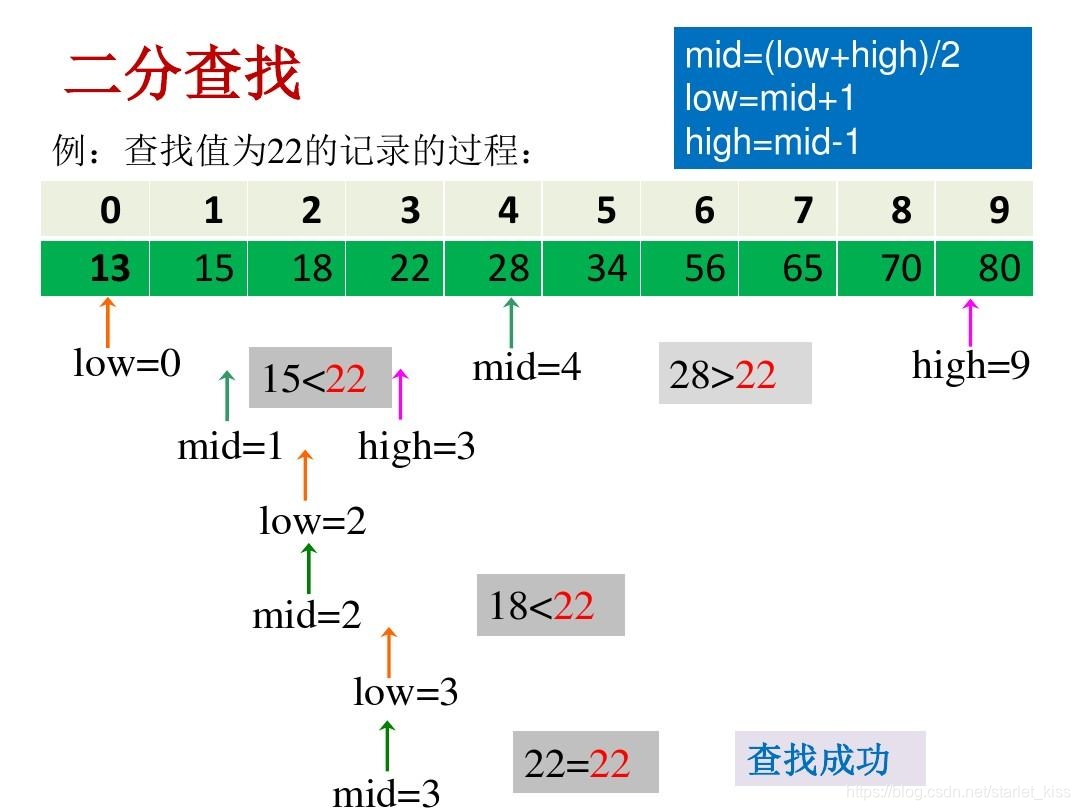
二分查找
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
查找过程
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
算法要求
1.必须采用顺序存储结构。
2.必须按关键字大小有序排列。
算法复杂度
二分查找的基本思想是将n个元素分成大致相等的两部分,取a[n/2]与x做比较,如果x=a[n/2],则找到x,算法中止;如果x<a[n/2],则只要在数组a的左半部分继续搜索x,如果x>a[n/2],则只要在数组a的右半部搜索x.
时间复杂度即是while循环的次数。
总共有n个元素,
渐渐跟下去就是n,n/2,n/4,…n/2^k(接下来操作元素的剩余个数),其中k就是循环的次数
由于你n/2^k取整后>=1
即令n/2^k=1
可得k=log2n,(是以2为底,n的对数)
所以时间复杂度可以表示O(h)=O(log2n)
二分查找图示
二分查找模板
①查找精确值,从一个有序数组中找到一个符合要求的精确值(如猜数游戏)。如查找值为Key的元素下标,不存在返回-1。
//这里是left<=right。
//考虑这种情况:如果最后剩下A[i]和A[i+1](这也是最容易导致导致死循环的情况)首先mid = i,
//如果A[mid] < key,那么left = mid+1 = i +1,如果是小于号,则A[i + 1]不会被检查,导致错误
int left = 1,right = n;
while(left <= right)
{
//这里left和right代表的是数组下标,所有没有必要改写成mid = left + (right - left)/2;
//因为当代表数组下标的时候,在数值越界之前,内存可能就已经越界了
//如果left和right代表的是一个整数,就有必要使用后面一种写法防止整数越界
int mid = (left + right) / 2;
if(A[mid] == key)
return mid;
else if(A[mid] > key)//这里因为mid不可能是答案了,所以搜索范围都需要将mid排除
right = mid - 1;
else
left = mid + 1;
}
return -1;
②查找大于等于/大于key的第一个元素。

int left = 1,right = n;
while(left < right)
{
//这里不需要加1。我们考虑如下的情况,最后只剩下A[i],A[i + 1]。
//首先mid = i,如果A[mid] > key,那么right = left = i,跳出循环,如果A[mid] < key,left = right = i + 1跳出循环,所有不会死循环。
int mid = (left + right) / 2;
if(A[mid] > key)//如果要求大于等于可以加上等于,也可以是check(A[mid])
right = mid;
//因为找的是大于key的第一个元素,那么比A[mid]大的元素肯定不是第一个大于key的元素,因为A[mid]已经大于key了,所以把mid+1到后面的排除
else
left = mid + 1;
//如果A[mid]小于key的话,那么A[mid]以及比A[mid]小的数都需要排除,因为他们都小于key。不可能是第一个大于等于key的元素,
}
③查找小于等于/小于key的最后一个元素。
int left = 1, right = n;
while(left < right)
{
//这里mid = (left + right + 1) / 2;
//考虑如下一种情况,最后只剩下A[i],A[i + 1],如果不加1,那么mid = i,如果A[mid] < key,执行更新操作后,left = mid,right = mid + 1,就会是死循环。
//加上1后,mid = i + 1,如果A[mid] < key,那么left = right = mid + 1,跳出循环。如果A[mid] > key,left = mid = i,跳出循环。
int mid = (left + right + 1) / 2;
if(A[mid] < key)
left = mid;//如果A[mid]小于key,说明比A[mid]更小的数肯定不是小于key的最大的元素了,所以要排除mid之前的所有元素
else
right = mid - 1;//如果A[mid]大于key,那么说明A[mid]以及比A[mid]还要大的数都不可能小于key,所以排除A[mid]及其之后的元素。
}
STL二分模板
①lower_bound。找到大于等于某个数的第一个位置。
头文件:algorithm。
对象:有序数组或容器。
示例代码:
//数组
#include <algorithm>
#include <iostream>
using namespace std;
int main()
{
int a[]={1,2,3,4,5,7,8,9,10};
printf("%d",lower_bound(a,a+9,6)-a);
return 0;
}
也可以对不定长数组vector进行二分搜索。
#include<iostream>
#include<algorithm>
#include<vector>
using namespace std;
int main()
{
vector<int> A;
A.push_back(1);
A.push_back(2);
A.push_back(3);
A.push_back(4);
A.push_back(5);
A.push_back(7);
A.push_back(8);
A.push_back(9);
int pos = lower_bound(A.begin() , A.end() , 6)-A.begin();//A.begin()代表的是A的迭代器
cout << pos << endl;
return 0;
}
②upper_bound。找到大于某个数的位置。
基本用法和lower_bound一样的。
STL中的这两个二分函数,是应用比较广泛的,理解他们的用处之后再去多加以应用。
努力加油a啊,(o)/~
