self-attention与Transformer
文章目录
参考
整体介绍
-
之前有记过Transformer的笔记,但是属于一知半解的情况,现在看了李宏毅老师的课,对self- attention有了更深的理解,作为之前笔记的补充
-
首先,self-attention在ML中一般是以这样的方式存在
-
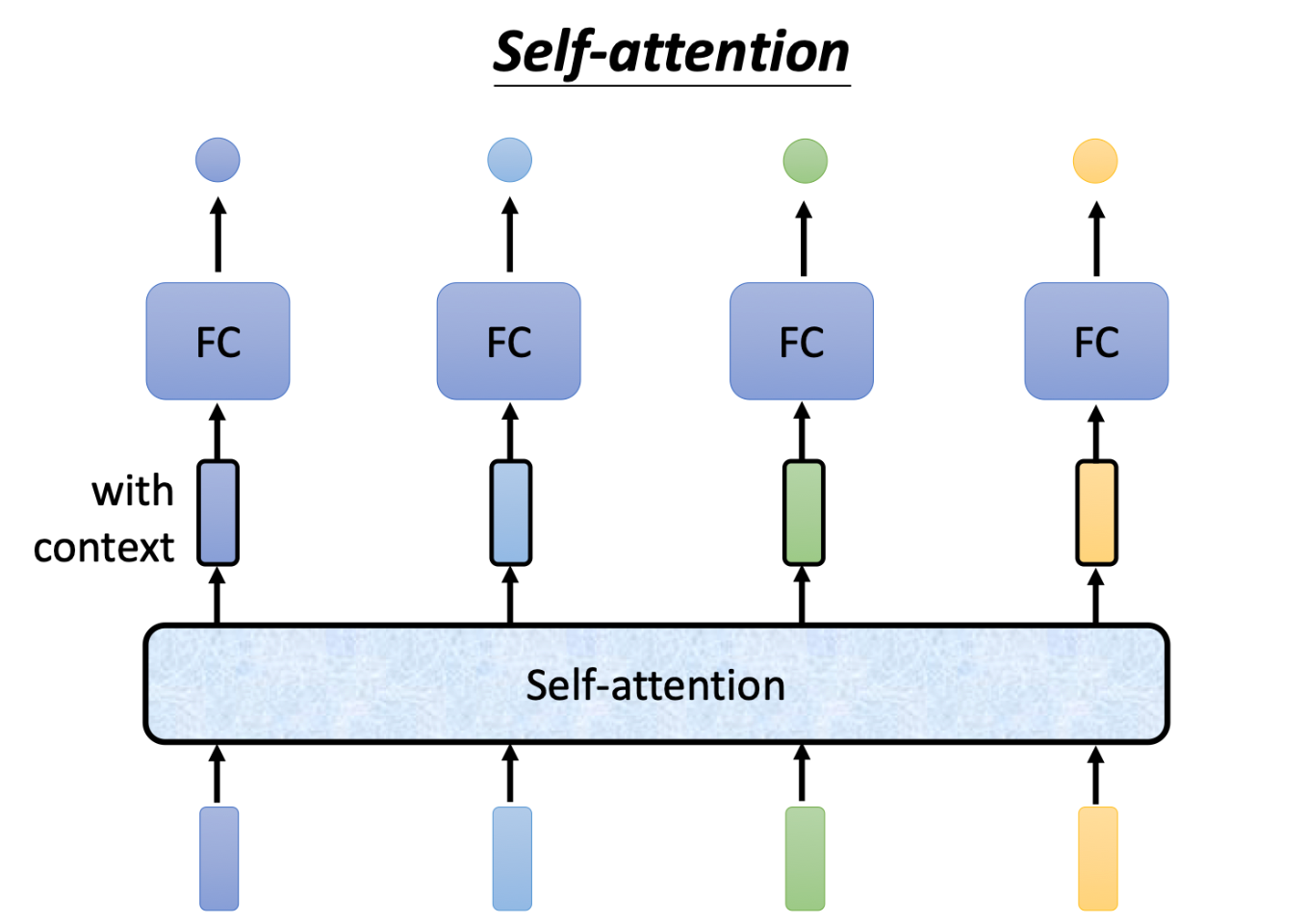
内部结构
-
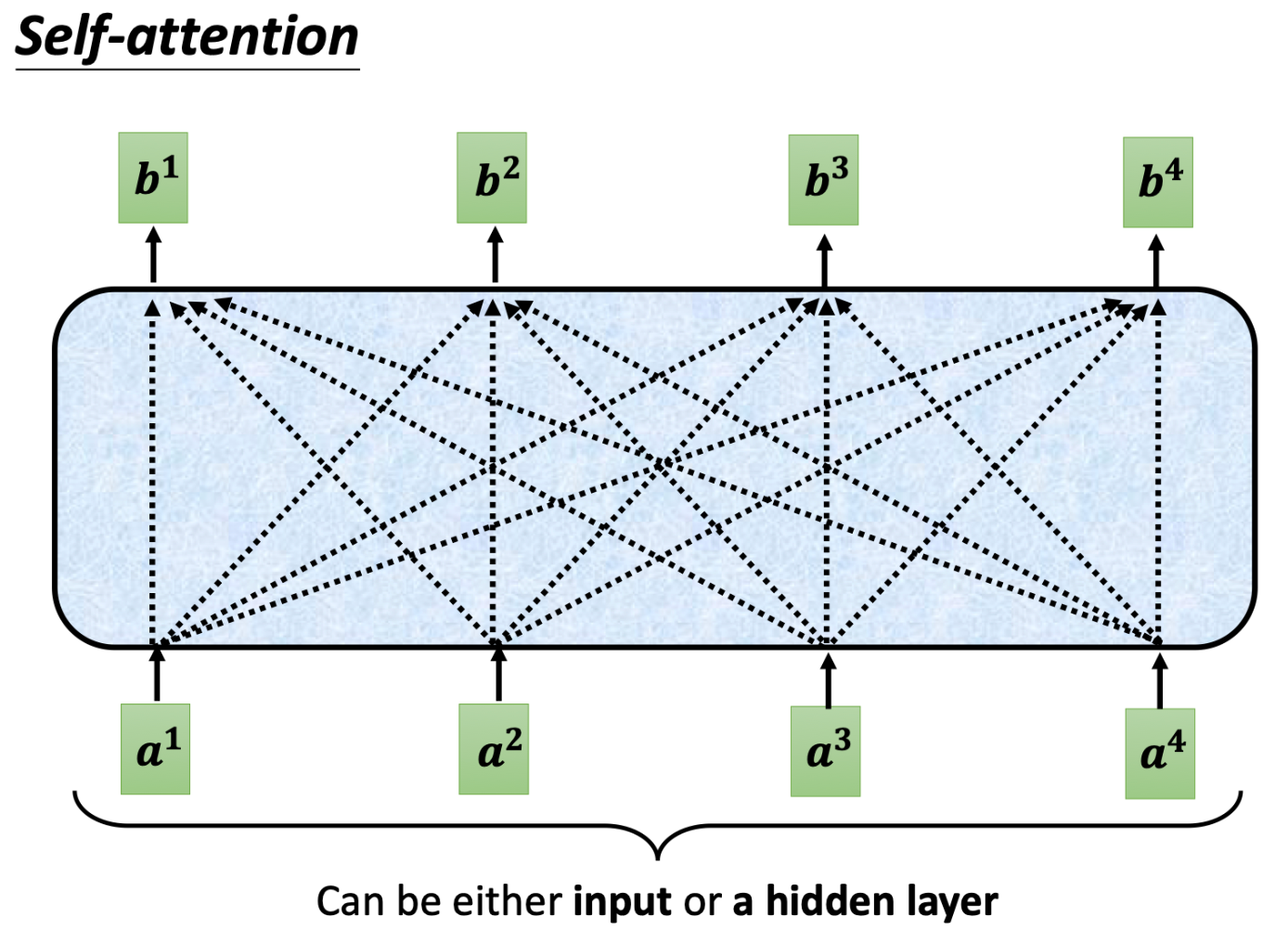
而对于输出 b 1 − b 4 b_1 - b_4 b1−b4,self-attention会考虑每个输入 a 1 − a 4 a_1 - a_4 a1−a4
