深度学习
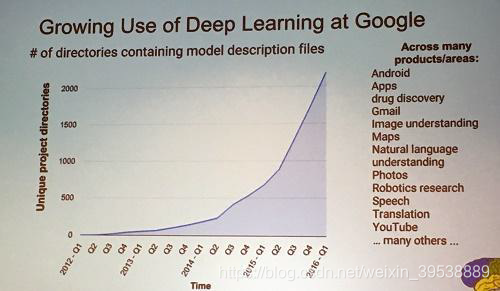
从12年开始,谷歌公司内部使用深度学习技术的project成指数增长。
深度学习的历史:
- 1958: Perceptron (linear model)
感知机(Perceptron)非常像我们的逻辑回归(Logistics Regression)只不过是没有sigmoid激活函数。 - 1969: Perceptron has limitation
- 1980s: Multi-layer perceptron
Do not have significant difference from DNN today - 1986: Backpropagation
Usually more than 3 hidden layers is not helpful - 1989: 1 hidden layer is “good enough”, why deep?
一个隐藏层可以代表任意的函数,深度学习就是个笑话 - 2006: RBM initialization (breakthrough)
并不是真正的突破,起到的效果很有限,所以现在文献中很少提了。但是提起大家Deep learning的兴趣 - 2009: GPU
GPU的发展是很关键的,使用GPU矩阵运算节省了很多的时间。 - 2011: Start to be popular in speech recognition
- 2012: win ILSVRC image competition
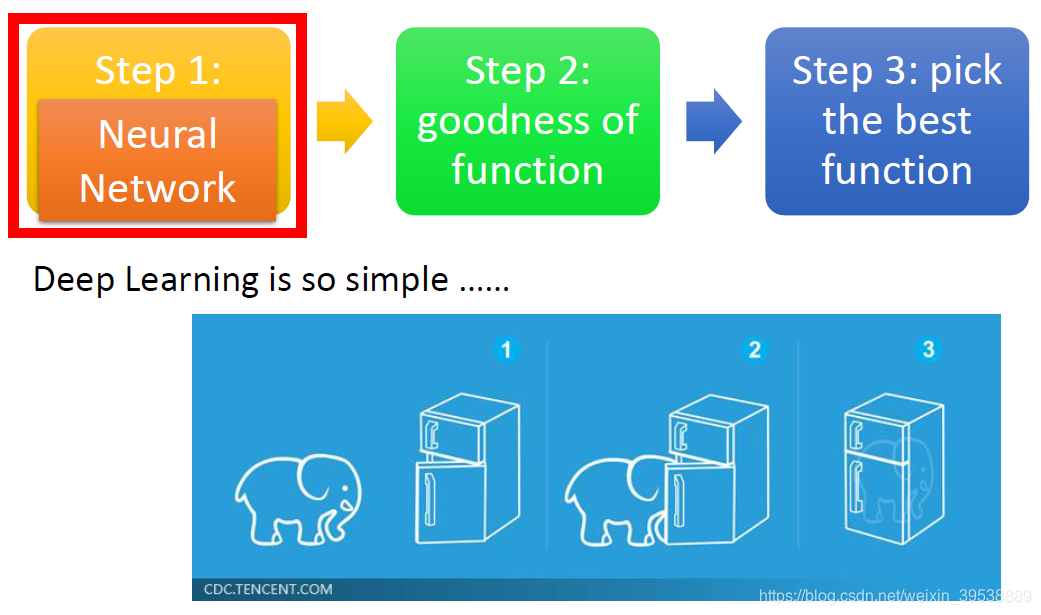
深度学习也是三步走
深度学习的Step1就是神经网络(Neural Network)
Step1:神经网络
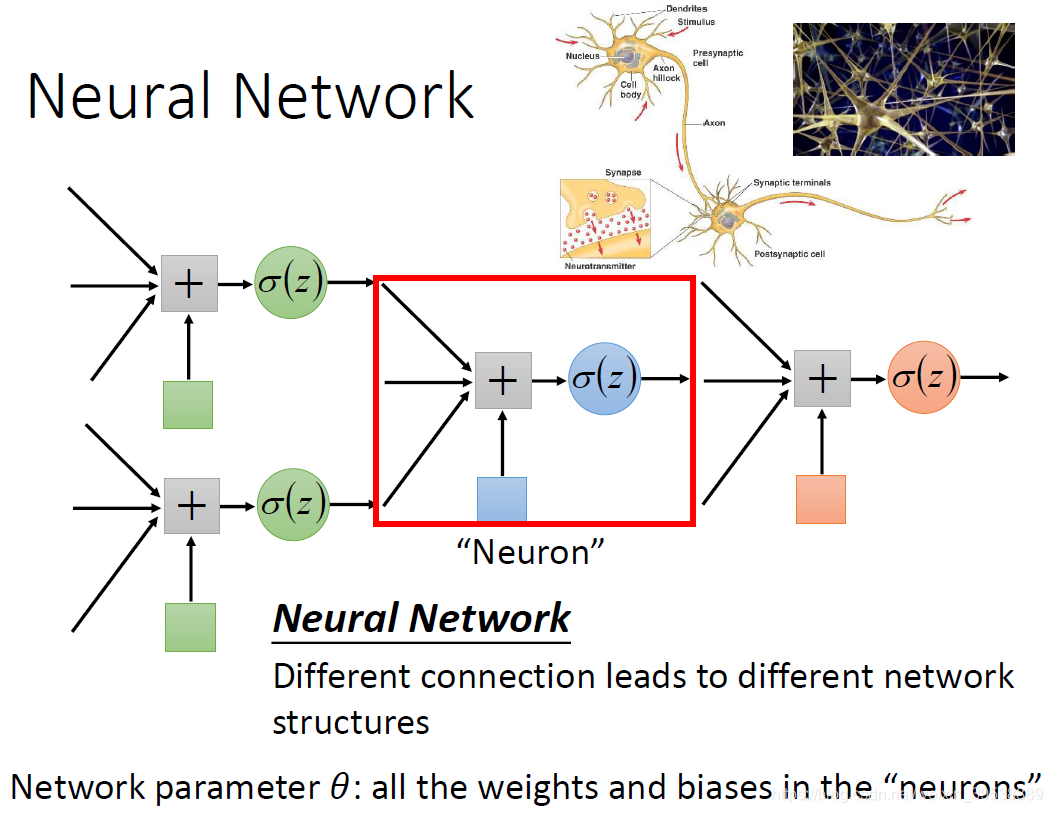
神经元可以有很多不同的连接方式,这样就会产生不同结构(structure)的神经网络。
在神经网络里面,我们有很多逻辑回归函数,其中每个逻辑回归都有自己的权重和自己的偏差,这些权重和偏差就是参数。
