本文主要目的是通过及其简单的小程序来快速学习python 中sklearn的DecisionTreeClassifier这一函数的基本操作和使用,注意不是用python纯粹从头到尾自己构建DecisionTreeClassifier,既然sklearn提供了现成的我们直接拿来用就可以了,当然其原理十分重要,这里仅给出最核心部分:
1)树以代表训练样本的单个结点开始。
2)如果样本都在同一个类.则该结点成为树叶,并用该类标记。
3)否则,算法选择最有分类能力的属性作为决策树的当前结点.
4)根据当前决策结点属性取值的不同,将训练样本数据集tlI分为若干子集,每个取值形成一个分枝,有几个取值形成几个分枝。匀针对上一步得到的一个子集,重复进行先前步骤,递4'I形成每个划分样本上的决策树。一旦一个属性出现在一个结点上,就不必在该结点的任何后代考虑它。
5)递归划分步骤仅当下列条件之一成立时停止:
①给定结点的所有样本属于同一类。
②没有剩余属性可以用来进一步划分样本.在这种情况下.使用多数表决,将给定的结点转换成树叶,并以样本中元组个数最多的类别作为类别标记,同时也可以存放该结点样木的类别分布,
③如果某一分支没有样本,则以样本的多数类创建一个树叶。
详细的实现该算法的原代码读者可以自己百度看,还是那句话本文不是介绍怎么实现而是怎样使用
代码一:主要介绍树算法的基本操作
源数据为:(第一列为身高,第二列为体重,数据不具有真实性,仅供学习使用)
1.5 50 thin 1.5 60 fat 1.6 40 thin 1.6 60 fat 1.7 60 thin 1.7 80 fat 1.8 60 thin 1.8 90 fat 1.9 70 thin 1.9 80 fat
代码:
import numpy as np
import scipy as sp
from sklearn import tree
from sklearn.metrics import precision_recall_curve
#决策树的基本操作
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
#数据读入
data = []
labels = []
with open("source _data.txt") as ifile:
for line in ifile:
tokens = line.strip().split(' ')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
x = np.array(data)
labels = np.array(labels)
y = np.zeros(labels.shape)
#标签转换为0/1
y[labels=='fat']=1
# 拆分训练数据与测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.4)
# 核心代码:使用信息熵作为划分标准,对决策树进行训练
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(x_train, y_train)
#系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大
print(clf.feature_importances_)
#将学习树结构导出到tree.dot文件
with open("tree.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
#预测结果
answer = clf.predict(x_train)
answer_proba = clf.predict_proba(x_train)#计算属于每个类的概率
print(answer)
print(answer_proba)
#sklearn中的classification_report函数用于显示主要分类指标的文本报告
#具体见https://blog.csdn.net/akadiao/article/details/78788864
answer = clf.predict(x)
print(classification_report(y, answer, target_names = ['thin', 'fat']))
运行结果:
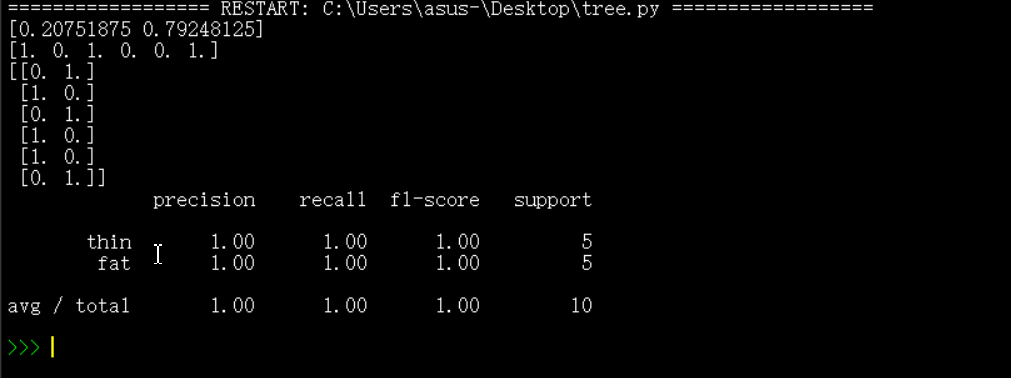
precision、recall、f1-score分别是每种类别的准确率、召回率、准确率和召回率调和平均数(下同)
代码二:
本次用到的源数据是datasets.load_iris(),iris数据集是一个字典,可以看成150行5列的二维表。150个样本,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列)iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label),其中有5个key键,data记录每个样本四个特征数值,target记录品种数(用0,1,2表示),target_names是具体品种名称,feature_names是具体的特征名称。
#利用iris数据源来预测所属花的种类 from sklearn import datasets import os import numpy as np import scipy as sp from sklearn import tree from sklearn.metrics import precision_recall_curve from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split iris=datasets.load_iris() x=np.array(iris.data) y=np.array(iris.target) # 拆分训练数据与测试数据,test_size代表学习样本占的比例,越大学习的结果越准确 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.8) # 核心代码:使用信息熵作为划分标准,对决策树进行训练 clf = tree.DecisionTreeClassifier(criterion='entropy') clf.fit(x_train, y_train) #系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 print(clf.feature_importances_) #预测 answer = clf.predict(x_train) print(answer) #sklearn中的classification_report函数用于显示主要分类指标的文本报告 #具体见https://blog.csdn.net/akadiao/article/details/78788864 answer = clf.predict(x) print(classification_report(y, answer, target_names = ['V','C','D']))
运行结果为:
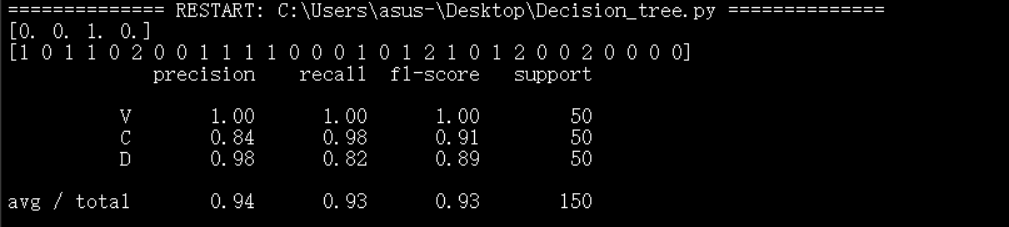
更多算法可以参看博主其他文章,或者github:https://github.com/Mryangkaitong/python-Machine-learning