-
-
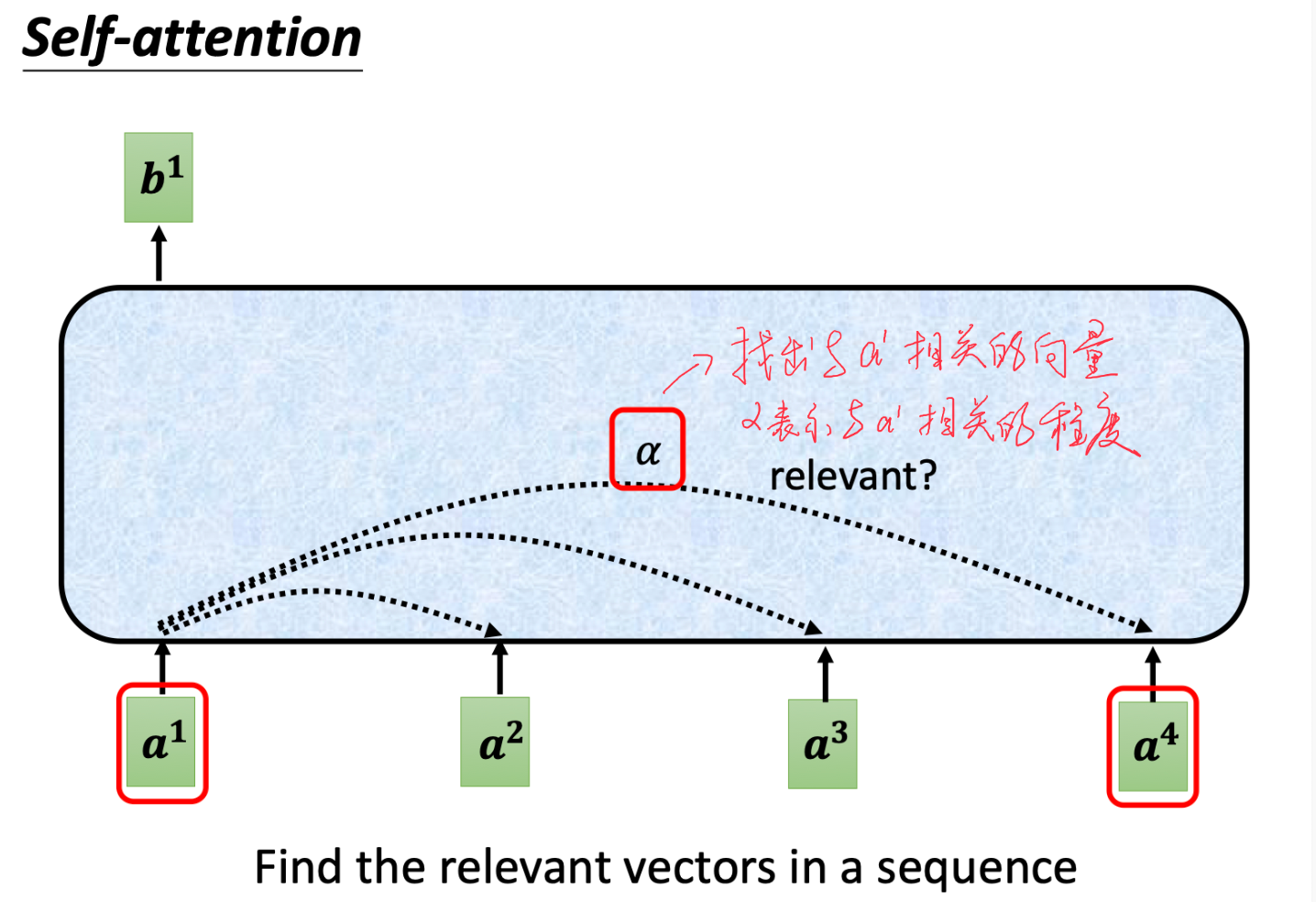
具体的方式是:寻找 a 1 − a 4 a_1 - a_4 a1−a4之间的相关性:
-
-
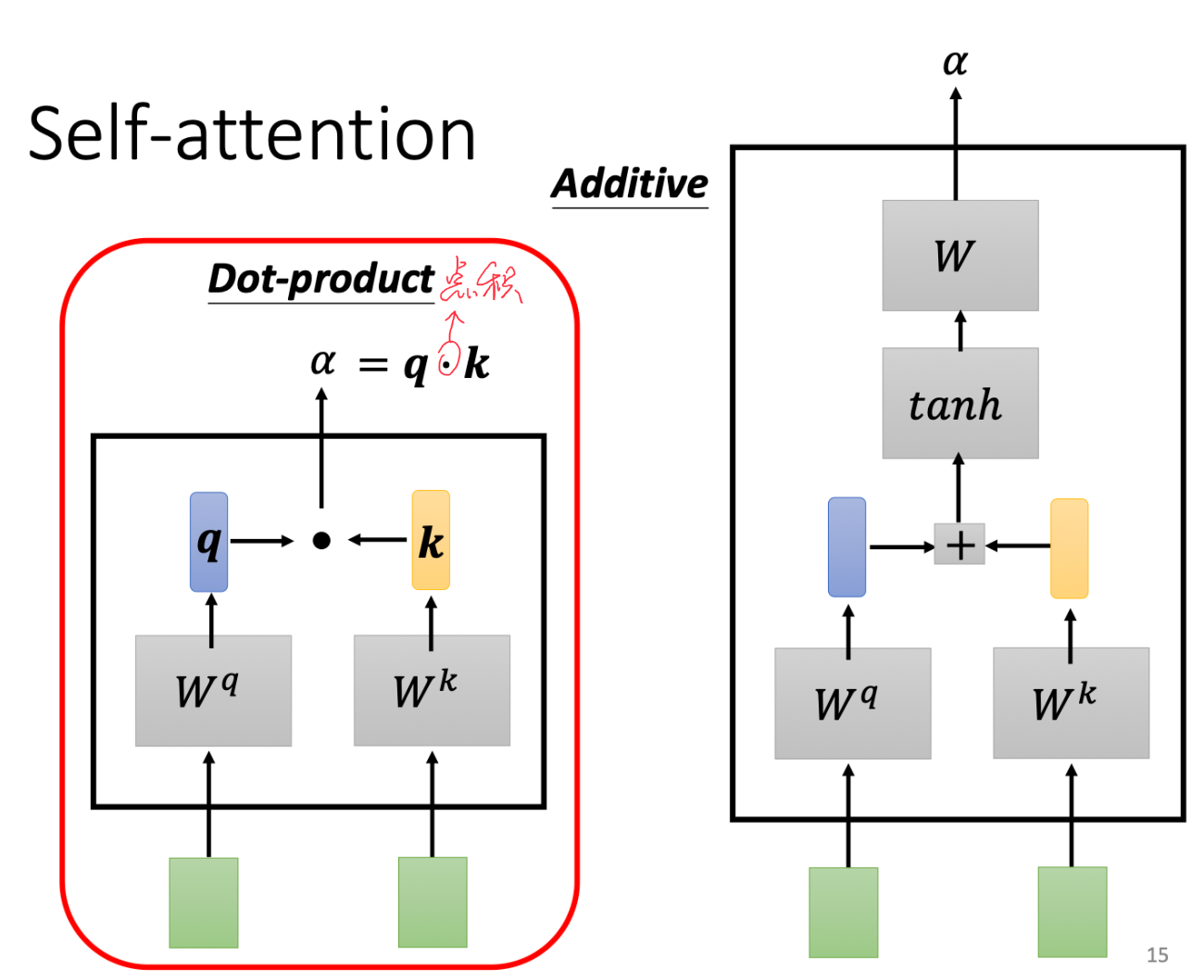
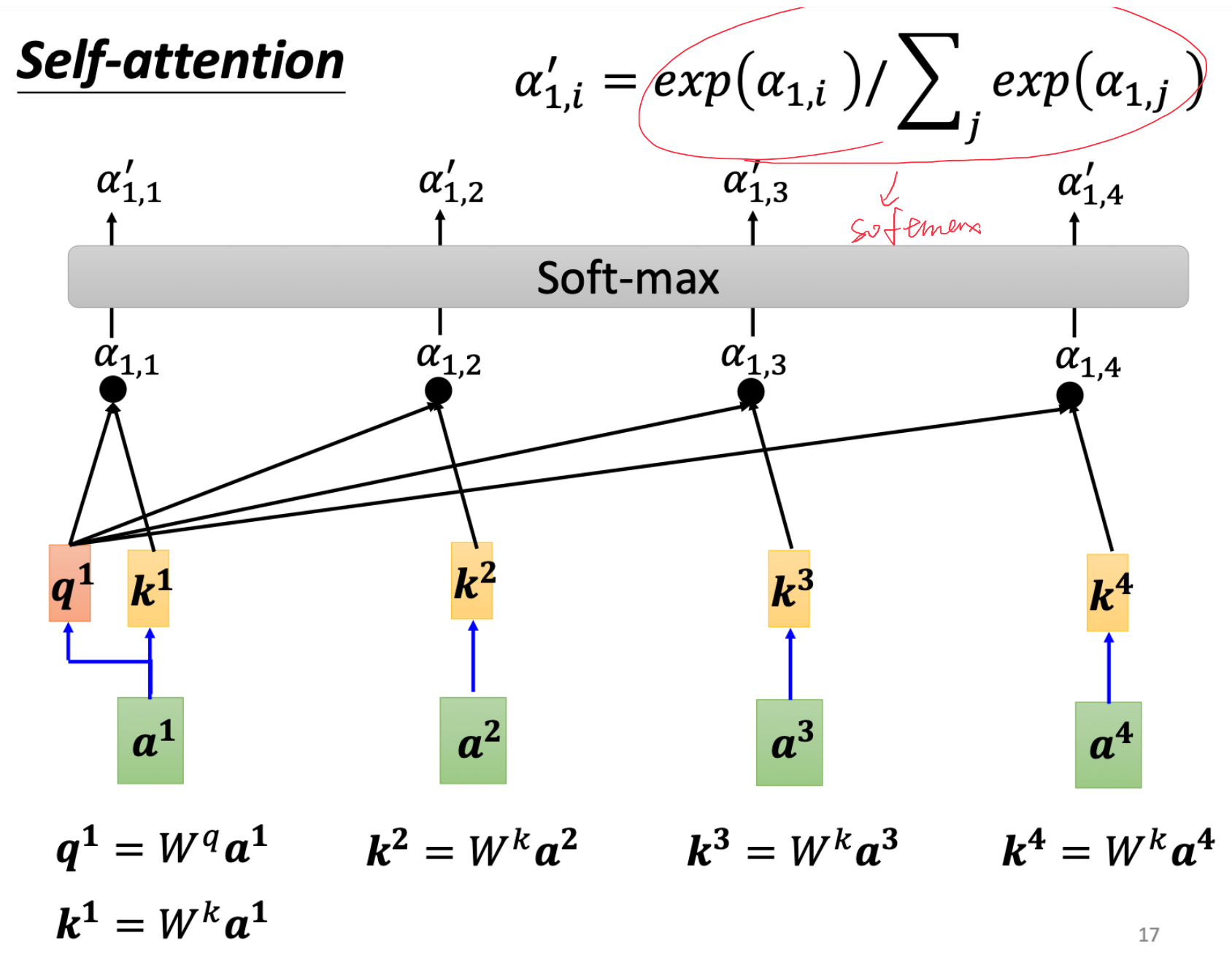
相关性对计算方式如下
扫描二维码关注公众号,回复: 13362763 查看本文章
-
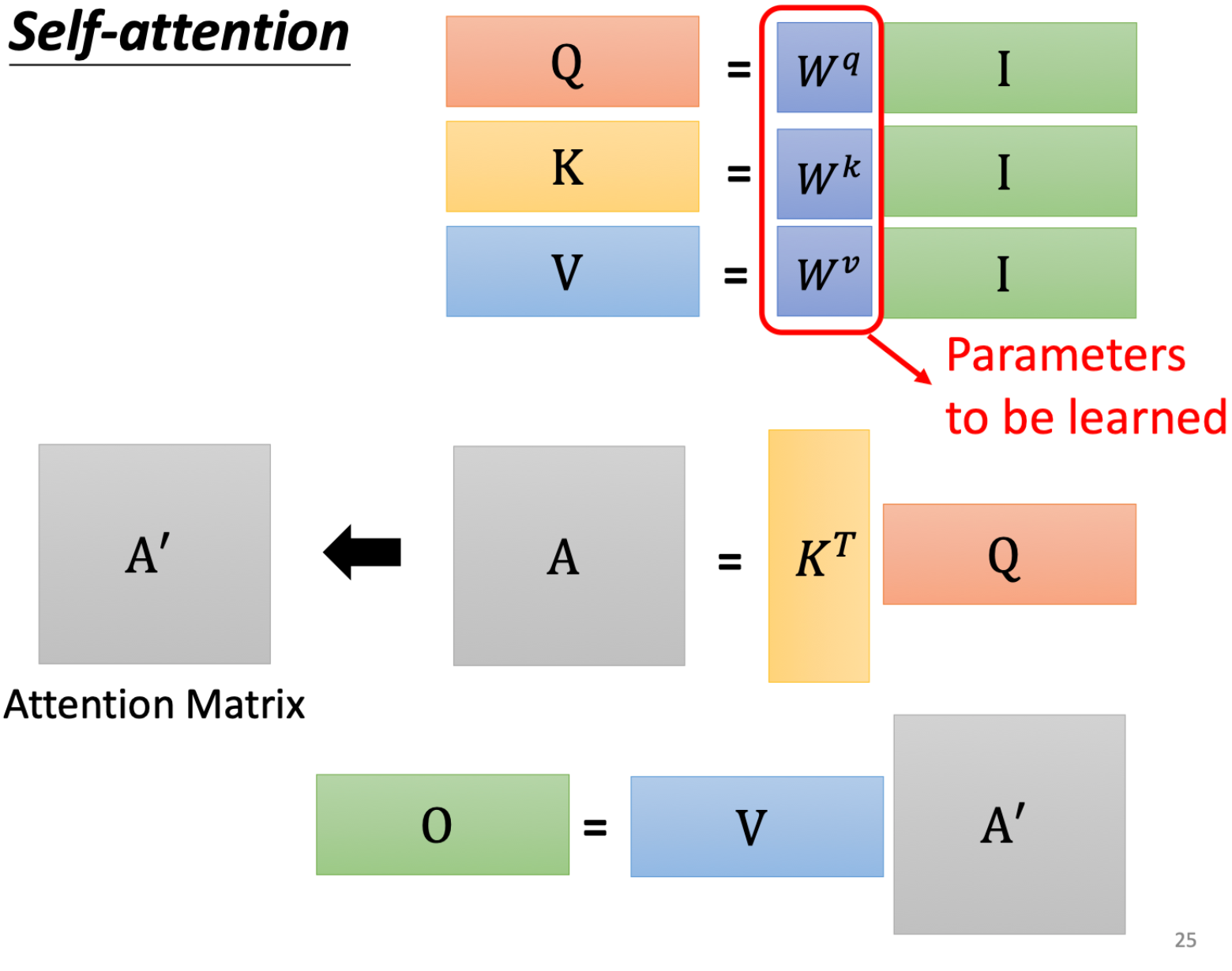
任意两个输入 a i a j a_i \quad a_j aiaj,对输出 b i b_i bi会先取得 a i a_i