那这些神经元都是通过什么方式连接的呢?其实连接方式都是你手动去设计的。
全连接前馈神经网络
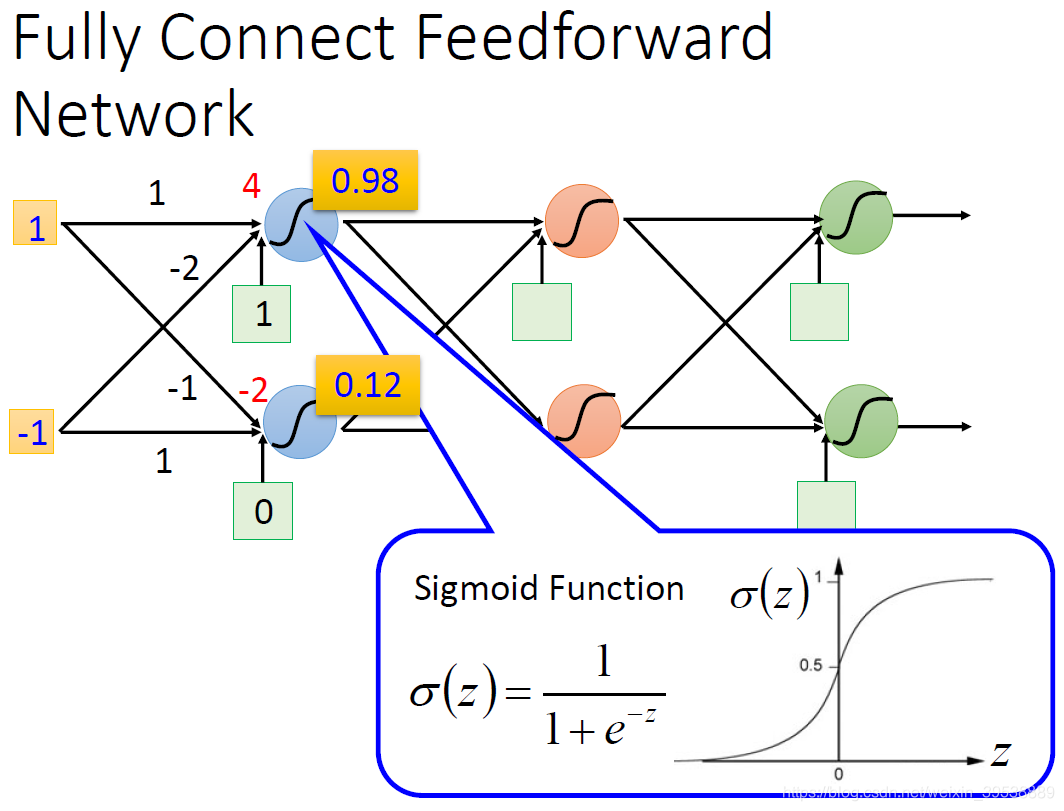
计算起来很简单,
的值代入激活函数Sigmoid得到output,然后层层传递下去。
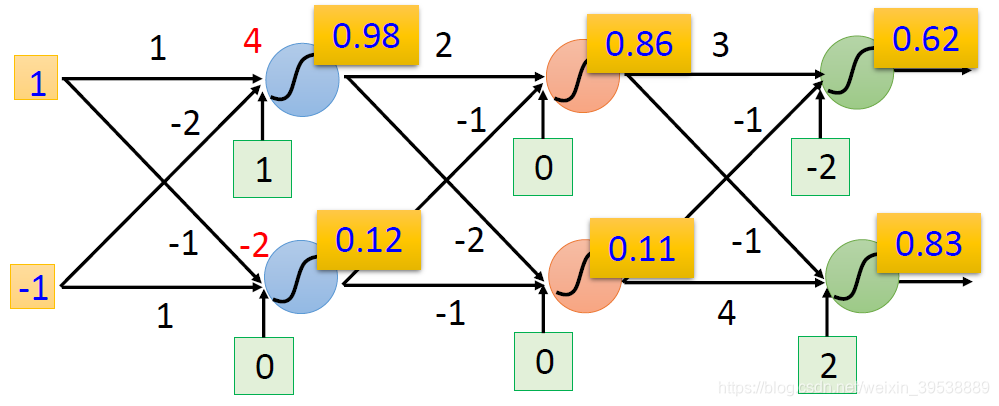
上图输入1和-1经过转换得到0.61和0.83
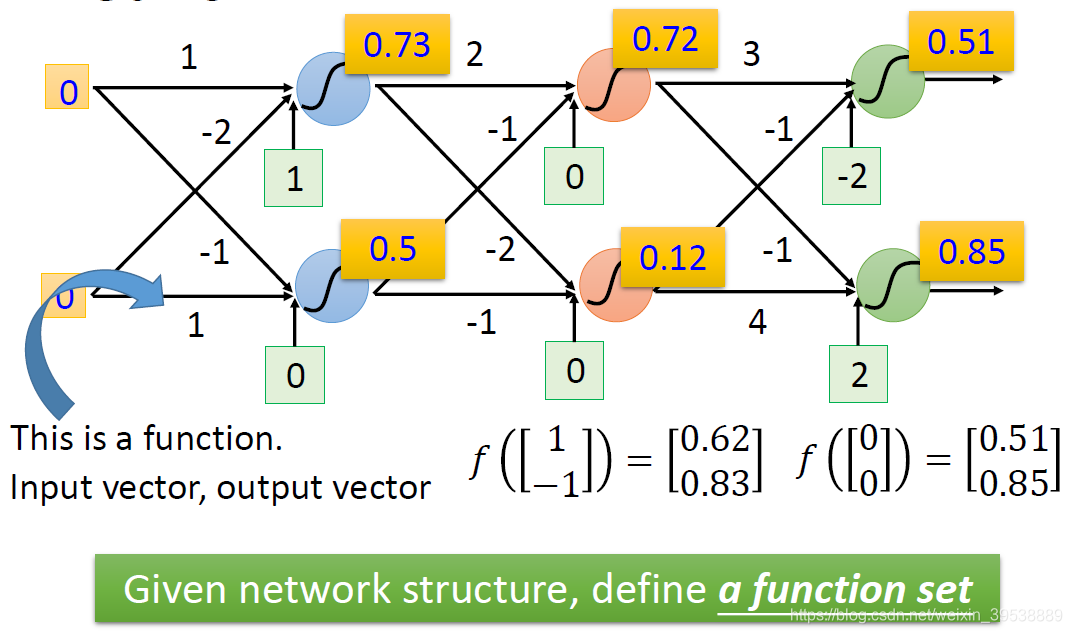
当输入0和0时,则得到0.51和0.85,,所以我们可以把神经网络当作一个函数,输入一个向量,输出一个向量。不论是做回归模型(linear model)还是逻辑回归(logistics regression)都是定义了一个函数集(function set)。我们可以给上面的结构的参数设置为不同的数,就是不同的函数(function)。这些可能的函数(function)结合起来就是一个函数集(function set)。