随机变量分类
随机变量的矩:
X是一个随机变量对于任何正整数n,定义
E(Xn)=∫p(x)xndx
- 一阶矩:n=1,E(X)期望(原点矩)
- 二阶矩:n=2,
E(X2)−E(X)2方差 (中心矩)
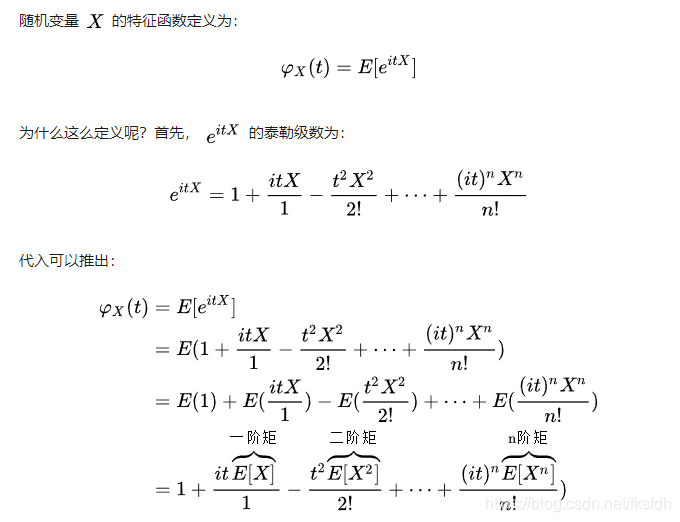
特征函数:
ϕX(t)=E(eitX)=
∑n=0∞n!E(Xn)(it)n
更多关于特征函数
协方差:(多个随机变量之间的关系)
X,Y为两个独立随机变量,协方差为0
E(x,y)=∫y∫xxyp(x,y)dxdy=∫yp(y)∫xp(x)dxdy=∫yp(y)E(x)dy=E(x)∫yp(y)dy=E(x)E(y)
cov(x,y)=E(xy)−E(x)E(y)=0
x,y的相关系数(夹角cosα)
cov(x,y)/var(x)var(y)
概率分布与特征函数的关系:
对于任何X,
ϕx(t)都存在
ϕ(0)=E(e0)=1,且∣ϕ(t)∣≤1,∀t,
ϕ(t)是一致连续函数,
ϕX(t)=ϕ−X(t),所以如果X关于中心对称,那么ϕX(t)就是一个实函数
如果X的n阶矩存在,那么ϕX(t)至少n阶可微,并且E(Xn)=(−i)nϕ(n)(0)
如果X,Y是两个独立随机变量,那么ϕX+Y(t)=ϕX(t)ϕY(t)
如果ϕX(t)=ϕY(t),那么X,Y服从同一个分布
如果Xn是一个随机变量序列,而且ϕxn(t)逐点收敛于一个函数ϕ∞(t),如果ϕ∞(t)在0处连续,那么存在一个分布X∞(t),使得Xn按分布收敛于X∞(t)
特殊分布的特征函数:
独点分布p(a)=1,ϕ(t)=eiat
两点分布p(−1)=p(1)=1/2,ϕ(t)=cos(t)
正态分布,概率密度函数f(x)=2
Π1e−2x2,ϕ(t)=e−2t2
泊松分布p(n)=e−λn!λn,ϕ(t)=e−λ(1−eit)
重要极限:
limn→∞(1+1/n)n存在,且定义e=limn→∞(1+1/n)n,于是定义ex=limn→∞(1+x/n)n,limn→∞(1+x/n)n=limn→∞[(1+x/n)n/x]x=limn→∞[(1+1/m)m]x=ex
大数定律:
平均值收敛于期望
X是随机变量,μ是X的期望,
σ是X的方差,
{Xk}k=1∞
是服从X的独立同分布随机变量,那么
Xn=n∑k=1nXk依概率收敛于μ。也就是说对于任何
ε>0有
x→∞limP(∣Xn−μ∣>ε)=0
因为X具有一阶矩,所以特征函数
ϕX(t)存在一阶泰勒展开ϕX(t)=1+iμt+o(t),于是
ϕX(t)=E(exp(itn∑i=1nxi))=i=1∏nE(exp(itX/n))=(1+iμt/n+o(t/n)n)
于是
n→∞limϕX(t)=n→∞lim(1+iμt/n+o(t/n))n
这就是独点分布的特征函数,所以
X按分布收敛于独点分布。
收敛于一个常数,因为
x→∞limP(∣Xn−μ∣>ε)=0
X收敛于一个常数,所以
X=μ,也就是验证了
平均值收敛于期望值
中心极限定理:
X是随机变量,
ϕ(X)是X的特征函数,
{Xk}k=1∞
是服从X的独立同分布随机变量,那么
服从正态分布
zn=σx
(xnμ)
依分布收敛于正态分布N(0,1)
也就是说对于任何
ε>0有
n→∞limP(Zn<z)=Φ(z),∀z
其中
Φ是标准正态分布的分布函数。
x的二阶泰勒展开式
ϕx(t)=1+iμt−2σt2+o(t2)
令Y=(x−μ)/σ
E(Y)=E[σx−μ]=σ1E(x−μ)=σ1(E(X)−μ=0
E(Y2)=E(σx−μ)2=σ21[E(X2)−2μE(x)+μ2]=σ21[E(X2)−μ2]=σ21σ2=1
则,
E(Y)=0,E(Y2)=1,于是有
ϕY(t)=1−21t2+o(t2)
因为
Zn=n
Y,所以
ϕZn(t)=E(exp(iti=1∑nYi/n
))=(1−2n1t2+o(t2/n))n
Zn=n
∑i=1nYi,最后就是n
1Yi,把ϕY(t)的t换成t/n
就是Zn的函数方程
于是
n→∞limϕzn(t)=n→∞lim(1−2nt2+o(t2/n))n=e−21t2
是一个正态分布的特征函数,所以
Zn按分布收敛于正态分布。
参数估计
点估计性质:
相合性
:当样本数量趋于无穷时,估计量收敛于参数真实值。
例:当我们求解参数
θ的方程时,为什么最大值就是参数的值?