ai的q矩阵和 a j a_j aj的k矩阵( q = W q ∗ a i q=W_q*a_i q=Wq∗ai和 k = W k ∗ a j k=W_k * a_j k=Wk∗aj,其中W为训练出来的权重参数(就类似于CNN中Kernel中的参数一样))
-
如果使用Dot- product方法,则对qk进行点积即可
-
如果是additive方法,则计算 W ∗ t a n h ( q + k ) W*tanh(q+k) W∗tanh(q+k),其中tanh作用是将范围限制在[-1,1]之间
-
-
-
-
-
根据这个方法我们可以得到( a 1 a_1 a1为例)关于a1的所有相关性的值,再对所有值做一个softmax就可以得到这些值的score
-
-
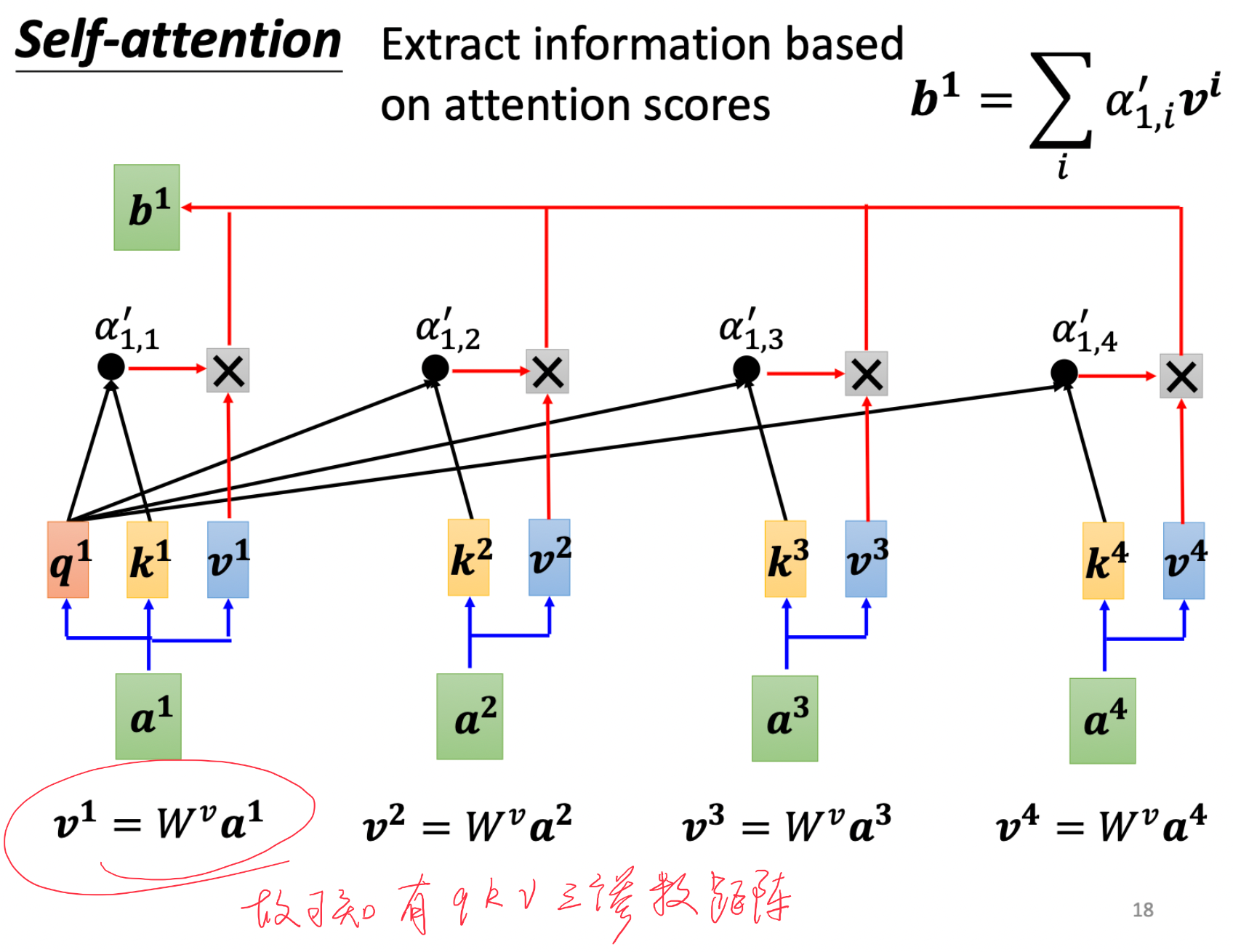
接下来就可以计算b的值: b 1 = ∑ i a 1 , i ′ v i b^1= \sum_{i} a_{1,i}^{'}v^i b1=∑ia1,i′vi其中 v i v^i vi= W v ∗ a i W^v*a_i Wv∗ai
-
-
有一点需要注意的是: W q W k W v W^q \quad W^k \quad W^v WqWkWv三个矩阵是所有输入值共享的,一个self-attention结构共享一个
-
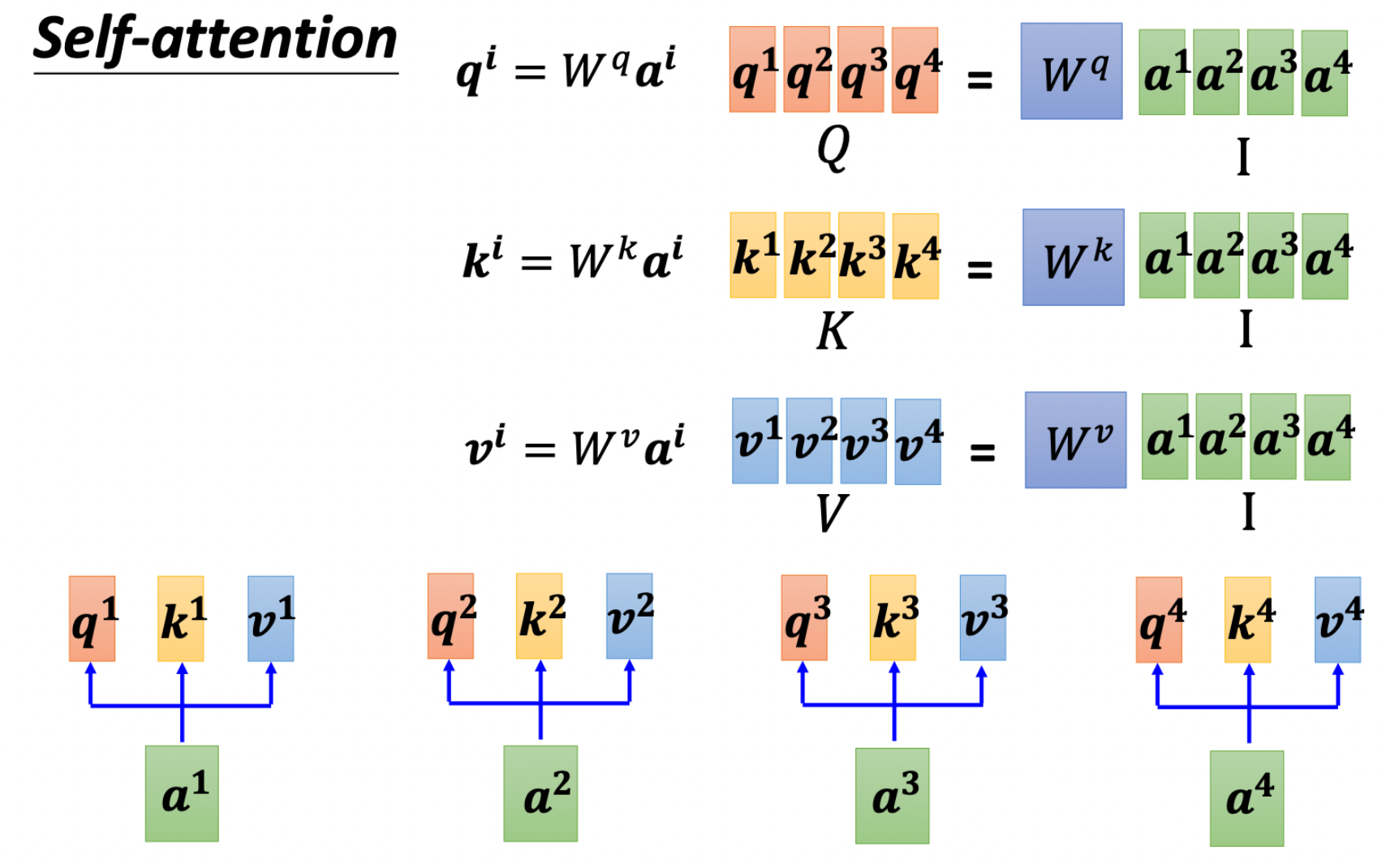