这个时候你的函数集(function set)是比较大的,是以前的回归模型(linear model)等没有办法包含的函数(function),所以说深度学习(Deep Learning)能表达出以前所不能表达的情况。
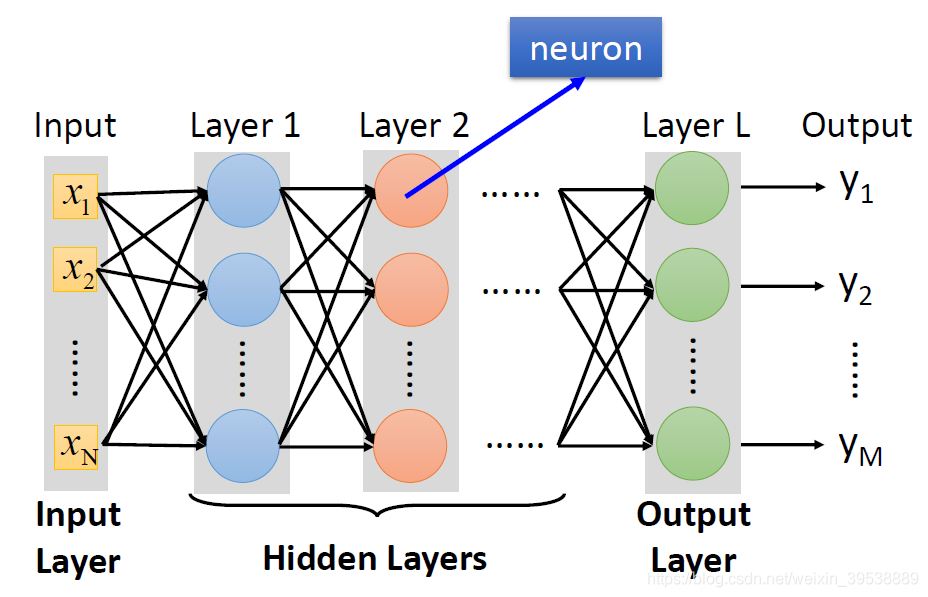
全连接前馈神经网络包含一个输入层,一个输出层和多个隐藏层。
- 为什么叫全连接呢?
相邻层之间的神经元两两之间都有连接,所以叫做Fully Connect;
- 为什么叫前馈呢?
因为现在传递的方向是由后往前传,所以叫做Feedforward。
什么是Deep?
Deep的意思就是包含很多隐藏层。那到底可以有几层呢?这个就很难说了,以下是老师举出的一些比较深的神经网络的例子 。一般只要用神经网络的方法就叫Deep。
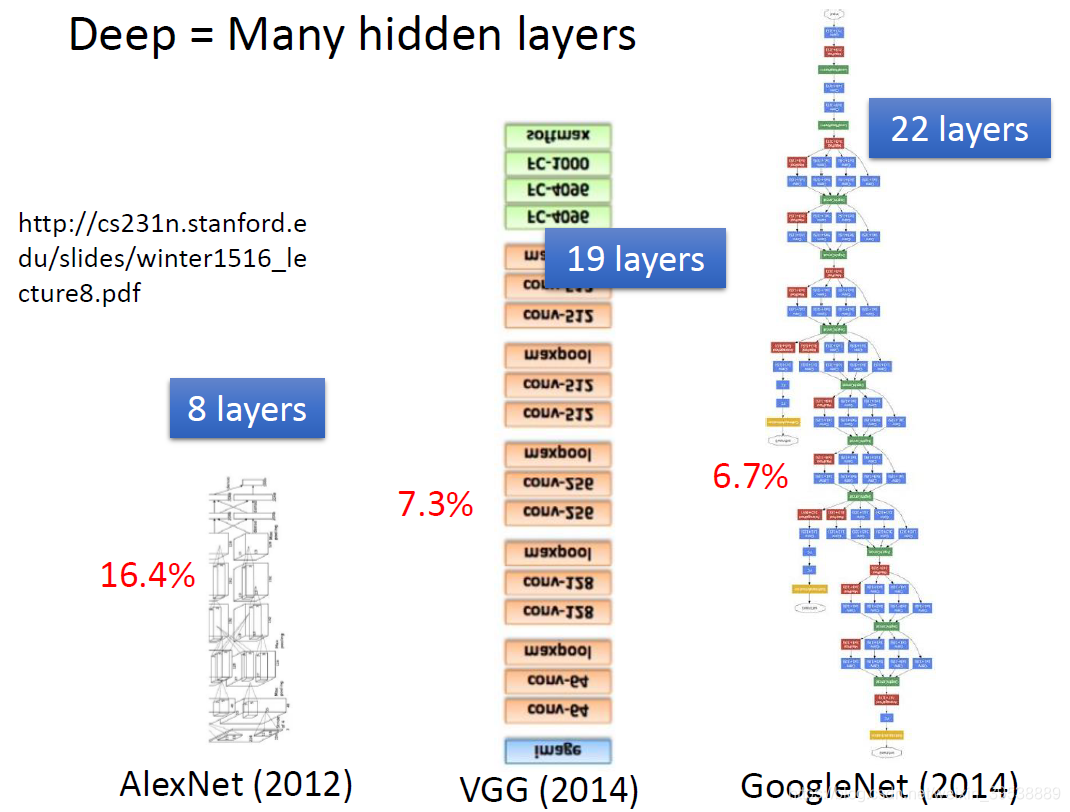
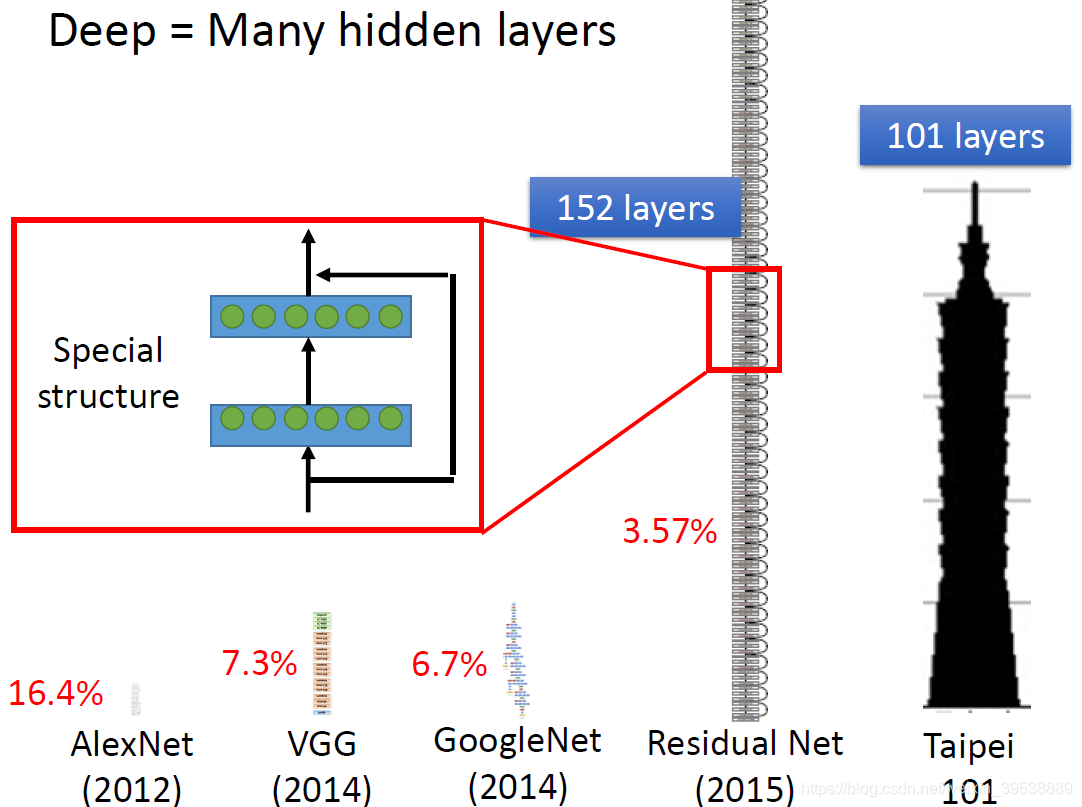
随着层数变多,运算量增大,错误率降低。对于这样复杂的结构,我们一定不会一个一个去计算,对于亿万级的计算,使用loop循环效率很低。
