目录
1 ELMo(Embedding from Language Models)
2 OpenAI GPT(Generative Pre-training)
2.1 Unsupervised pre-training阶段
3 Bert(Bidirectional Encoder Representation from Transformers)
1 ELMo(Embedding from Language Models)
《Deep Contextualized Word Representations》这篇论文来自华盛顿大学的工作,最后是发表在今年的NAACL会议上,并获得了最佳论文。其实这个工作的前身来自同一团队在ACL2017发表的《Semi-supervised sequence tagging with bidirectional language models》 [4],只是在这篇论文里,他们把模型更加通用化了。首先我们来看看他们工作的动机,他们认为一个预训练的词表示应该能够包含丰富的句法和语义信息,并且能够对多义词进行建模。而传统的词向量(例如word2vec)是上下文无关的。例如下面"apple"的例子,这两个"apple"根据上下文意思是不同的,但是在word2vec中,只有apple一个词向量,无法对一词多义进行建模。

1.1 结构
在EMLo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。

考虑给定的N个词组,计算这句话出现的概率
::
(1) forward language model(前向语言模型)
Forward language model采用的是利用前面的信息估计后面的信息的方式,具体如下:
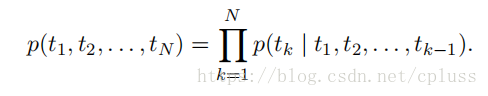
每一个t(k)出现的概率都依赖于前面的所有词语。如果采用lstm(RNN)模型的话,我们定义如下符号:表示第k个单词在第j层的输出(注意箭头的方向,LM表示language model),如果不理解层的意思,那么请去参考有关RNN的资料。
(2)backword language model
Backward language model采用的是利用后面的信息估计前面的信息的方式,具体如下(注意和forward LM比较):
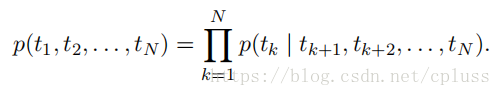
每一个t(k)出现的概率都依赖于后面的所有词语。如果采用lstm(RNN)模型的话,我们定义如下符号:表示第k个单词在第j层的输出(注意箭头的方向,代表forward或者backword)。
(3)biLM(bidirectional language model)
biLM则是整合了上面的两种语言模型,目标函数为最大化下面的log似然函数:
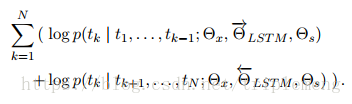
从图中可以看出,前半部分是forward language model,后半部分是backward language model。
1.2 评价

2 OpenAI GPT(Generative Pre-training)
GPT只用了Transformer-Decoder模块,单向语言模型
GPT是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训练。GPT也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。上图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:首先,特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据 单词的上下文去正确预测单词
,
之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。ELMO在做语言模型预训练的时候,预测单词
同时使用了上文和下文,而GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的,白白丢掉了很多信息。
2.1 Unsupervised pre-training阶段
第一阶段的目标是预训练语言模型,给定tokens的语料 ![]() ,目标函数为最大化似然函数:
,目标函数为最大化似然函数:
![]()
该模型中应用multi-headed self-attention,并在之后增加position-wise的前向传播层,最后输出一个分布:


2.2 Finetune阶段
有了预训练的语言模型之后,对于有标签的训练集 C ,给定输入序列 ![]() 和标签 Y,可以通过语言模型得到
和标签 Y,可以通过语言模型得到 ![]() ,经过输出层后对 Y 进行预测:
,经过输出层后对 Y 进行预测:
![]()
则目标函数为:
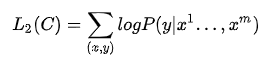
整个任务的目标函数为:
![]()

