和交通
撇开数据标签不谈,视频和实时镜头中的目标检测是最先进监控的基石。计算机视觉旨在不断超越预期,创新盗窃检测、交通违规、可疑的人类活动等。所有这些过程正逐渐得到比以往任何时候都更有效的监测。
汽车
对于自动驾驶来说,物体检测是必须的,以便汽车在下一刻决定是否加速、刹车或转弯。这就需要物体检测来识别一系列事物,比如汽车、行人、交通信号、道路标志、自行车、摩托车等等。
医疗
目标检测在医学领域,特别是放射学领域呈现出完美的发展。虽然这项技术不会完全取代放射科医生和其他专家对专业知识的需求,但它将大大减少每天分析数百到数千次超声波扫描,甚至x射线、核磁共振成像和CT扫描的时间。
零售
不需要人工库存检查的智能库存管理,无收银员购物体验,以及更多的零售商在他们的商店中实施对象检测计算机视觉。
5、关键的外卖
目标检测是图像分类和对象定位相结合的地方,用于解释和标记从图像到实时镜头的各种视觉效果。在过去的十年中,使用深度学习的目标检测模型在处理时间和速度上显著降低,如果没有cnn,这是不可行的。我们可以清楚地看到,从智能手机的安全功能到下一代智能汽车所依赖的基础,物体检测的应用非常普遍。毕竟,目标检测模型每天都在进化、成长和创新,以变得更加准确,并解决现代世界中更多的实时问题。
我们希望通过深度学习对目标检测的基本介绍将作为进一步建立的基础。