求
θ0,求极大值,就是要证明
θ0就是极大值。
最大化参数函数方程
lx(θ),也就是最大化
n1lx(θ)是一样的。
n1lx(θ)=n1i=1∑nlxi(θ)=n1i=1∑nln(fθ(xi))
这个无穷求和就收敛于期望(大数定律)
E(ln(fθ(x)))=∫xln(fθ(x))fθ0(x)dx
fθ(x)是一个函数,fθ0(x)是个值
而
θ^是
n1lx(θ)的极大值点,所以
limθ^收敛于E(ln(fθ(x)))的极大值点
所以我们只需要证明
θ0确定是
E(ln(fθ(x)))的极大值点,因为
ln(x)是个凹函数,根据琴生不等式我们有:
∫xln(fθ(x))fθ0(x)dx−∫xln(fθ0(x))fθ0(x)dx=∫xln(fθ(x)/fθ0(x))fθ0(x)dx≤ln(∫xfθ0(x)fθ(x)fθ0(x)dx)=ln(∫xfθ(x)dx)=ln(1)=0
所以:
E(ln(fθ(x)))−E(ln(fθ0(x)))≤0
θ0就是E(ln(fθ(x))的极大值点
所以求解参数方程的极大值就是求参数的真实值。
无偏性
:对于有限的样本,估计量所符合的分布之期望等于参数真实值。
例:方差的估计:
E(n1i=1∑n(xi−x)2)=E(n1i=1∑n(xi−μ+μ−x)2)=E(n1i=1∑n(xi−μ)2)−E((μ−x)2)=E((xi−μ)2)−E((μ−x)2)=σ2−var((x))≤σ2
E((xi−μ)2)=E(xi2−2μxi+μ2)=E(xi2)−2μE(xi)+μ2=E(x)2−μ2=σ2
E(n1i=1∑nn(xi−μ+μ−x)2)=i=1∑nn(xi−μ)2+i=1∑nn(μ−x)2+i=1∑nn2(xi−μ)(μ−x)=E(n1i=1∑n(xi−μ)2)+E((μ−x)2)+(−2E(μ−x)2)
E(2(μ−x)i=1∑n(n(xi−μ))=E(2(μ−x)(x−μ))=−2E(μ−x)2
所以我们倾向于低估
σ2,那么我们低估的这个值
var((x))等于多少?
令
Yi=Xi−μ,那么
x−μ=Y,所以
E((μ−x)2)=E((Y)2)
Y的特征函数是
ϕY(t)=exp(2−t2σ2)
所以
ϕY(t)=(exp(2n2−t2σ2))n=exp(2−t2(σ/n
)2)
ϕY(t)=E(exp(itY))=E(e∑k=1nnYkit)=E(k=1∏nenYkit)=k=1∏nE(enYkit)=k=1∏nΦYk(nt)=(ϕY((nt))n
于是:
var(x)=var(Y)=σ2/n,所以
E(n1∑i=1n(xi−x)2=σ2−var((x))=σ2−σ2/n=nn−1σ2
因此,
n−11∑i=1n(xi−x)2才是σ2的无偏估计值。
另一种方法:中误差
假设误差:
Δi=li−X… ①
将各式取和再除以次数n,
n[Δ]=nl−X,
然后平方:
n2[ΔΔ]=(x−x)2
改正数:
vi=x−li…②
由于①②得:
Δi=−vi+(x−x)
n[ΔΔ]=n[vv]+n2(x−x)[v]+(x−x)2
由于改正值之和为0,
[v]=0
n2[ΔΔ]=(x−x)2
n[ΔΔ]=n[vv]+(x−x)2
n[ΔΔ]=n[vv]+n2[ΔΔ]
n[ΔΔ]−n2[ΔΔ]=n[vv]
n2n[ΔΔ]−n2[ΔΔ]=n[vv]
n2(n−1)[ΔΔ]=n[vv]
n[ΔΔ]=n−1[vv]
m2=n−1[vv]
m=n−1[vv]
有效性
:如果两个参数估计量
θ^,θˇ既是相合的,又是无偏的,那么他们两个中方差较小的那一个比较好,如果
var(θ^)≥var(θˇ),那么我们就认为
θˇ比较好。
例:
设
x1……xn,来自均值为μ,方差为
σ2的总体分布的简单样本,
ω1……ωn为已知的非负权值,且满足
∑ωi=1,试比较μ两个估计
x和∑i=1nωi的大小:
因为
var(x)=nσ2,var(∑ωixi)=∑i=1nωi2σ2,也就是求
n1≤∑i=1nωi2,由于柯西不等式:
∑i=1nai2∑i=1nbi2≥(∑i=1naibi)2,令
ai=1,bi=ωi,
(1+⋯+1)(ω12+⋯+ωn2)≥(ω1+⋯+ωn)2
n∑ωi2≥1(权重之和为1)
所以:
∑ωi2≥n1,也就说明了
var(x)是更好的
渐进正态性
当样本趋于无穷时,去中心化去量纲化的估计量符合标准正态分布。
置信区间估计