这里我们就引入矩阵计算(Matrix Operation)能使得我们的运算的速度以及效率高很多:
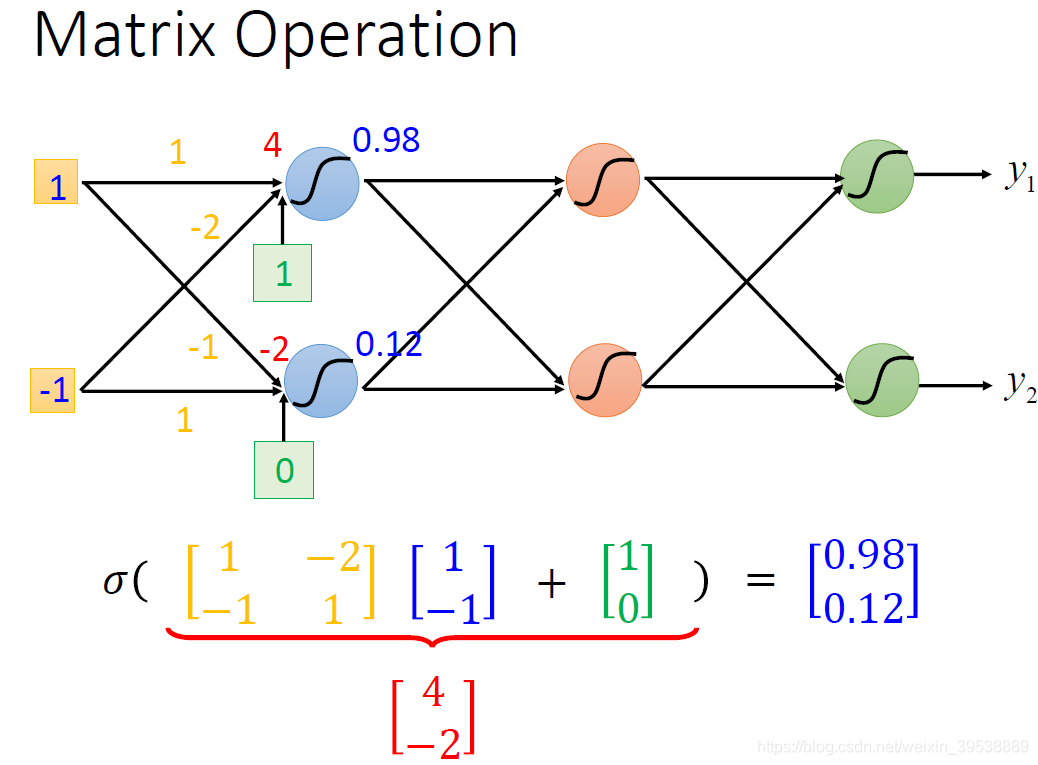
如图所示,计算方法就是:sigmoid(权重w【黄色】 * 输入【蓝色】+ 偏移量b【绿色】)= 输出
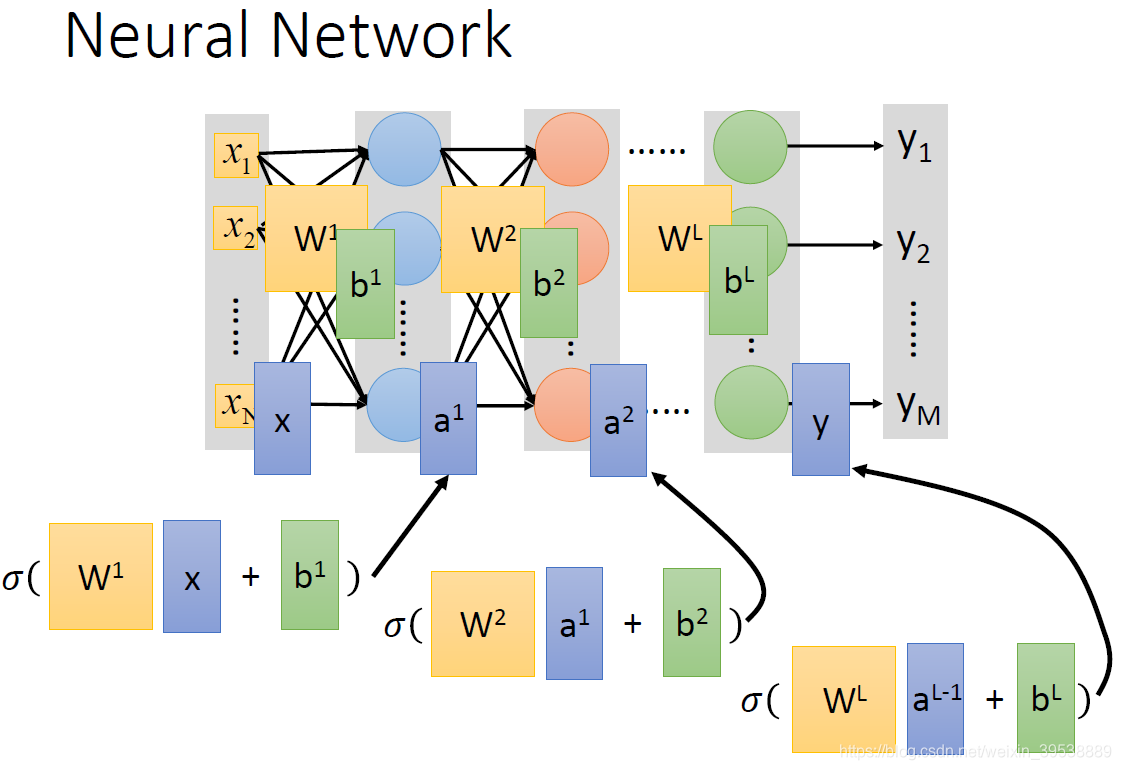
一层接一层就像是嵌套。结合上一个图更好理解。所以整个神经网络运算就相当于一连串的矩阵运算。

写成矩阵运算的好处是,你可以使用GPU加速。
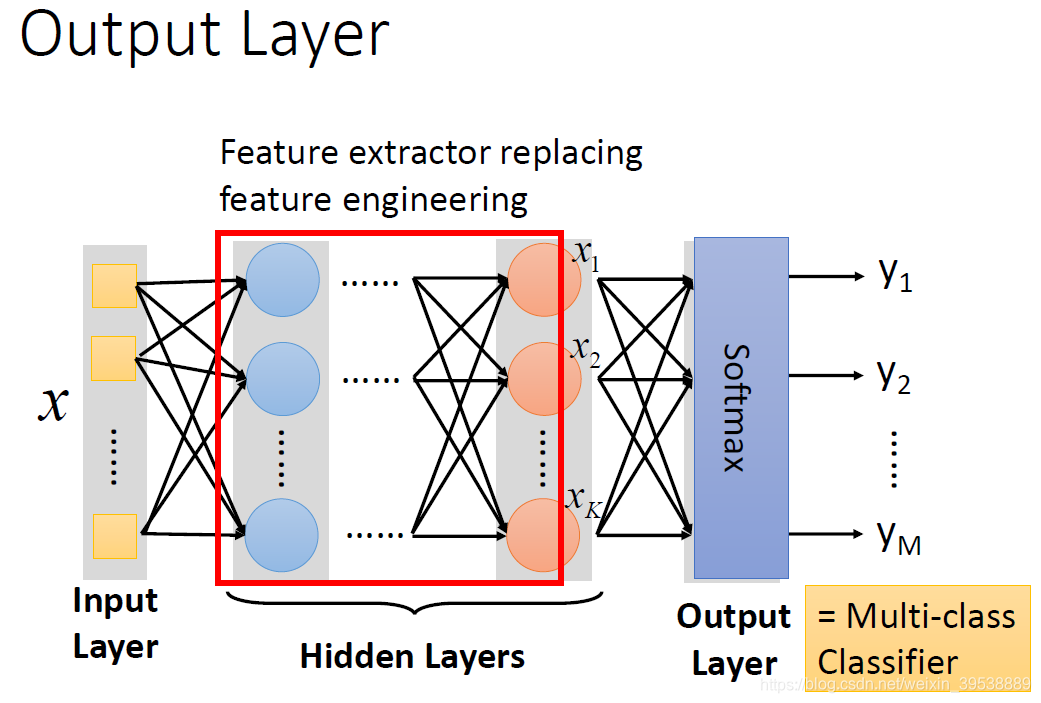
本质:通过隐藏层进行特征转换
把隐藏层通过特征提取来替代原来的特征工程,这样在最后一个隐藏层输出的就是一组新的特征(相当于黑箱操作)而对于输出层,其实是把前面的隐藏层的输出当做输入(经过特征提取得到的一组最好的特征)然后通过一个多分类器(可以是softmax函数)得到最后的输出y。