因此,根据上面的式子,我们可以将输入的合并成一个矩阵计算,就可以实现一次计算得到所有的相关性矩阵A( A ′ A^{'} A′是做了个softmax),以及输出矩阵O
-
-
于是从外部看就有了以下的形式,也就符合这个公式: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V,公式中的矩阵顺序颠倒,但不影响理解,其中除以 d k \sqrt d_k dk是为了保证方差为1,有利于梯度下降
-
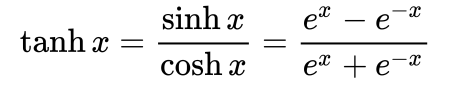


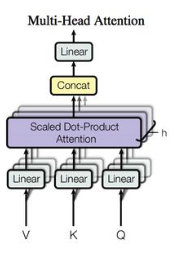
multi-head self-attention
-
其实就可以理解为同一套输入进入多套并行的self-attention模块里面去,对最后的结果进行cancat一下即可
-
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . . , h e a d h ) W o MultiHead(Q,K,V) = Concat(head_1,....,head_h)W^o MultiHead(Q,K,V)=Concat(head1,....,headh)Wo
-
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i = Attention(QW_{i}^Q,KW_{i}^K,VW_{i}^V) headi=Attention(QWiQ,KWiK,VWiV)
-
-
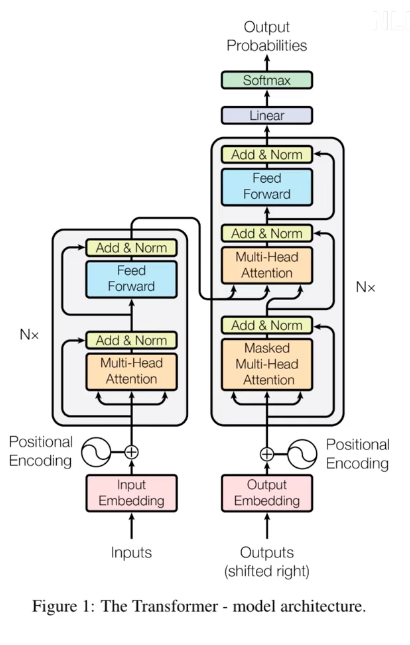
回过头来看Transformer
-
回过头看看Transformer的结构,会发现豁然开朗
-
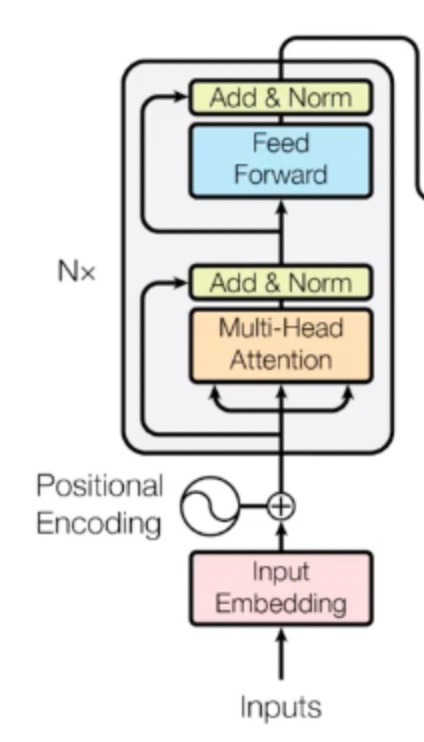
encoder部分
-
首先对于encoder部分:
-
-
我们对输入编码后加上位置信息编码(Positional Encoding)后就进入Multi- Head Attention(参考上面的理解),之后做了一个Add&NORM的操作,其中Add代表的是残差,参考RenNet中残差的作用,是防止网络退化的;而Norm则是做了这么一个操作(归一化,但不用考了batch,因此比Batch