2.3 模型评价优缺点
优点:
- 循环神经网络所捕捉到的信息较少,而Transformer可以捕捉到更长范围的信息。
- 计算速度比循环神经网络更快,易于并行化
- 实验结果显示Transformer的效果比ELMo和LSTM网络更好
缺点:
- 对于某些类型的任务需要对输入数据的结构作调整
3 Bert(Bidirectional Encoder Representation from Transformers)
模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,当然另外一点是语言模型的数据规模要比GPT大。
Masked LM
Next Sentence Prediction
模型评价
优点
用的是Transformer,也就是相对rnn更加高效、能捕捉更长距离的依赖。对比起之前的预训练模型,它捕捉到的是真正意义上的bidirectional context信息。
模型有两个 loss,一个是 Masked Language Model,另一个是 Next Sentence Prediction。前者用于建模更广泛的上下文,通过 mask 来强制模型给每个词记住更多的上下文信息;后者用来建模多个句子之间的关系,强迫 [CLS] token 的顶层状态编码更多的篇章信息。文章的效果提升来自哪里?可能主要就是这两个精心设计的损失函数,尤其是前一个。
elmo、GPT、bert三者区别

它们都是基于语言模型的动态词向量。下面从几个方面对这三者进行对比:
(1)特征提取器:elmo采用LSTM进行提取,GPT和bert则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM,elmo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和bert中的Transformer可采用多层,并行计算能力强。
(2)单/双向语言模型:
- GPT采用单向语言模型,elmo和bert采用双向语言模型。但是elmo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比bert一体化融合特征方式弱。
- GPT和bert都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用decoder部分,decoder的部分见到的都是不完整的句子;bert的双向语言模型则采用encoder部分,采用了完整句子。
4 Transformer

4.1 Encoder

原始 transformer 论文中的编码器模块可以接受长度不超过最大序列长度(如 512 个单词)的输入。如果序列长度小于该限制,我们就在其后填入预先定义的空白单词(如上图中的<pad>)。
4.2 Decoder
其次是解码器模块,它与编码器模块在架构上有一点小差异——加入了一层使得它可以重点关注编码器输出的某一片段,也就是下图中的编码器-解码器自注意力(encoder-decoder self-attention)层。

解码器在自注意力(self-attention)层上还有一个关键的差异:它将后面的单词掩盖掉了。但并不像 BERT 一样将它们替换成特殊定义的单词<mask>,而是在自注意力计算的时候屏蔽了来自当前计算位置右边所有单词的信息。
5 Self-Attention
Attention机制详见博文https://zhuanlan.zhihu.com/p/37601161
5.1 Self-Attention
假设只有两个词,映射成长度只有四的向量,接下来使用三个变换矩阵,分别把每个向量变换成三个向量
这里是与设映的向量相乘得到的
得到向量之后就可以进行编码了,考虑上下文,如上文提到的bank同时有多个语义,编码这个词的时候要考虑到其他的词,具体的计算是做内积
做内积得到score,内积越大,表示约相似,softmax进行变成概率。花0.88的概率注意Thinking,0.12注意macheins这个词
就可以计算z1了,z1=0.88v1+0.12z2
z2的计算也是类似的,
实际中是多个head, 即多个attention(多组qkv),通过训练学习出来的。不同attention关注不同的信息,指代消解 上下位关系,多个head,原始论文中有8个,每个attention得到一个三维的矩阵。
将8个3维的拼成24维,信息太多 经过24 *4进行压缩成4维。
位置编码:
- 北京 到 上海 的机票
- 上海 到 北京 的机票
self-attention是不考虑位置关系的,两个句子中北京,初始映射是一样的,由于上下文一样,qkv也是一样的,最终得到的向量也是一样的。这样一个句子中调换位置,其实attention的向量是一样的。实际是不一样的,一个是出发城市,一个是到达城市。
引入位置编码,绝对位置编码,每个位置一个 Embedding
每个位置一个embedding,同样句子,多了个词 就又不一样了,编码就又不一样了
- 北京到上海的机票 vs 你好,我要北京到上海的机票
tranformer原始论文使用相对位置编码,后面的bert open gpt使用的是简单绝对位置编码:
大家可以尝试bert换一下相对位置会不会更好:
transformer 中 encoder 的完整结构,加上了残差连接和 layerNorm
5.2 Masked Self-Attention
References
https://blog.csdn.net/u014033218/article/details/88526003