示例:手写数字识别
input:
- 是一个16*16的矩阵,对机器来说就是一个256维的input。每个pixel对应一个dimension,有颜色(ink)用1表示,没有颜色(no ink)用0表示
output:
- 对应到每个数字的几率:10个维度,每个维度代表一个数字的置信度。
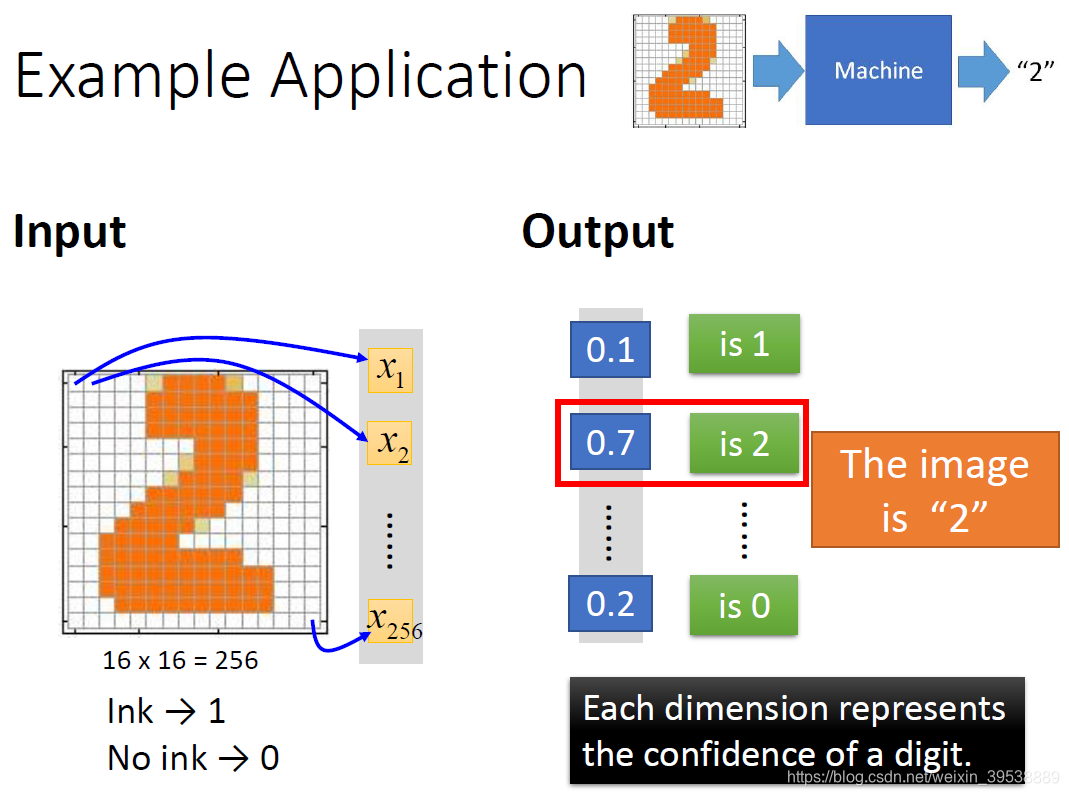
数字2的概率为0.7,最大。
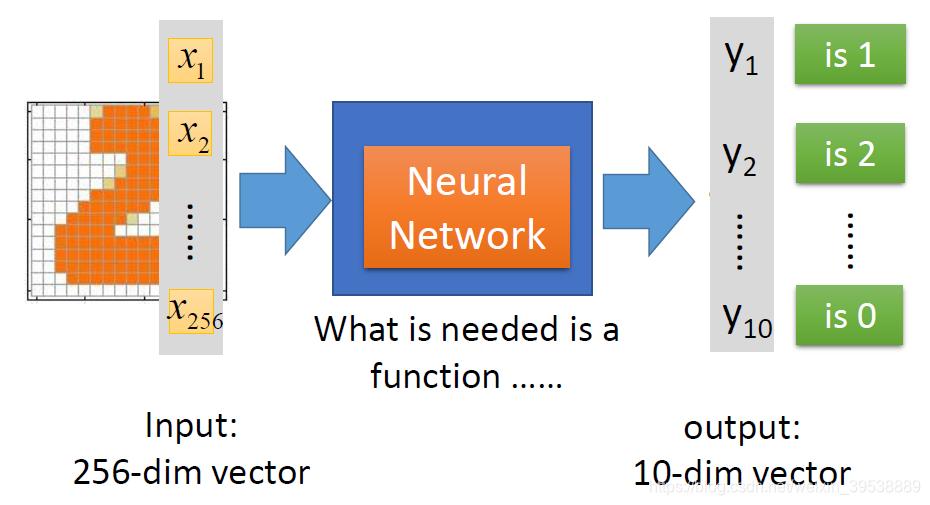
在这个问题中,唯一需要的就是一个函数,输入是256维的向量,输出是10维的向量,我们神经网络来模拟这个函数。
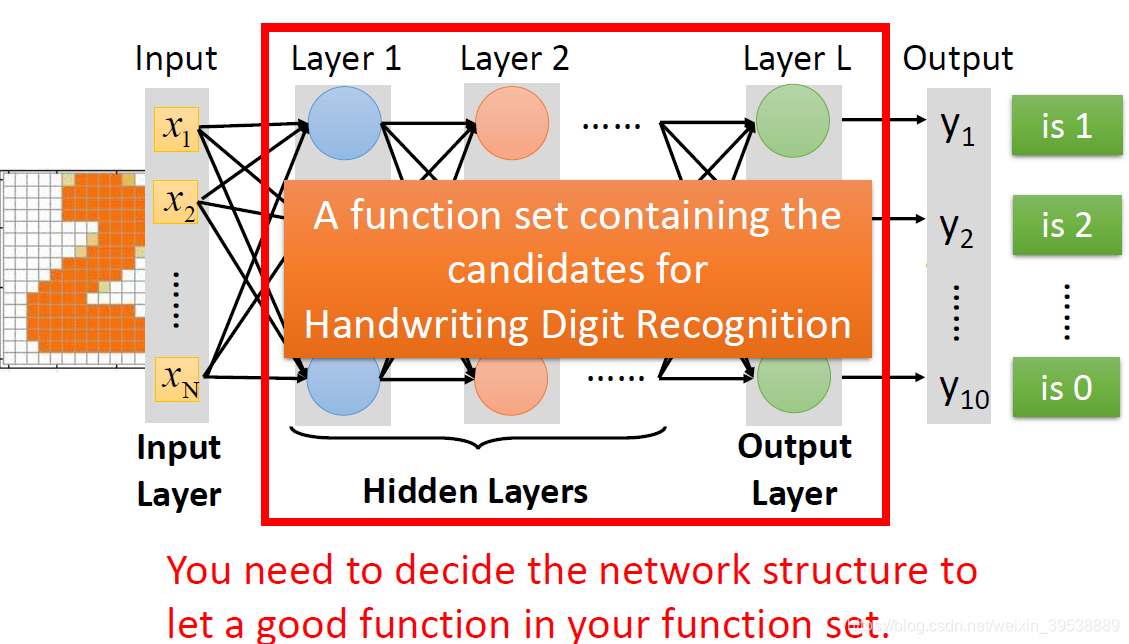
看神经网络的结构决定了函数集(function set),所以说网络结构(network structured)很关键。
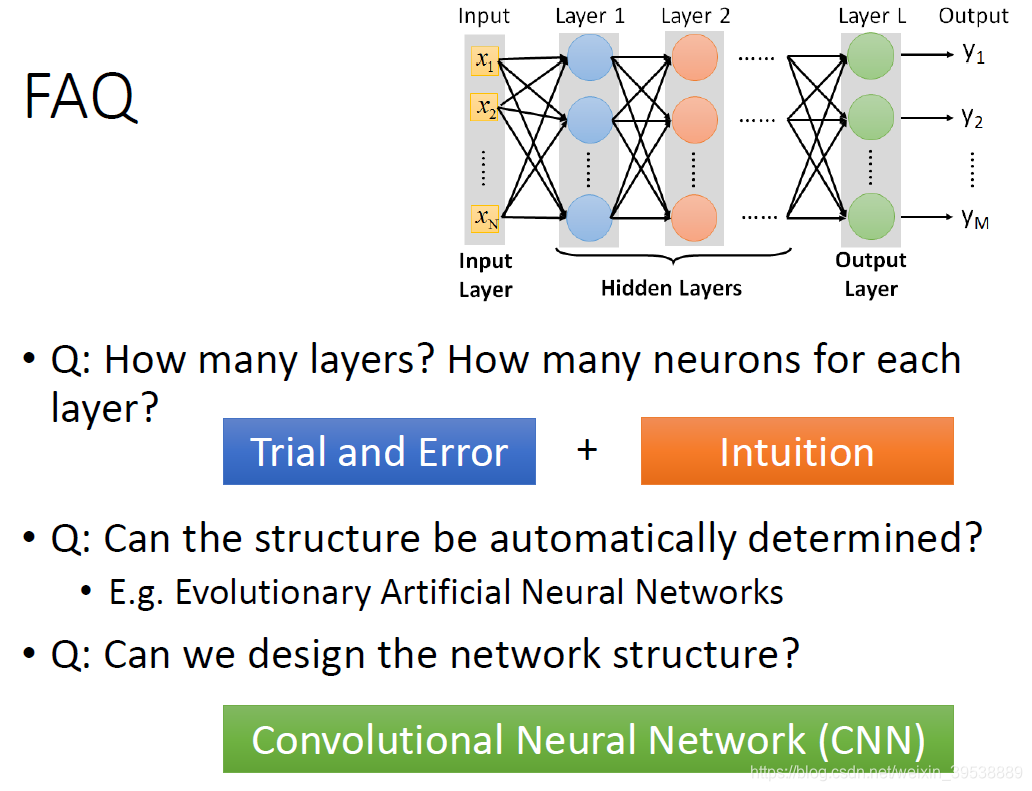
有几个问题: - 多少层? 每层有多少神经元?