Norm来的简单)
-
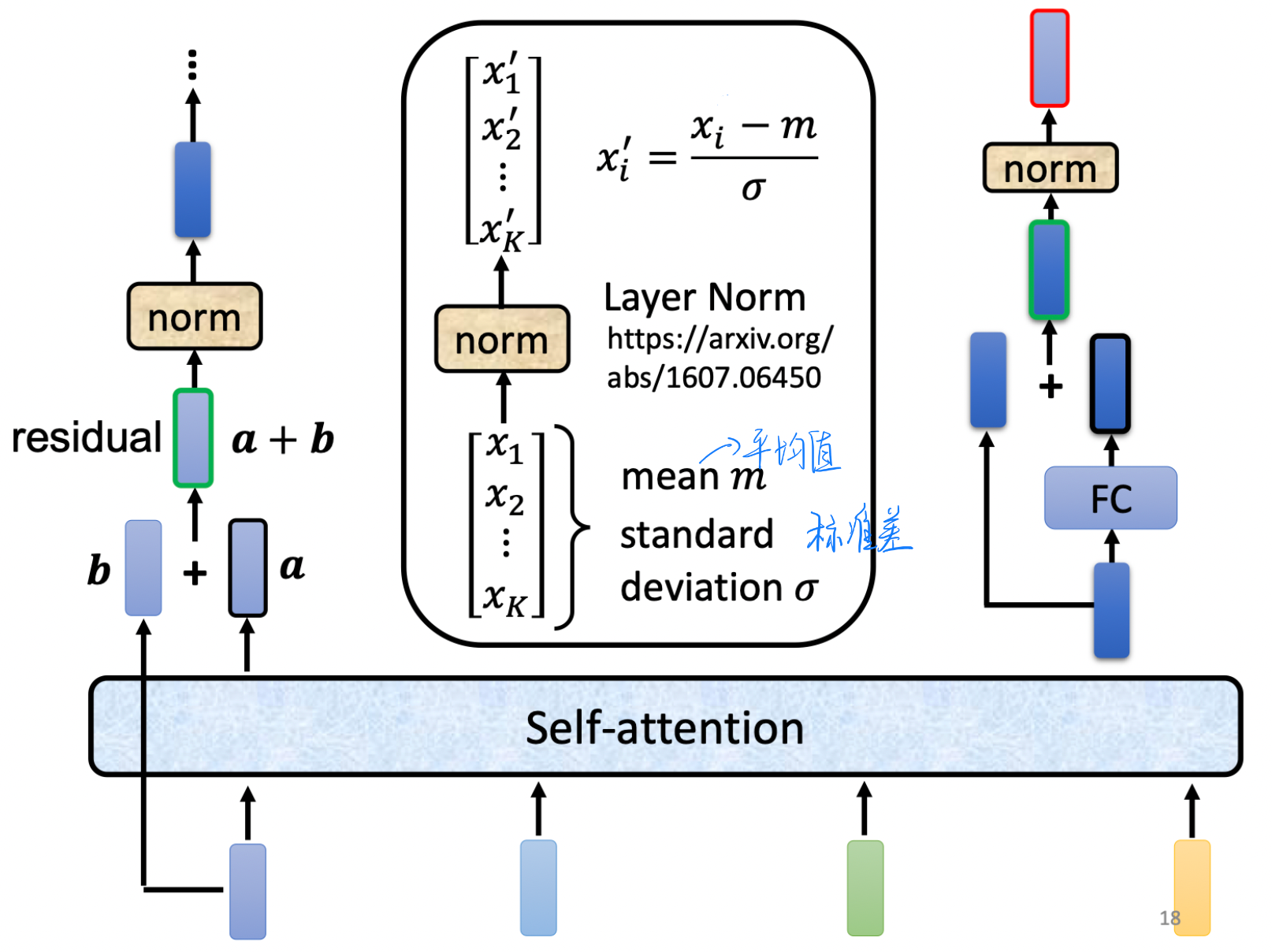
-
而在往下的Feed Forward实际上可以为FC层(当然别的也可以),然后再来一组残差+归一化,就是整个encoder的结构了
-
decoder部分
-

-
对于decoder,首先对输出考虑Masked版本的多头注意力机制,其实就是在计算相关性的时候可以考虑上文(之前的)但不能考虑下文(之后的),然后再与encoder的输出汇合,再做一组多头注意力机制的前推,残差归一化+FC,就完成了decoder的计算
-
这个跟encoder十分类似