本篇博客是论文《Text Level Graph Neural Network for Text Classification》的阅读笔记。
目录
1. 简介
在上一篇博客中,我们介绍了TextGCN模型,即用GCN来做文本分类。他有如下的两个问题:
1)TextGCN为整个数据集/语料库构建一个异构图(包括(待分类)文档节点和单词节点),边的权重是固定的(单词节点间的边权重是两个单词的PMI,文档-单词节点间的边权重是TF-IDF),固定权重限制了边的表达能力,而且为了获取一个全局表示不得不使用一个非常大的连接窗口。因此,构建的图非常大,而且边非常多,模型由很大的内存消耗。
2)上篇博客也提到了,TextGCN这种类型的模型,无法为新样本(文本)进行分类(在线测试),因为图的架构和参数依赖于语料库/数据集,训练结束后就不能再修改了。(除非将新文本加入到语料库中,更新图的结构,重新训练......一般不会这样做,总之该类模型不能为新文本进行分类)
本篇论文提出了一个新的基于GNN的模型来做文本分类,解决了上述两个问题:
1)为每个输入文本/数据(text-level)都单独构建一个图,文本中的单词作为节点;而不是给整个语料库/数据集(corpus-level)构建一个大图(每个文本和单词作为节点)。在每个文本中,使用一个非常小的滑动窗口,文本中的每个单词只与其左右的p个词有边相连(包括自己,自连接),而不是所有单词节点全连接。
2)相同单词节点的表示以及相同单词对之间边的权重全局(数据集/语料库中的所有文本/数据)共享,通过文本级别图的消息传播机制进行更新。
这样就可以消除单个输入文本和整个语料库/数据集的依赖负担,支持在线测试(新文本测试);而且上下文窗口更小,边数更少,内存消耗更小。
2. 方法
- 构建文本图
记一个包含l个单词的文本为,
表示文本中第i个单词的表示(向量).初始化一个全局共享的词嵌入矩阵(使用预训练词向量初始化),每个单词/节点的初始表示从该嵌入矩阵中查询,嵌入矩阵作为模型参数在训练过程中更新。
为每个输入文本/数据构建一个图,把文本中的单词看作是节点,每个单词和它左右相邻的p个单词有边相连(包括自己,自连接)。输入文本T的图表示为:
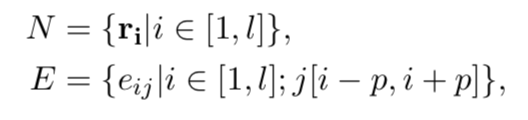
其中N和E是文本图的节点集和边集,每个单词节点的表示,以及单词节点间边的权重分别来自两个全局共享矩阵(模型参数,训练过程中更新)。此外,对于训练集中出现次数少于k(k=2)次的边(词对)均匀地映射到一个"公共边",使得参数充分学习。

其中,|V|是整个训练集中的单词数。
该方法相比于TextGCN在节点和边的角度缩减了图的规模,内存消耗更小;而且可以为新文本进行分类,每个文本对应的图在内容上是独立的。
- 消息传播机制MPM
对于文本图中每个单词节点,MPM首先基于节点之前的表示以及从该节点的邻接节点收集的信息来更新该节点的表示,定义如下:
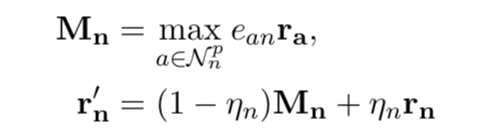
是节点n从它的邻接节点a获取的信息,即每个邻接节点a的表示乘以它们之间边的权重
(参数),再按维度取max,得到一个新的d维的表示。
是节点n之前的表示,
(训练参数)表示
中多少信息被保留,
表示节点n更新后的表示。
MPM机制通过邻接节点的表示生成当前节点的表示,意味着该表示从上下文获取信息。即使对于多义词,也能在特定上下文中通过其邻接节点的加权信息表示精准确定他的含义。此外,text-level图的参数来自全局共享矩阵,意味着这个模型也可以像其他基于图的模型(如,textGCN)一样,其表示也携带着全局信息。
- 分类
对于一个文本图中的所有节点的表示通过下式,得到对该文本的预测:
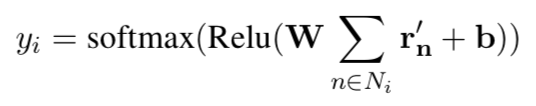
其中是把向量表示映射到输出空间的矩阵(参数),
是文本i的节点集,
是偏置。
训练的目标是最小化模型预测和真实标签(one-hot向量表示)的交叉熵损失:
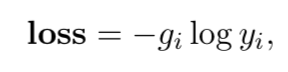
3. 实验
具体的实验配置、基准数据集介绍、baseline model介绍以及实现细节可以查看原文的3.1,3.2部分。
- 实验结果

- 内存消耗分析

- 边数分析(p值)

- 消融实验

4. 结论
本篇论文提出了一个新的基于图的文本分类模型,使用的是text-level的图(为每个输入文本构建一个图)而不是对整个语料库/数据集构建单一的图。结果表明,该模型实现了state-of-the-art的表现,并且在内存消耗方面有巨大的优势。