这个问我们需要用尝试加上直觉的方法来进行调试。对于有些机器学习相关的问题,我们一般用特征工程来提取特征,但是对于深度学习,我们只需要设计神经网络模型来进行就可以了。对于语音识别和影像识别,深度学习是个好的方法,因为特征工程提取特征并不容易。 - 结构可以自动确定吗? 有很多设计方法可以让机器自动找到神经网络的结构的,比如进化人工神经网络(Evolutionary Artificial Neural Networks)但是这些方法并不是很普及 。
- 可以设计网络结构吗? 可以,比如 CNN卷积神经网络(Convolutional Neural Network ),下节课
Step2: 模型评估
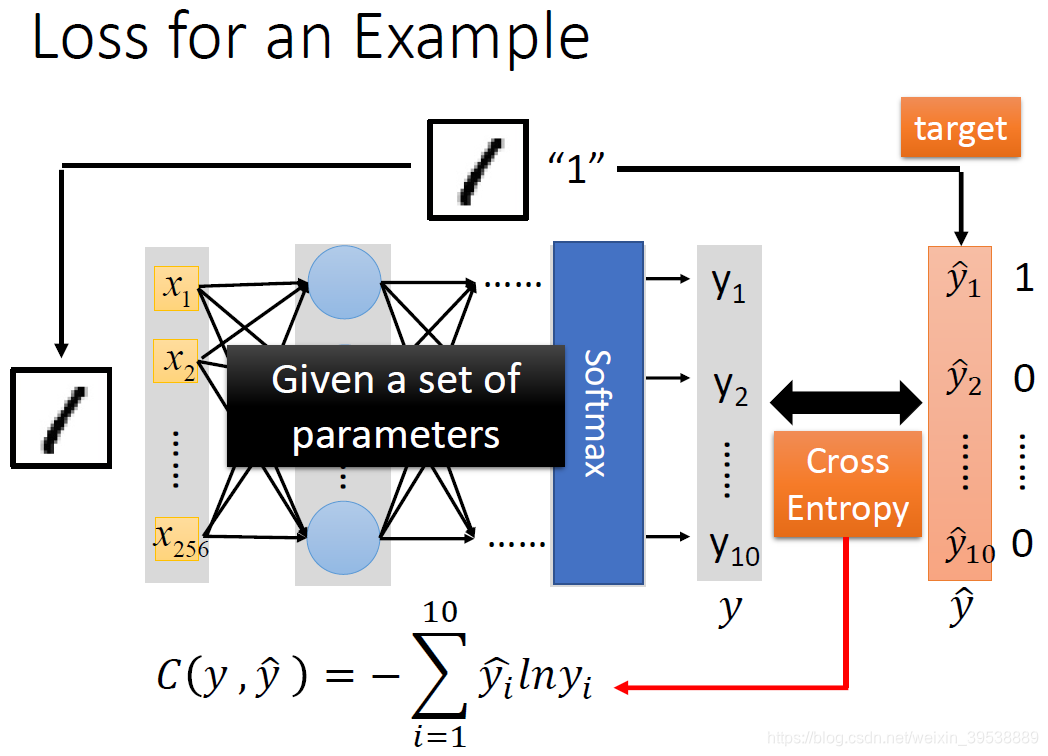
对于模型的评估,我们一般采用损失函数来反应模型的好坏。对于神经网络来说,我们采用交叉熵(cross entropy)函数来对
和
的损失进行计算,接下来我们就是调整参数,让交叉熵越小越好。
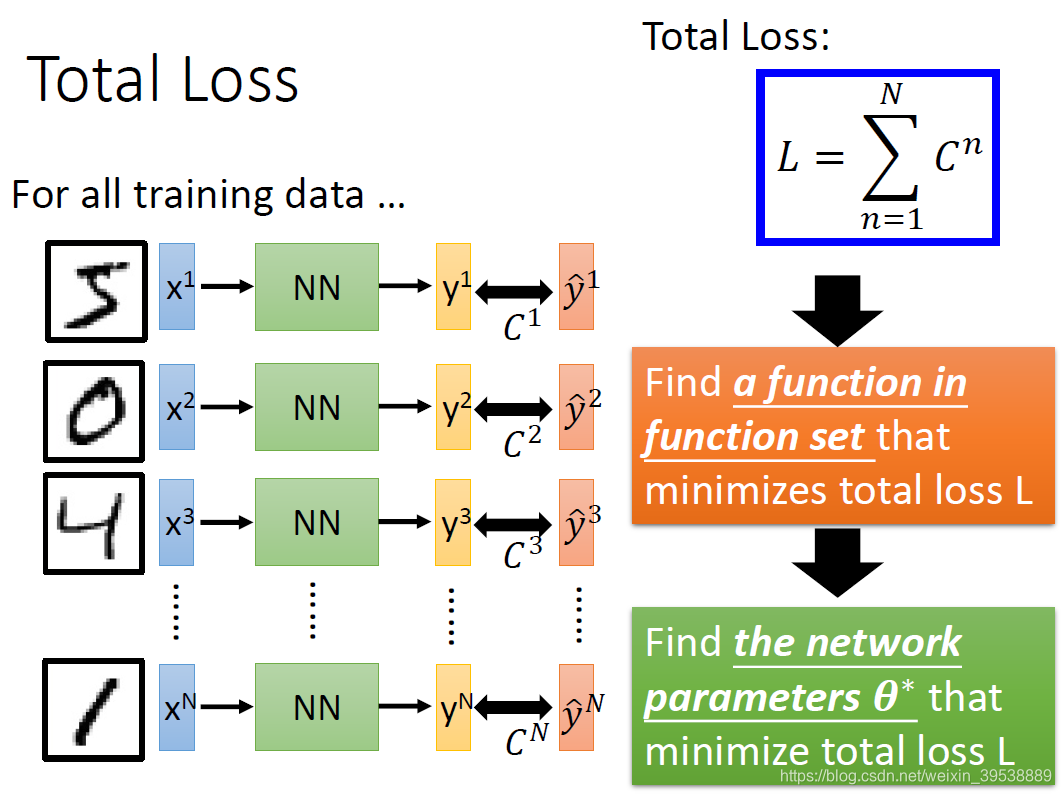
