一、背景
本人在阅读大神文章《Attention is all you need》的过程中,遇到了有关attention方面的内容,尤其是对于self-attention方面的内容饶有兴趣,于是做了许多调查,下面是我的一些总结。
二、基本知识
1、Attention Mechanism
本文主要讲解Self_attention方面的内容,这方面的知识是建立在attention机制之上的,因此若读者不了解attention mechanism的话,希望你们能去略微了解一下。本人也将在这里稍微的解释一下。
对于encoder-decoder模型,decoder的输入包括(注意这里是包括)encoder的输出。但是根据常识来讲,某一个输出并不需要所有encoder信息,而是只需要部分信息。这句话就是attention的精髓所在。怎么理解这句话呢?举个例子来说:假如我们正在做机器翻译,将“I am a student”翻译成中文“我是一个学生”。根据encoder-decoder模型,在输出“学生”时,我们用到了“我”“是”“一个”以及encoder的输出。但事实上,我们或许并不需要“I am a ”这些无关紧要的信息,而仅仅只需要“student”这个词的信息就可以输出“学生”(或者说“I am a”这些信息没有“student”重要)。这个时候就需要用到attention机制来分别为“I”、“am”、“a”、“student”赋一个权值了。例如分别给“I am a”赋值为0.1,给“student”赋值剩下的0.7,显然这时student的重要性就体现出来了。具体怎么操作,我这里就不在讲了。
2、self-attention
self-attention显然是attentio机制的一种。上面所讲的attention是输入对输出的权重,例如在上文中,是I am a student 对学生的权重。self-attention则是自己对自己的权重,例如I am a student分别对am的权重、对student的权重。之所以这样做,是为了充分考虑句子之间不同词语之间的语义及语法联系。
那么这个权值应该怎么计算呢?我在别处看到的图片以及我自己的理解如下:
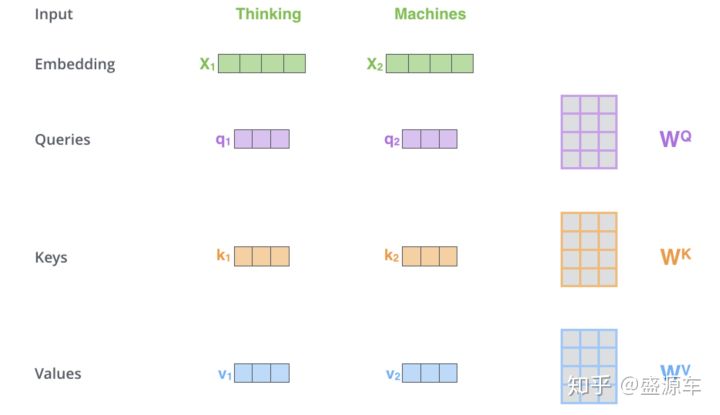
注释:q\k\v分别对应attention机制中的Q\K\V,它们是通过输入词向量分别和W(Q)、W(K)、W(V)做乘积得到的。其目的主要是计算权值。

注释:q与k做点乘、然后归一化,就得到权值(乘积越大,相似度越高,权值越高)。得到的两个权值分别与v相乘后,再相加就是输出。同理就可以得到另一个单词的输出。
以上是一个单词一个单词的输出,如果写成矩阵形式就是Q*K,得到的矩阵归一化直接得到权值。