我们不是针对单个数据计算损失,而是要计算整体所有训练数据的损失。然后把所有的训练数据的损失都加起来,得到一个总体损失L。接下来就是在function set里面找到一组函数能最小化这个总体损失L,或者是找一组神经网络的参数
,来最小化总体损失L。
Step3:选择最优函数
当然是用梯度下降法。
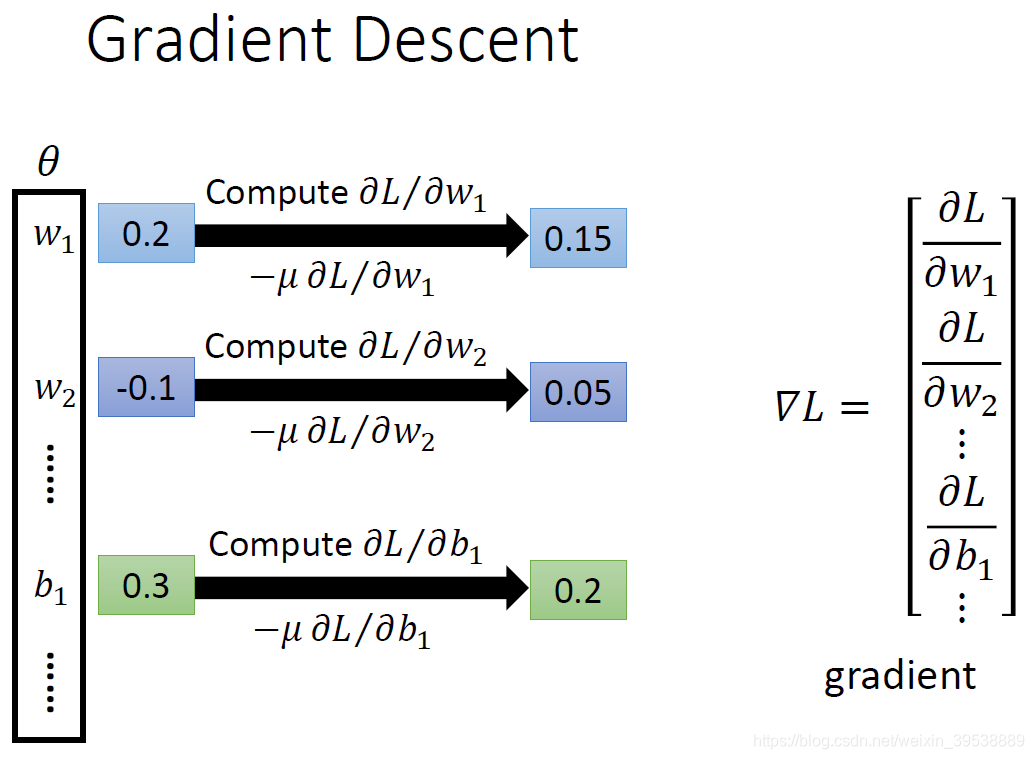

是一组包含权重和偏差的参数集合,我们随机一个初试值,然后计算每个参数对应偏微分,得到的一个偏微分的集合
就是梯度。有了这些偏微分,我们就可以不断更新梯度得到新的参数,这样不断反复进行,就能得到一组最好的参数使得损失函数的值最小 。
在神经网络中计算损失最好的方法就是反向传播,我们可以用很多框架来进行计算损失,比如说TensorFlow,theano,Pytorch等等

在下一个博客中我们会详解Backpropagation。
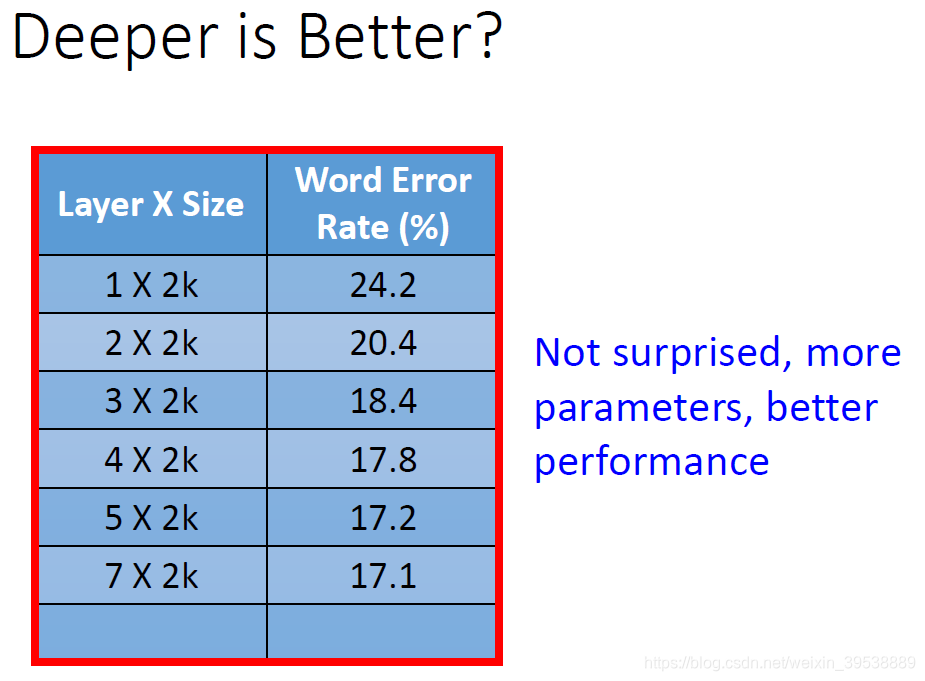
毫无疑问,层次越深效果越好

对于任何一个连续的函数,都可以用足够多的隐藏层来表示。那为什么我们还需要‘深度’学习呢,直接用一层‘fat’神经网络表示不就可以了?
再之后的一个博客我们会研究Why Deep?
参考: