Self-attention (常见的network架构)
李宏毅 2021 machine learning课程中的transformer
self-attention想要解决的问题:
目前的input都是一个向量,而如果input是一系列向量(a set of vectors),并且输入的向量个数是会改变的,例如输入不同长度的句子。
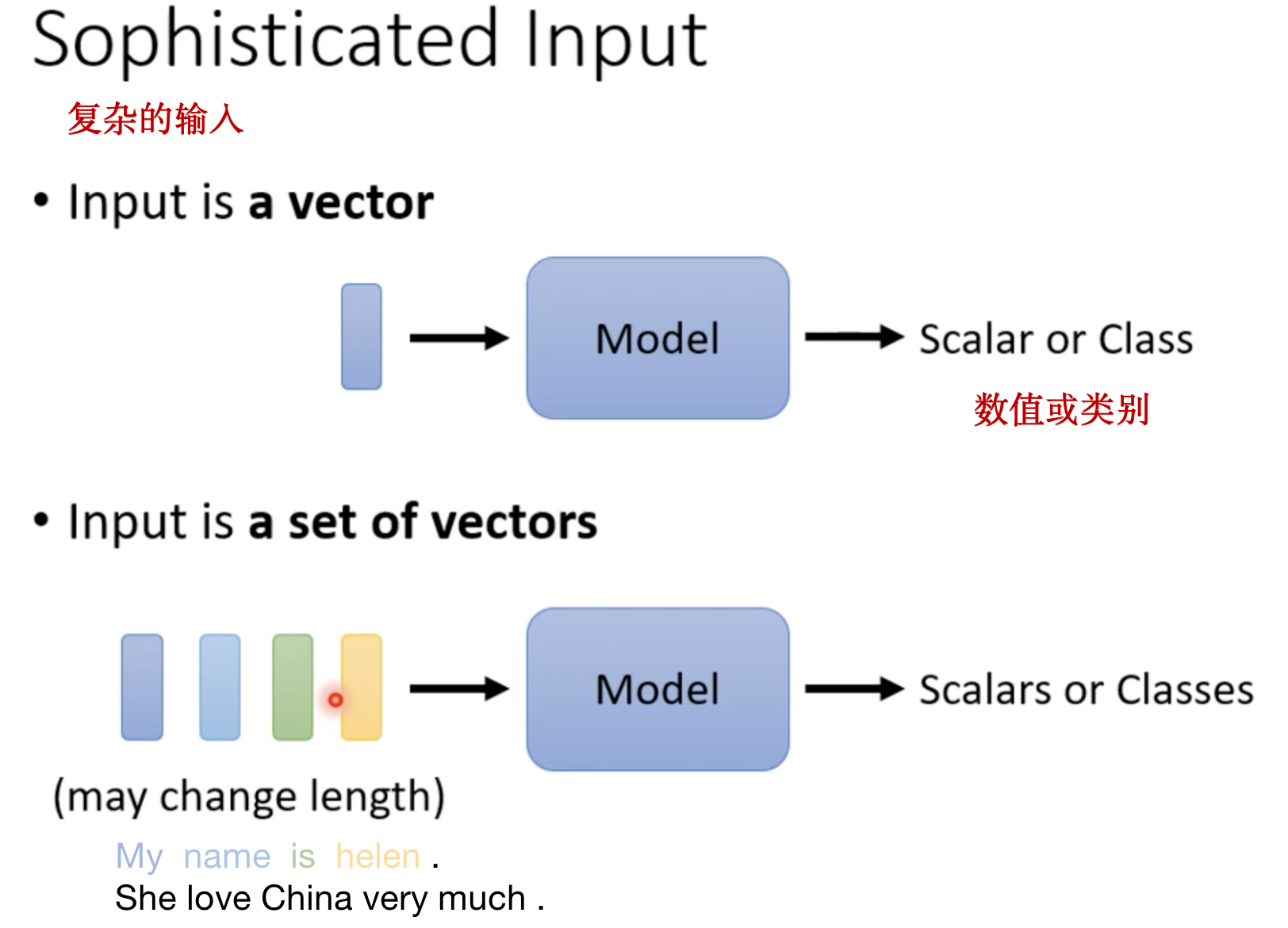
怎么把一个词汇表示成一个向量呢?
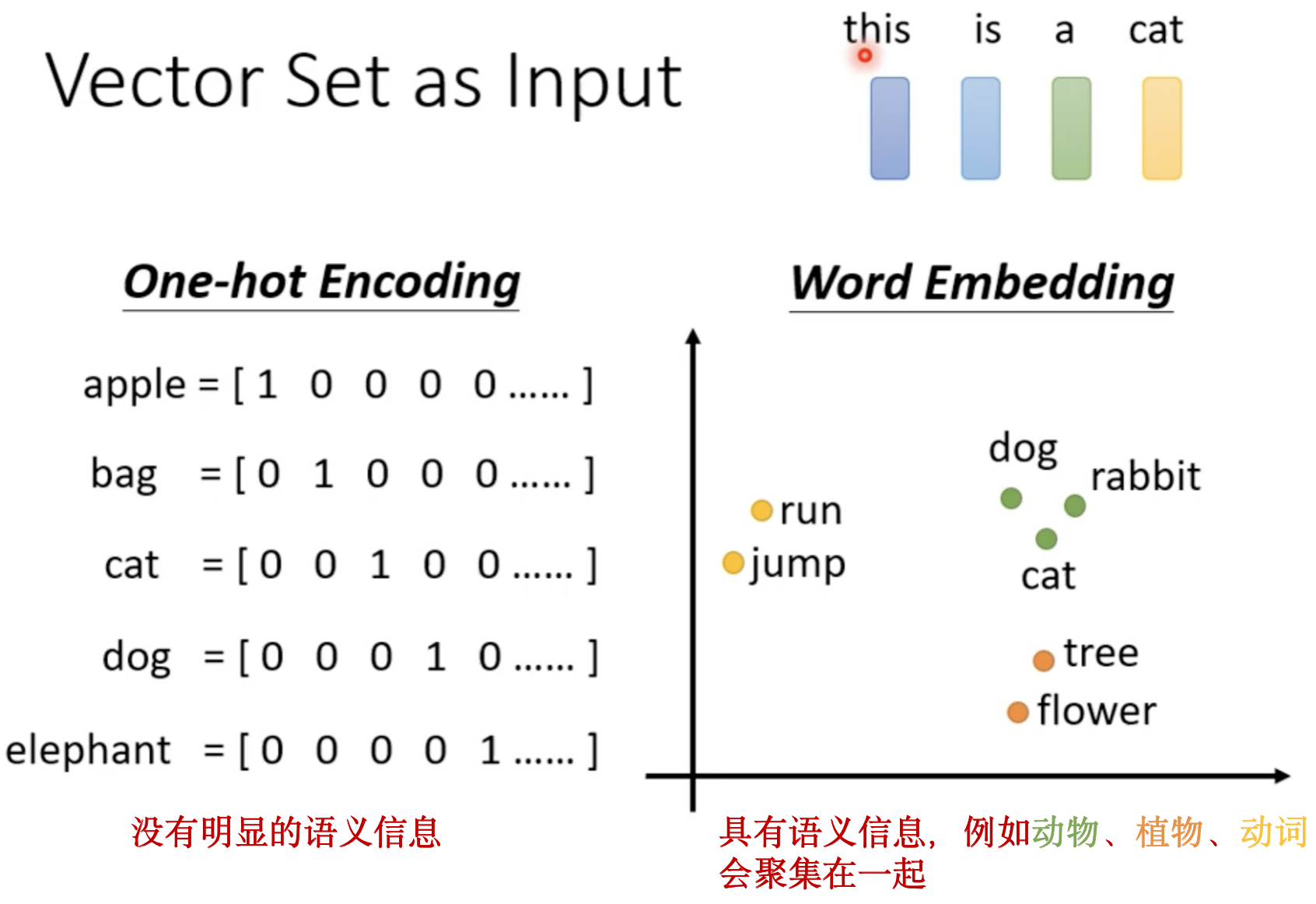
1.将一个词汇转换为一个向量,最常用的方法是 One-hot Encoding,这种向量表示法 维度数就是世界上所有词汇的数目,其中的每一个维度表示一个单词,但是这种方法假设各个单词之间都没有关系,向量里没有任何语义信息。
2.另一种方法 Word Embedding的向量是有语义资讯的。
还有哪些应用是需要这种 a set of vectors ?
例如 音频处理 和 一个图

输入是一堆向量,那么输出是什么?
可能有三种情况:
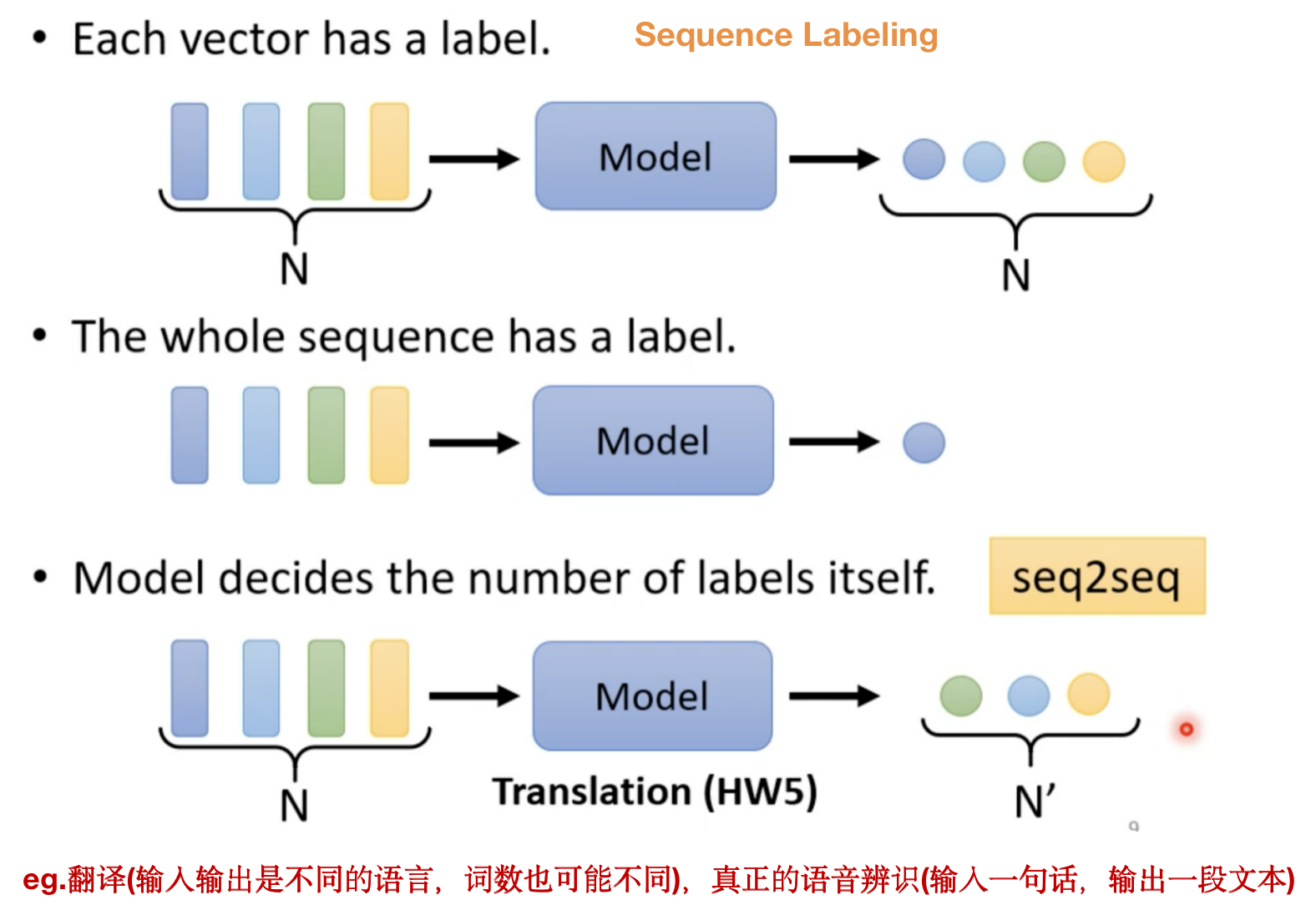
第一种和第二种举例:
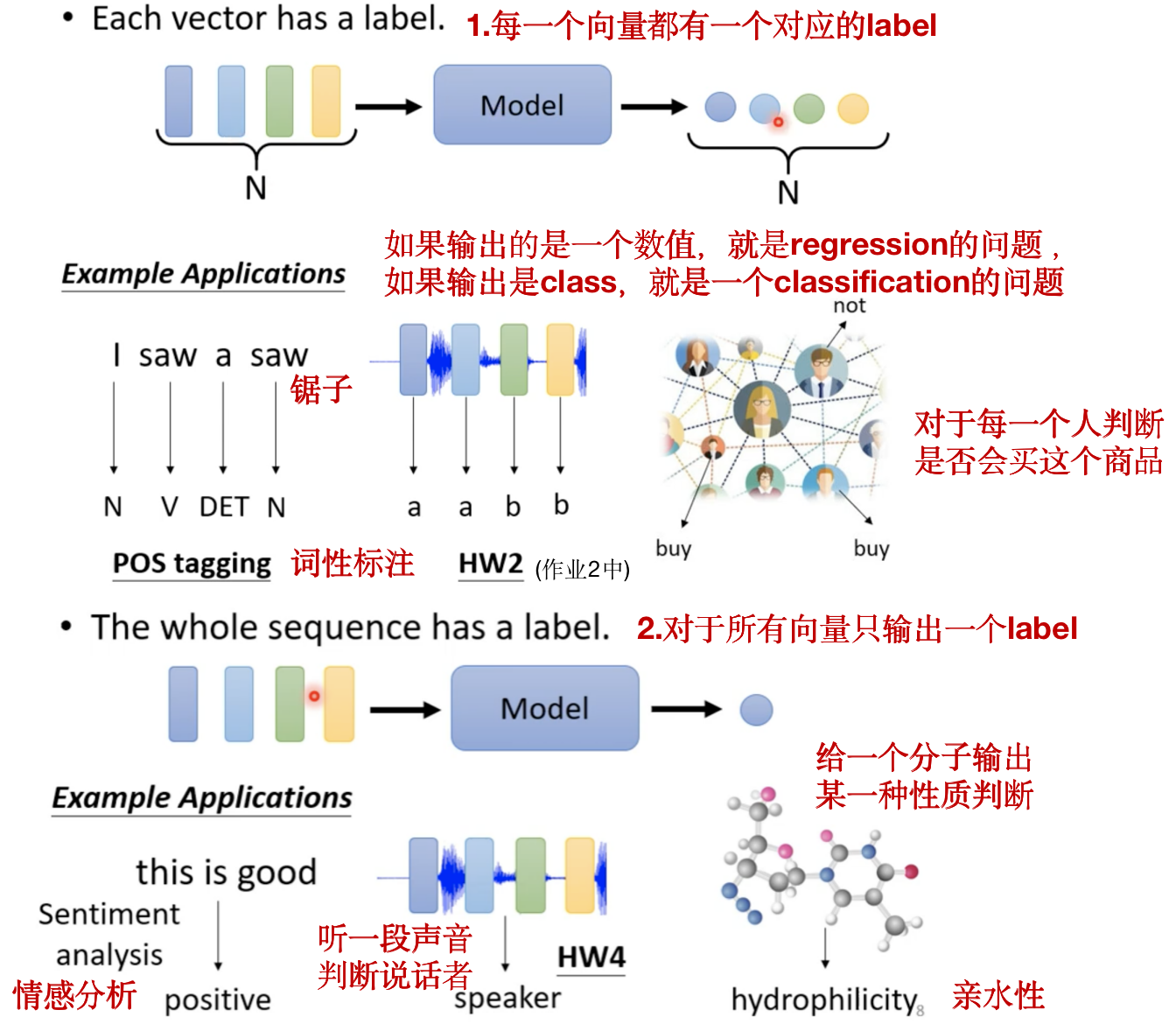
详细介绍第一种情况,即Sequence Labeling:
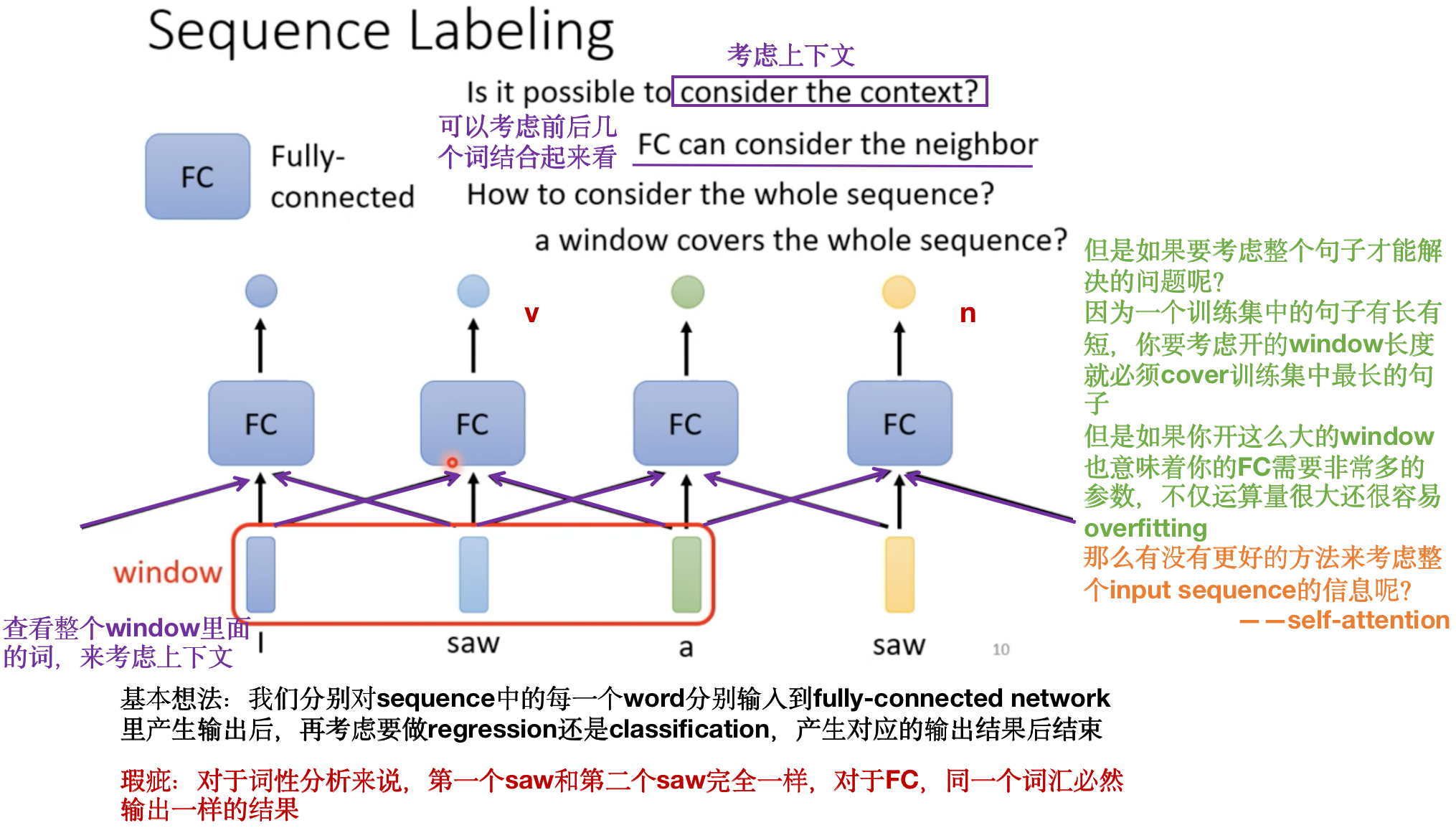
更好的方法来考虑整个input sequence的信息:self-attention:
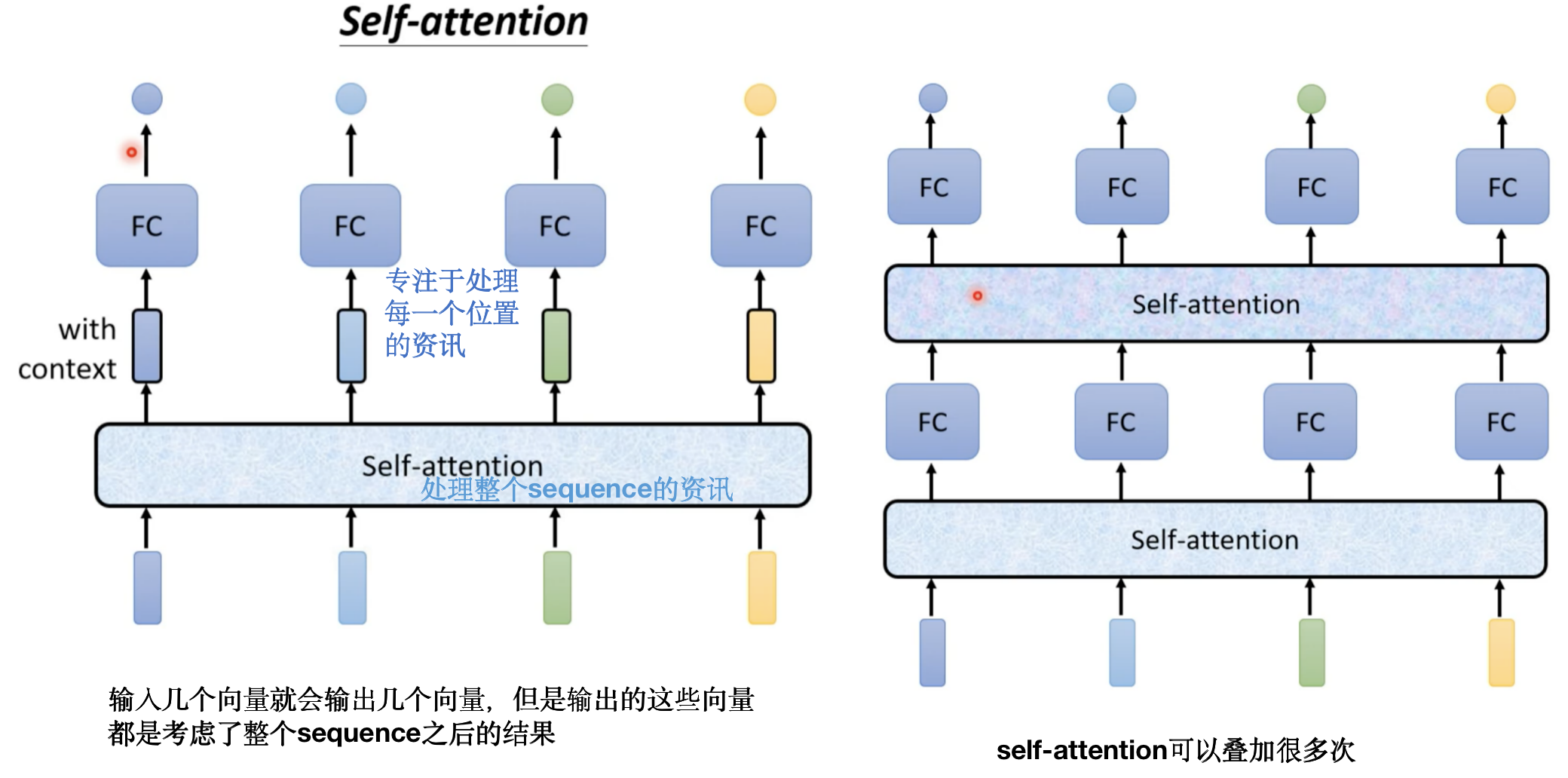
selt-attention是怎么运作的呢?
b 1 b^1 b1~ b 4 b^4 b4是一次/同时被计算出来的
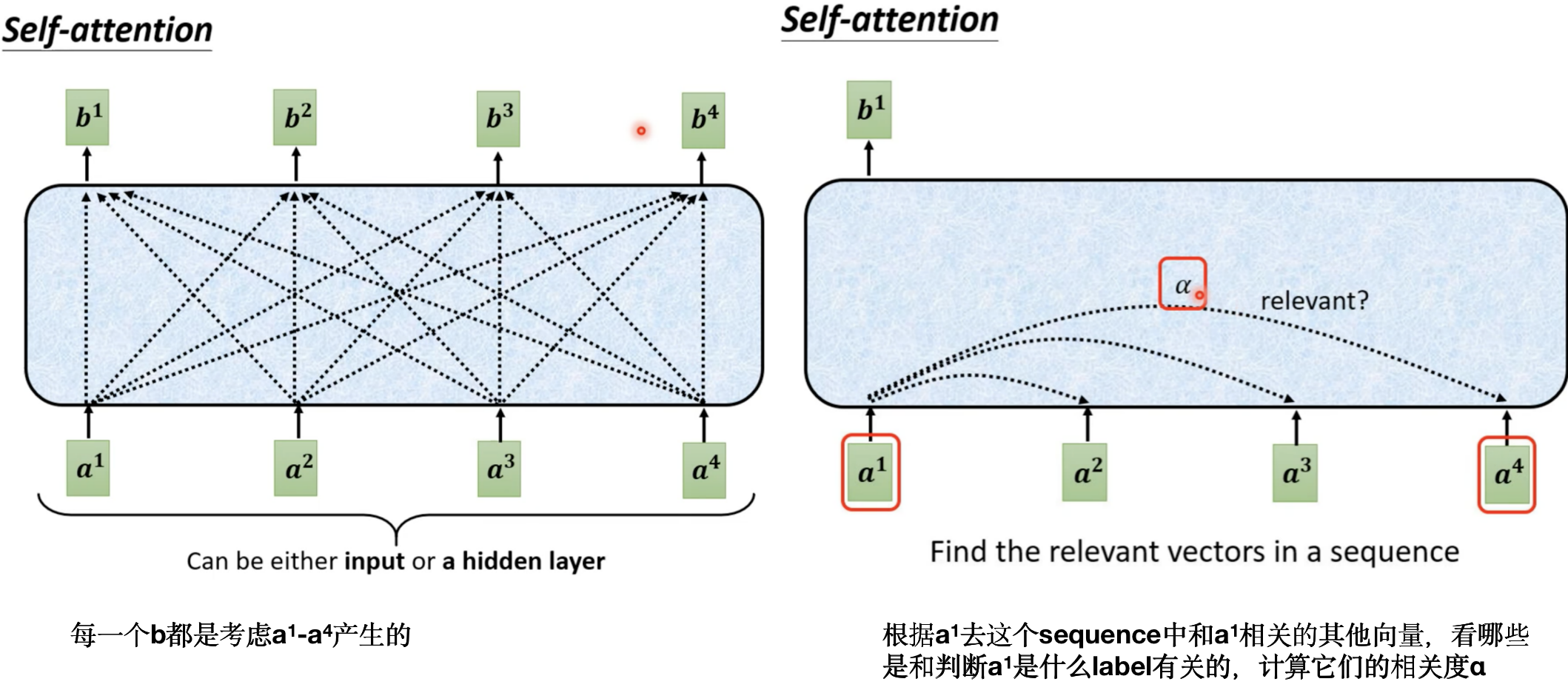
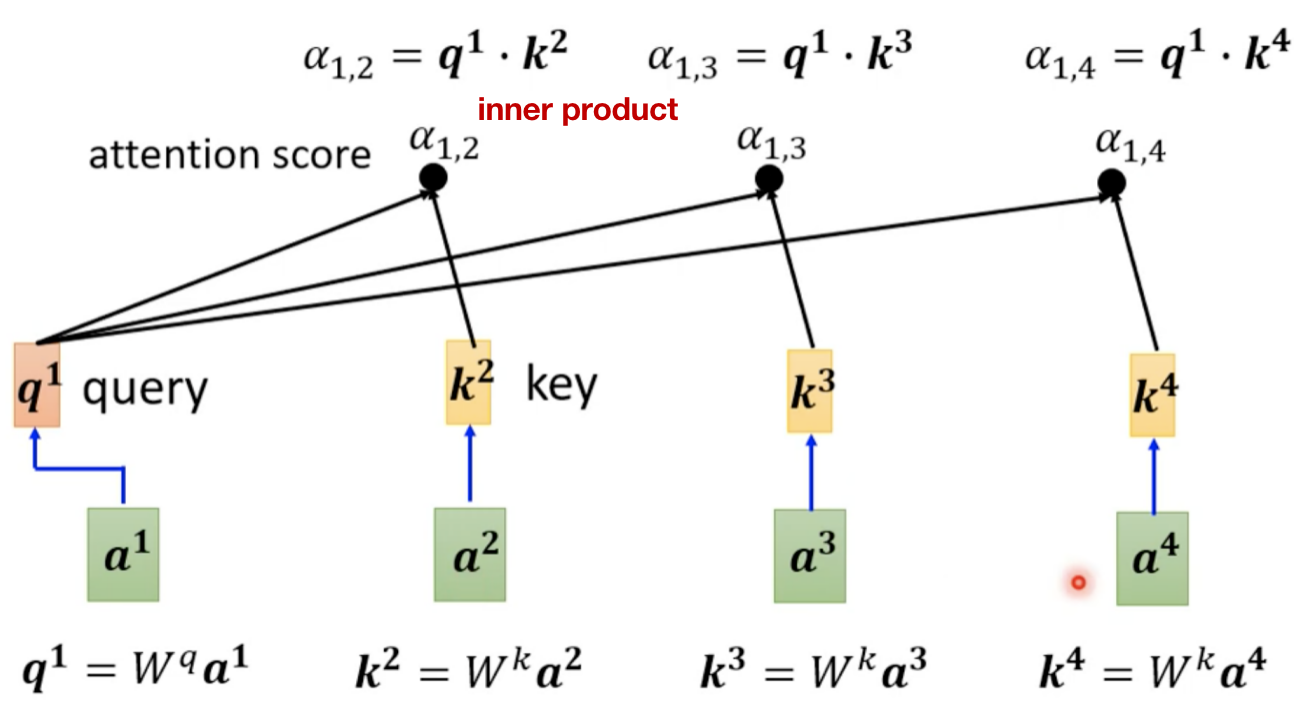
接下来要判断的就是Self-attention是怎么自动决定两个向量间的相关度α的呢?
计算Attention的module:一般有两种方式
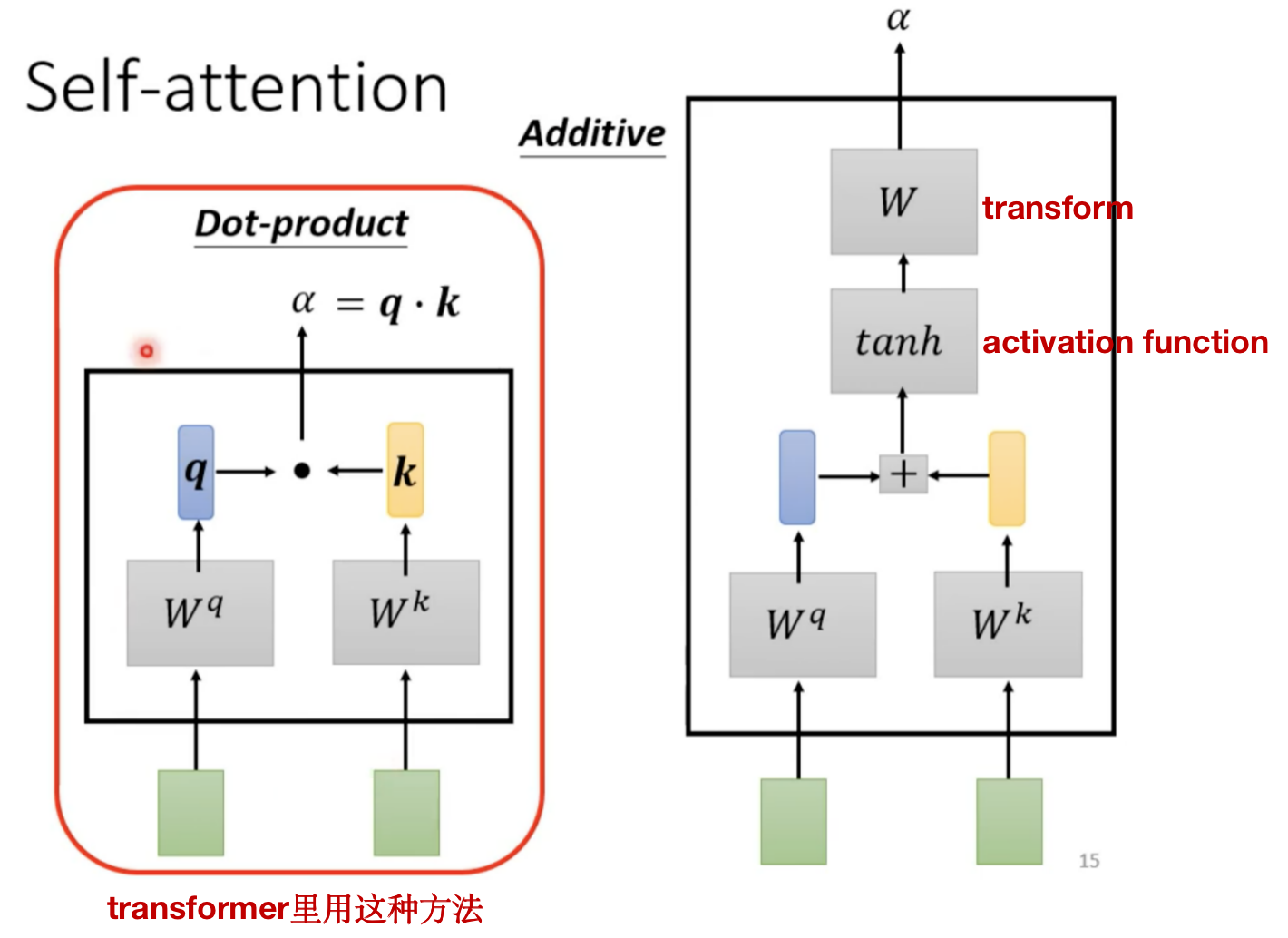
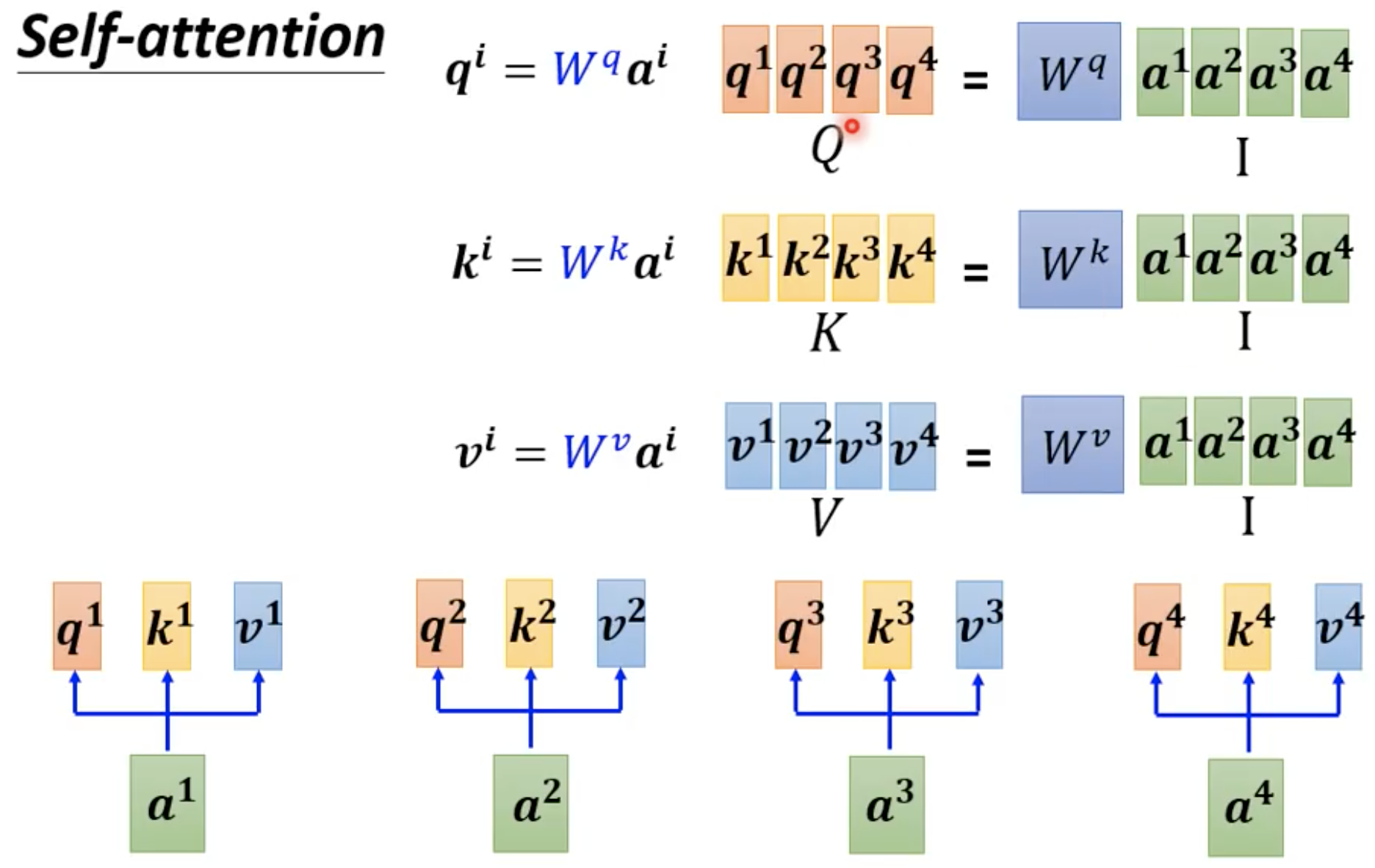
怎么把dot-product套用到Self-attention中呢?(以计算 b 1 b^1 b1为例)
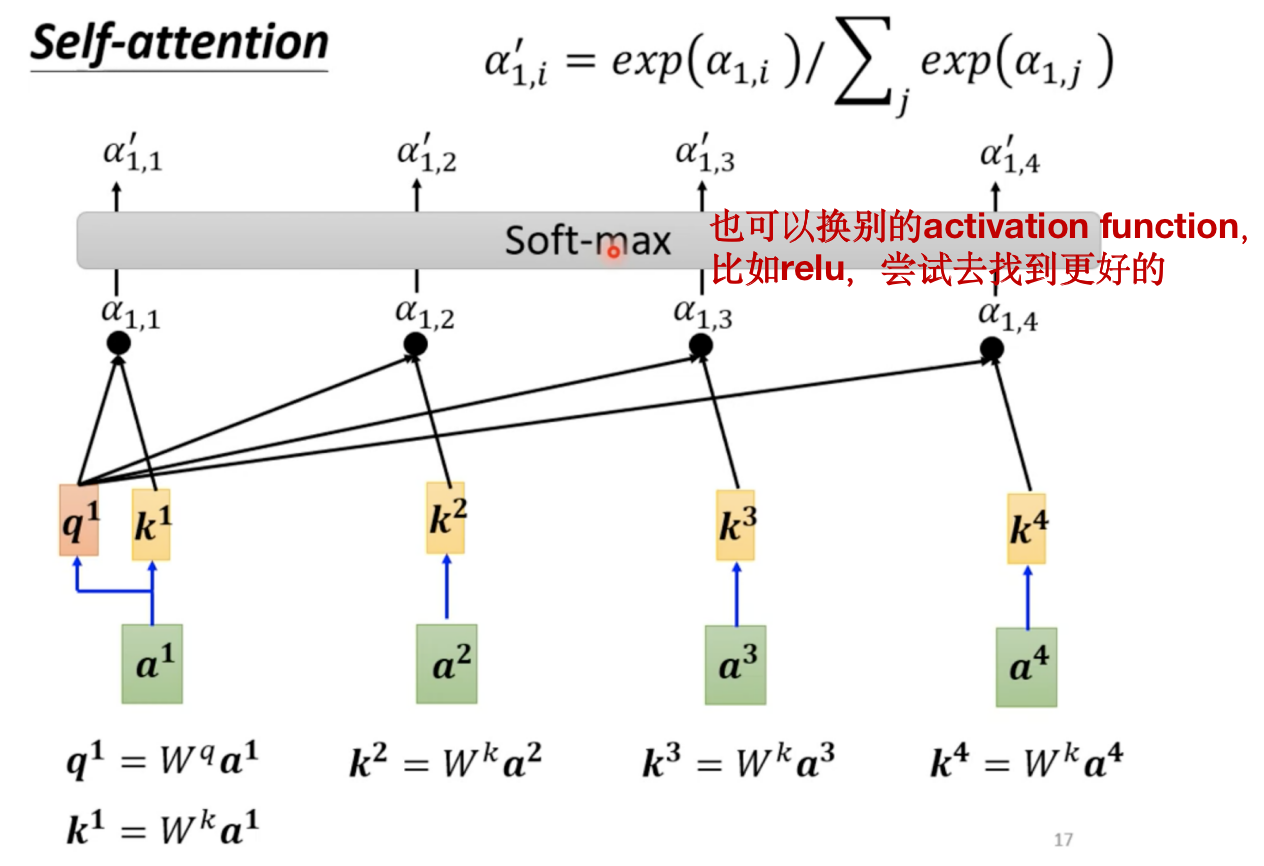
在实际中, q 1 q^1 q1也会跟自己算关联度,这件事情也很重要!
计算到关联度α之后怎么抽取出sequence中重要的资讯呢?
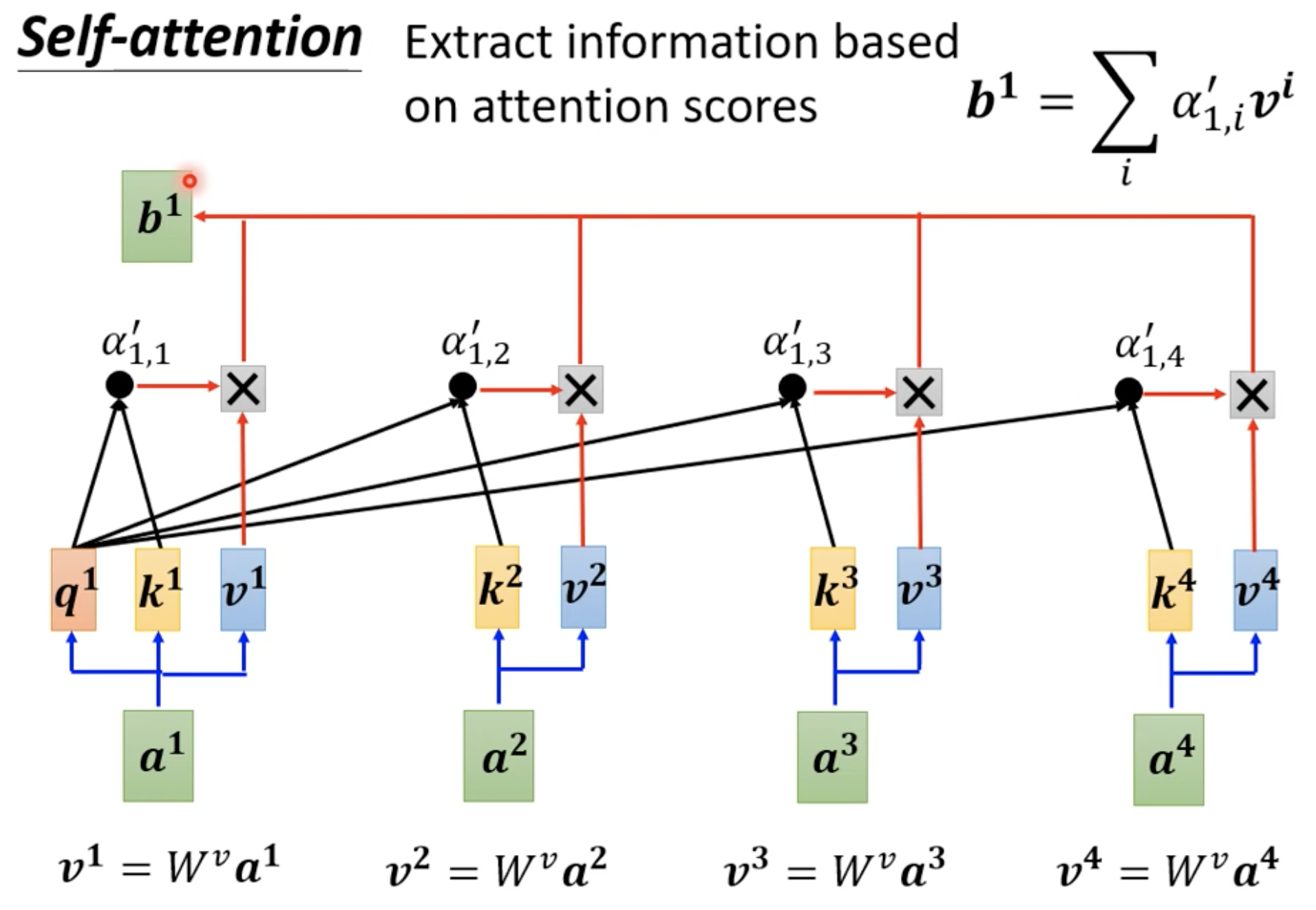
这里展示了怎么通过一整个sequence得到向量 b 1 b^1 b1,如果向量 a 2 a^2 a2 和 a 1 a^1 a1 的相似度α很高,那么得到的抽出来的结果 b 1 b^1 b1 就会比较接近 v 2 v^2 v2。
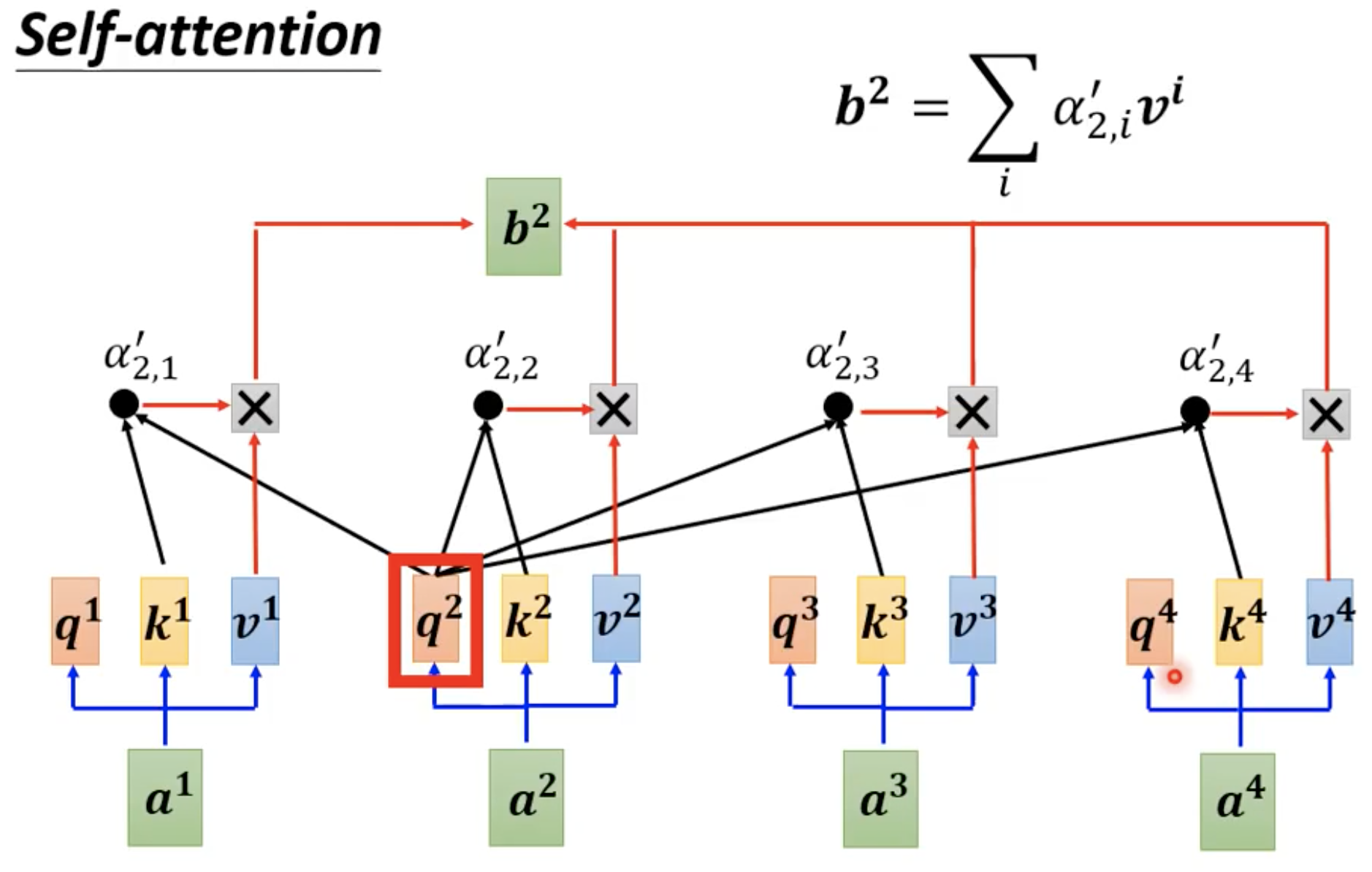
计算 b 2 b^2 b2 也是同理
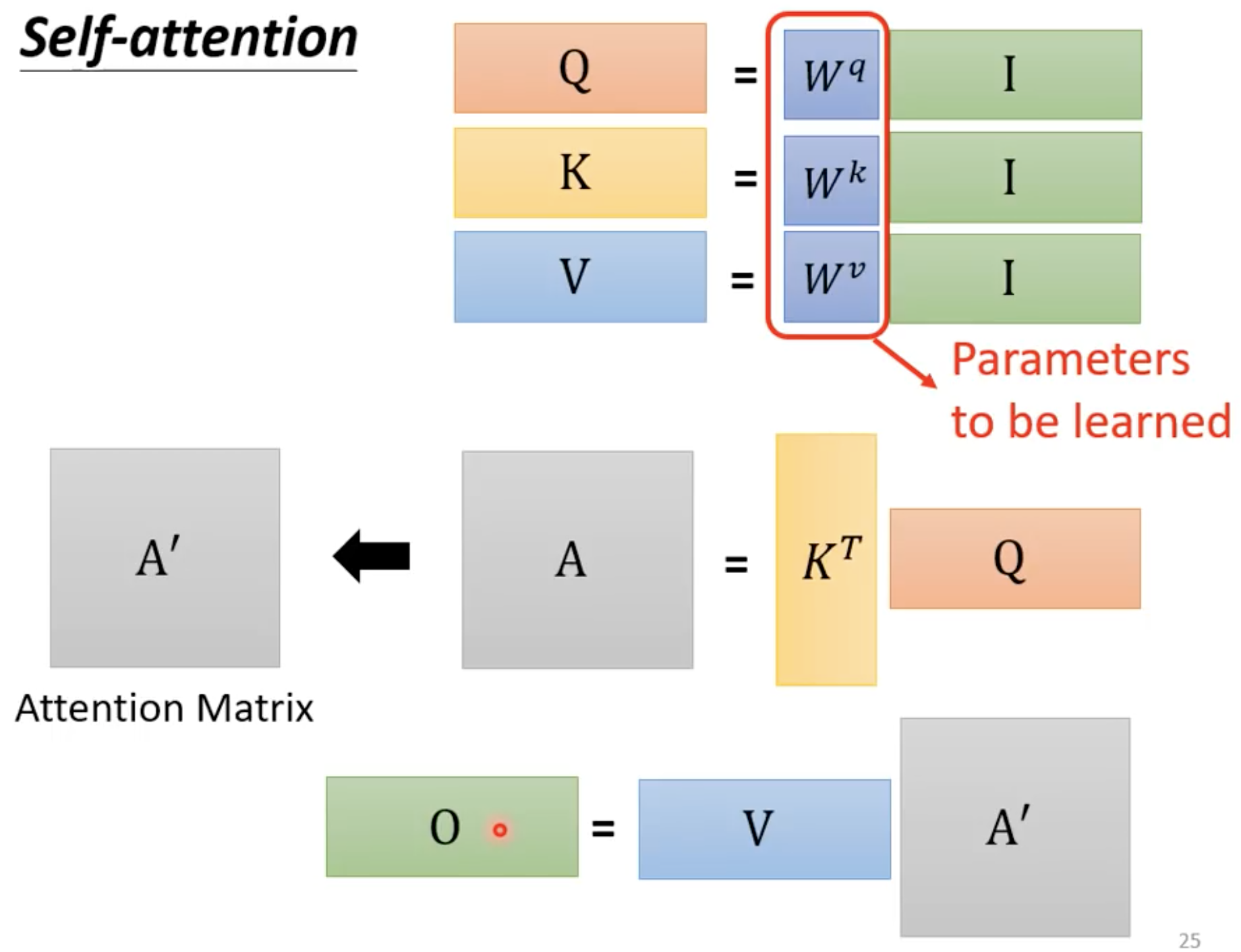
从矩阵乘法角度来看self-attention的运作:
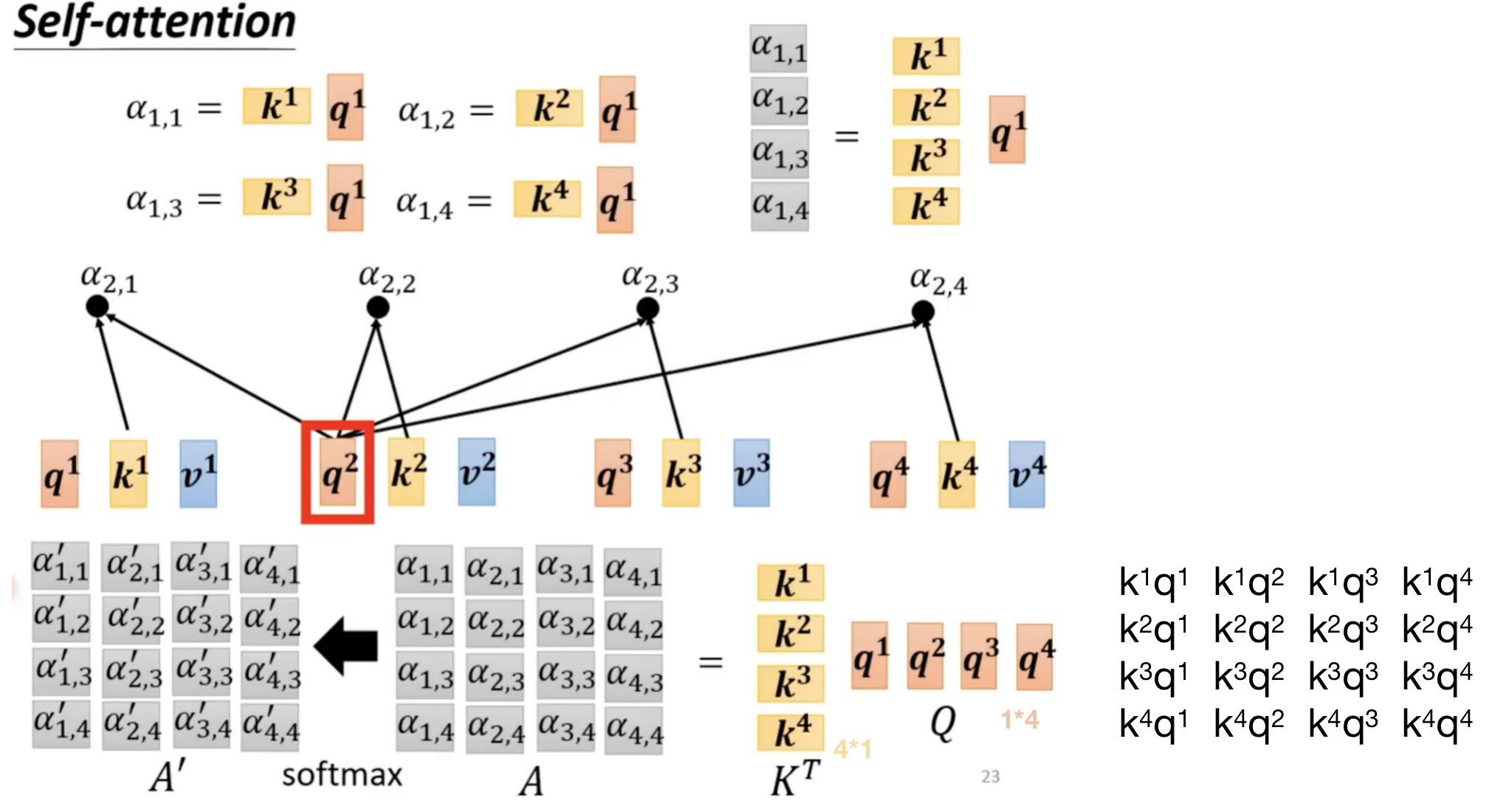
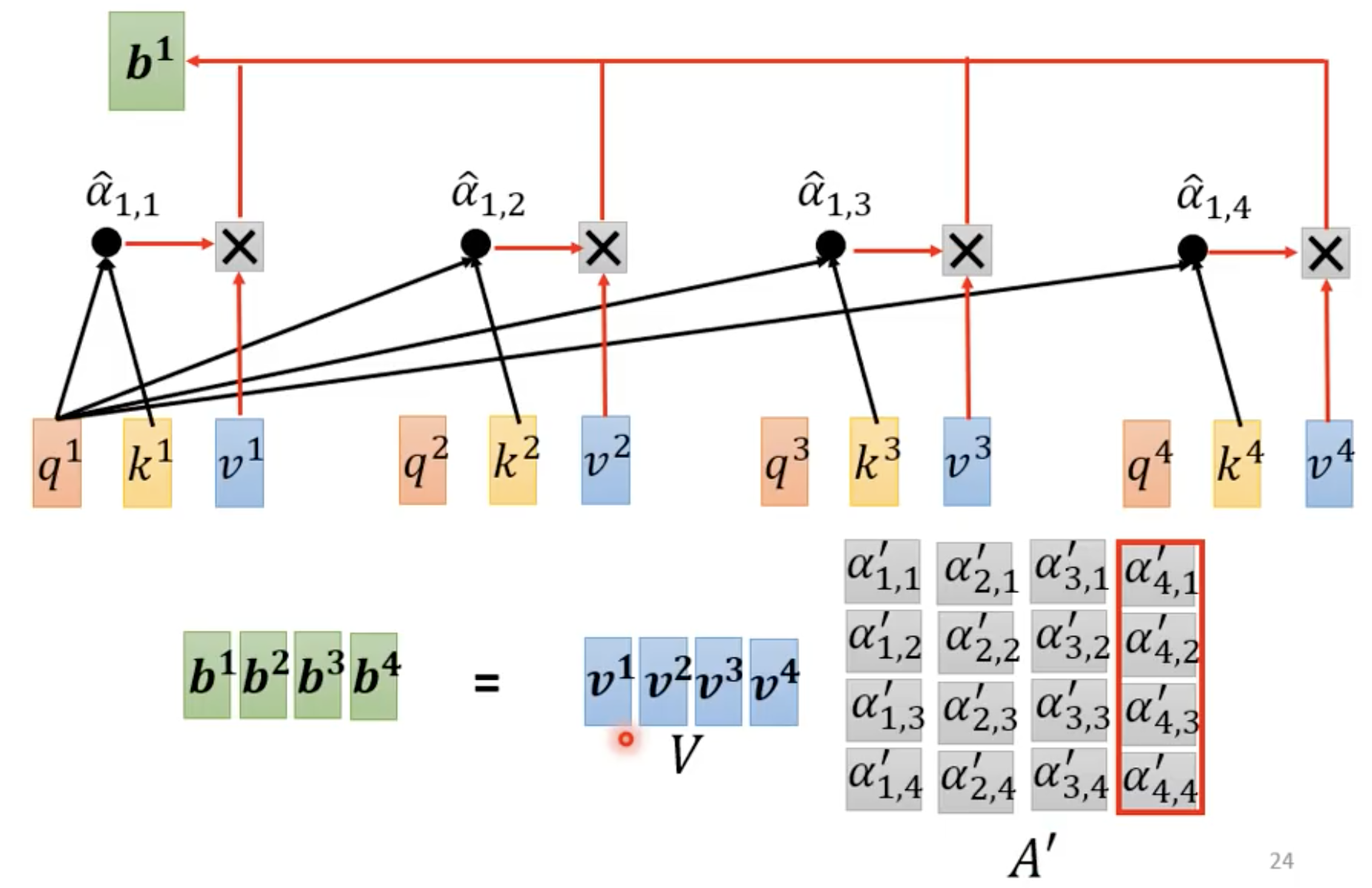
上图中应该是 α 1 , 1 ′ α_{1,1}' α1,1′
总结这个过程:
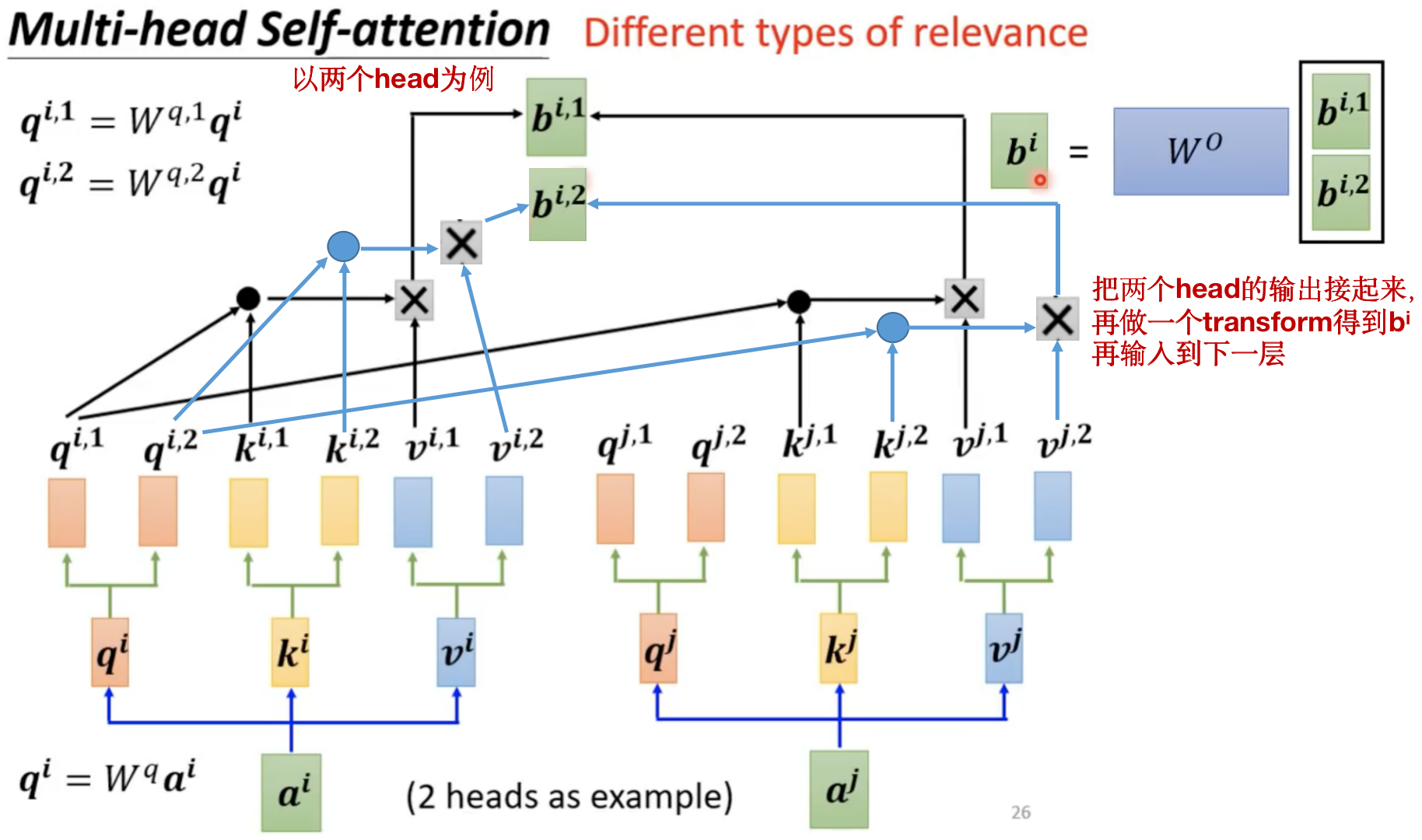
一个扩展:Multi-head Self-attention
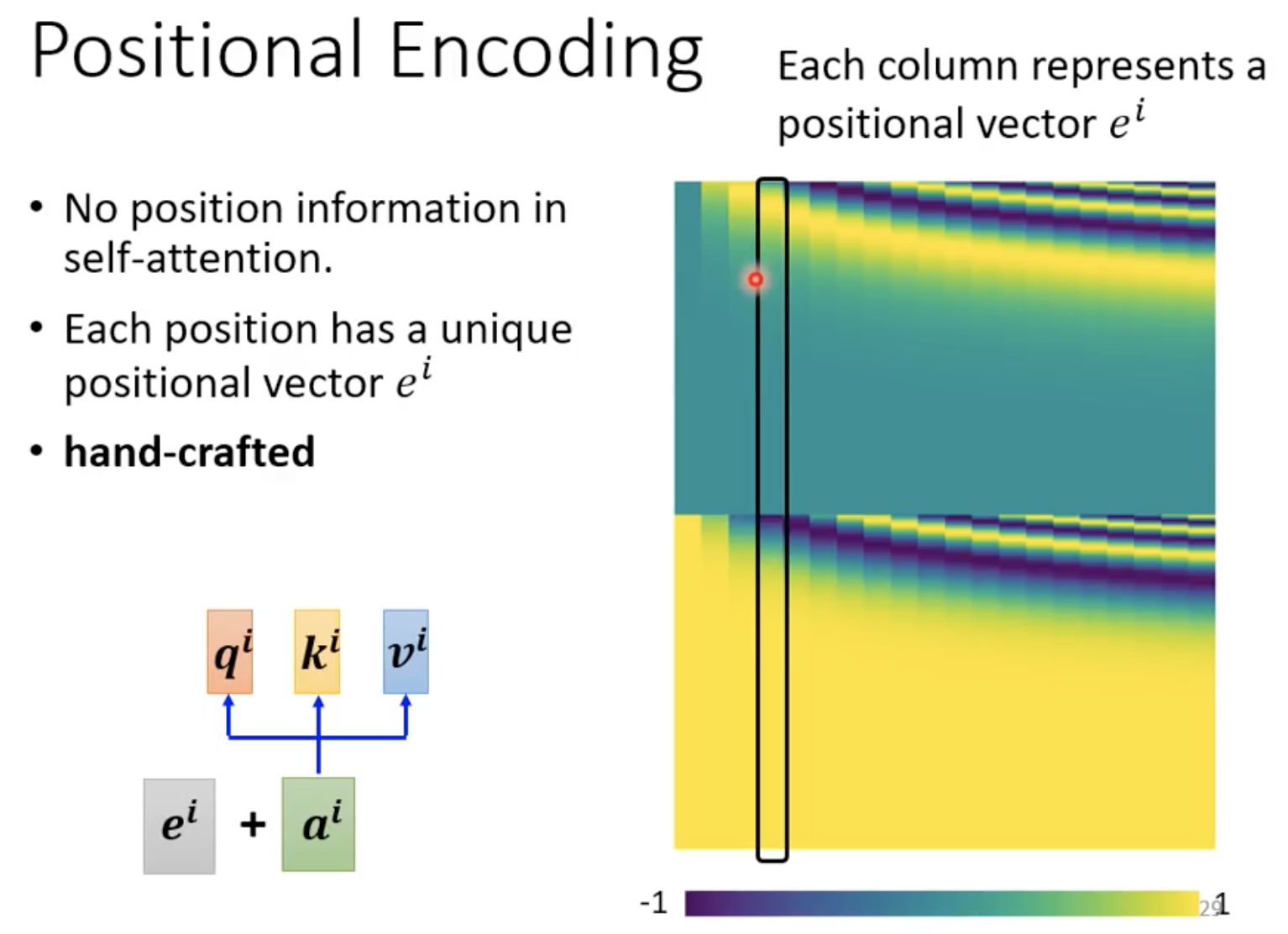
Positional Encoding
我们会发现self-attention 缺少位置信息,如果我们在做POS tagging (词性标注)时,位置信息可以有帮助,比如动词一般不会出现在句首。这个时候我们可以把位置信息加入到Self-attention中。
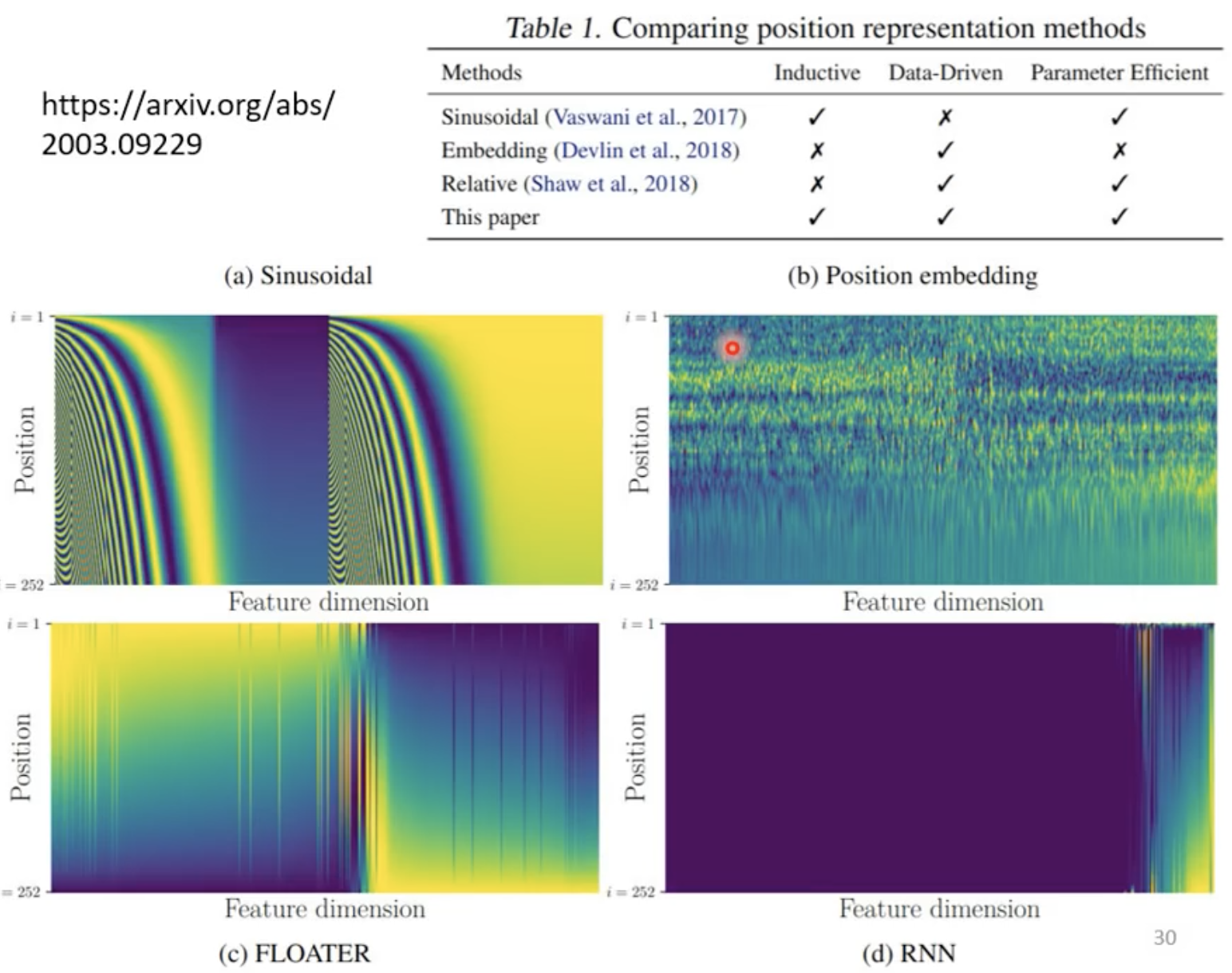
positional encoding是可以通过资料学出来的,也可以是手动给的,可以有很多种方式进行。
self-attention还有很多应用:
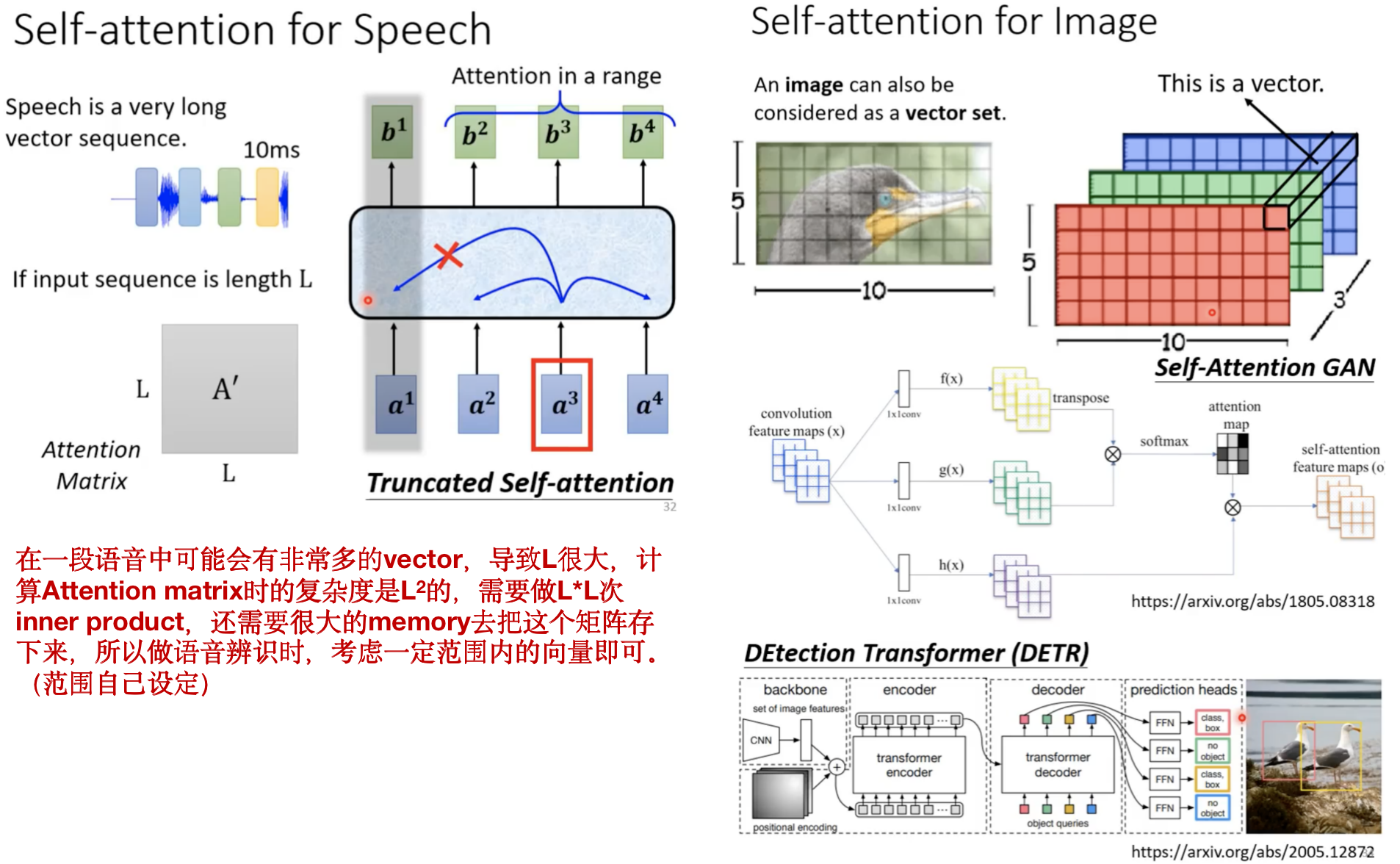
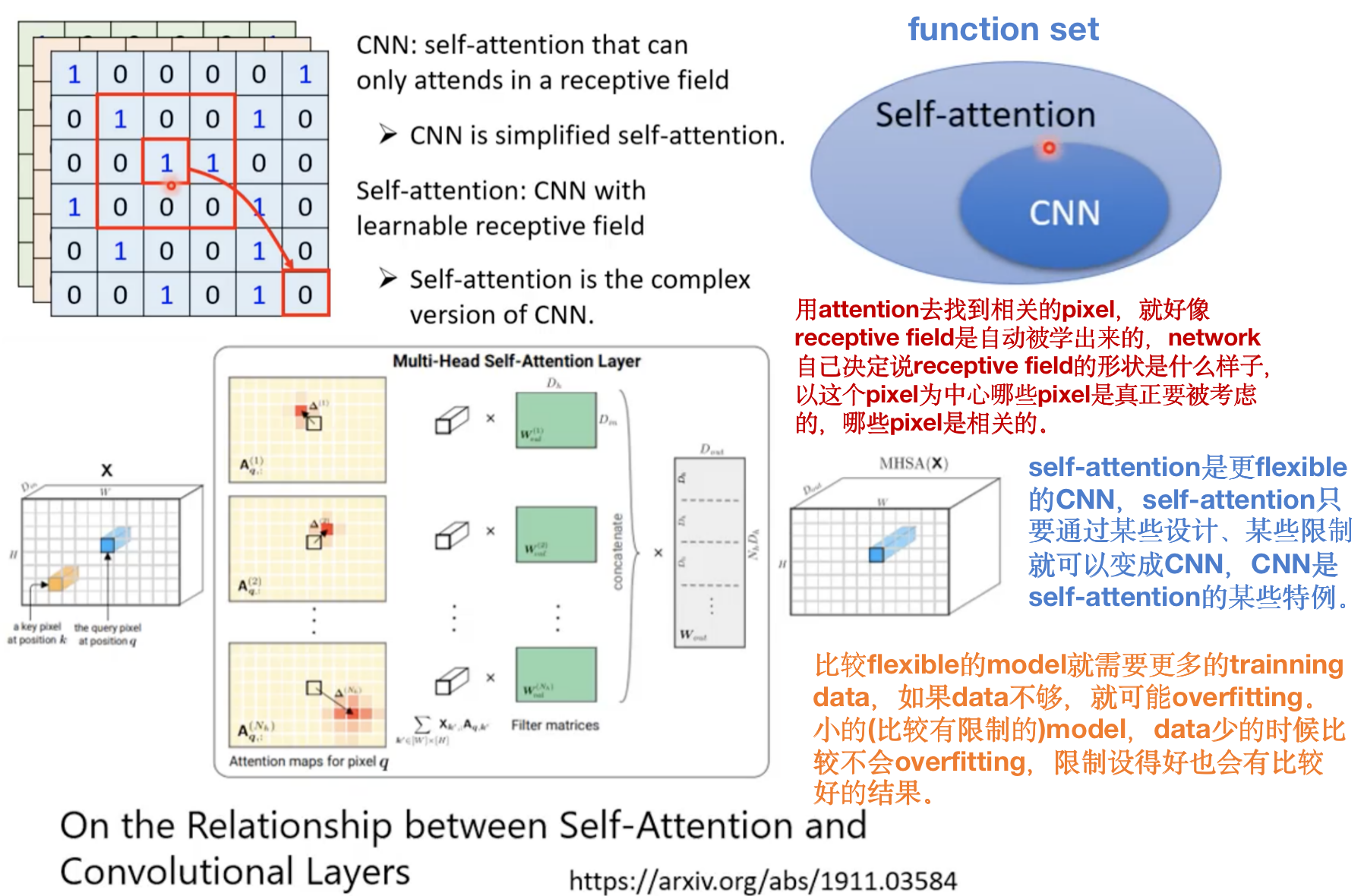
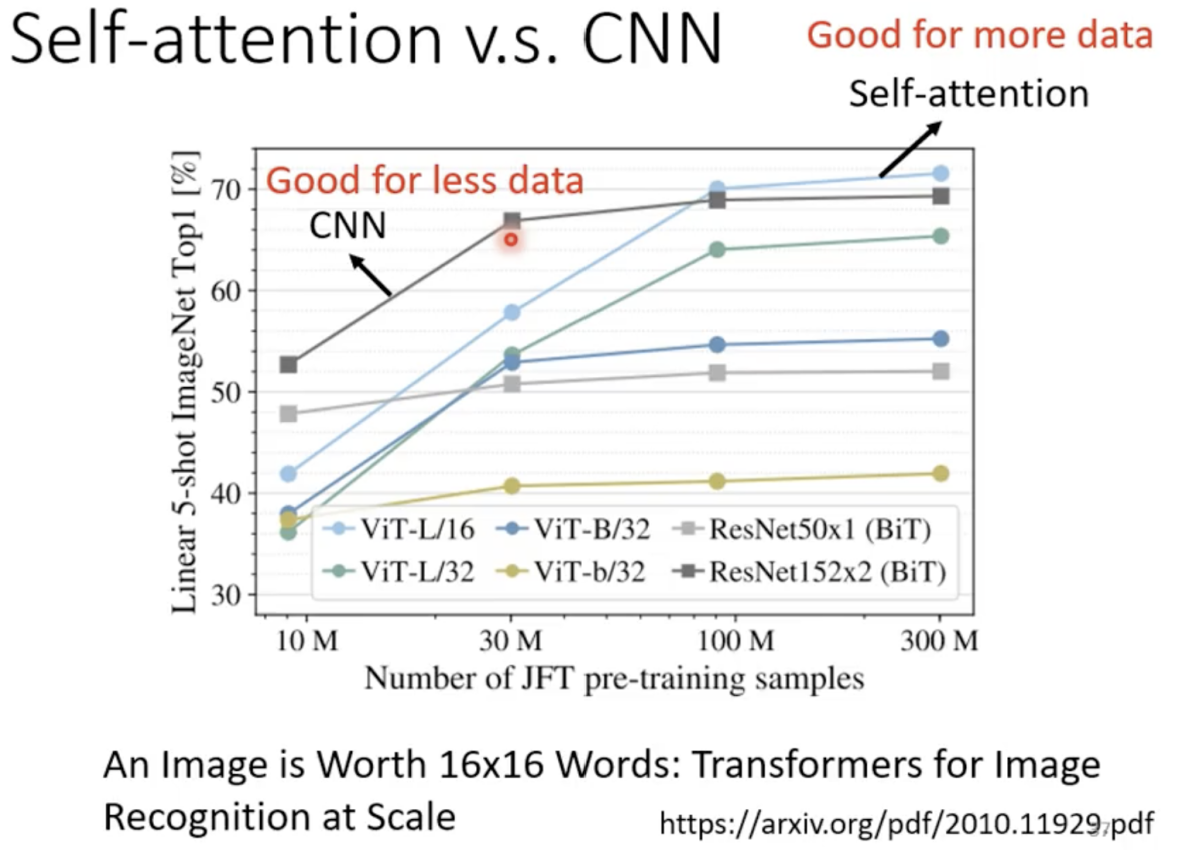
Self-attention和CNN的比较
Self-attention和RNN的比较

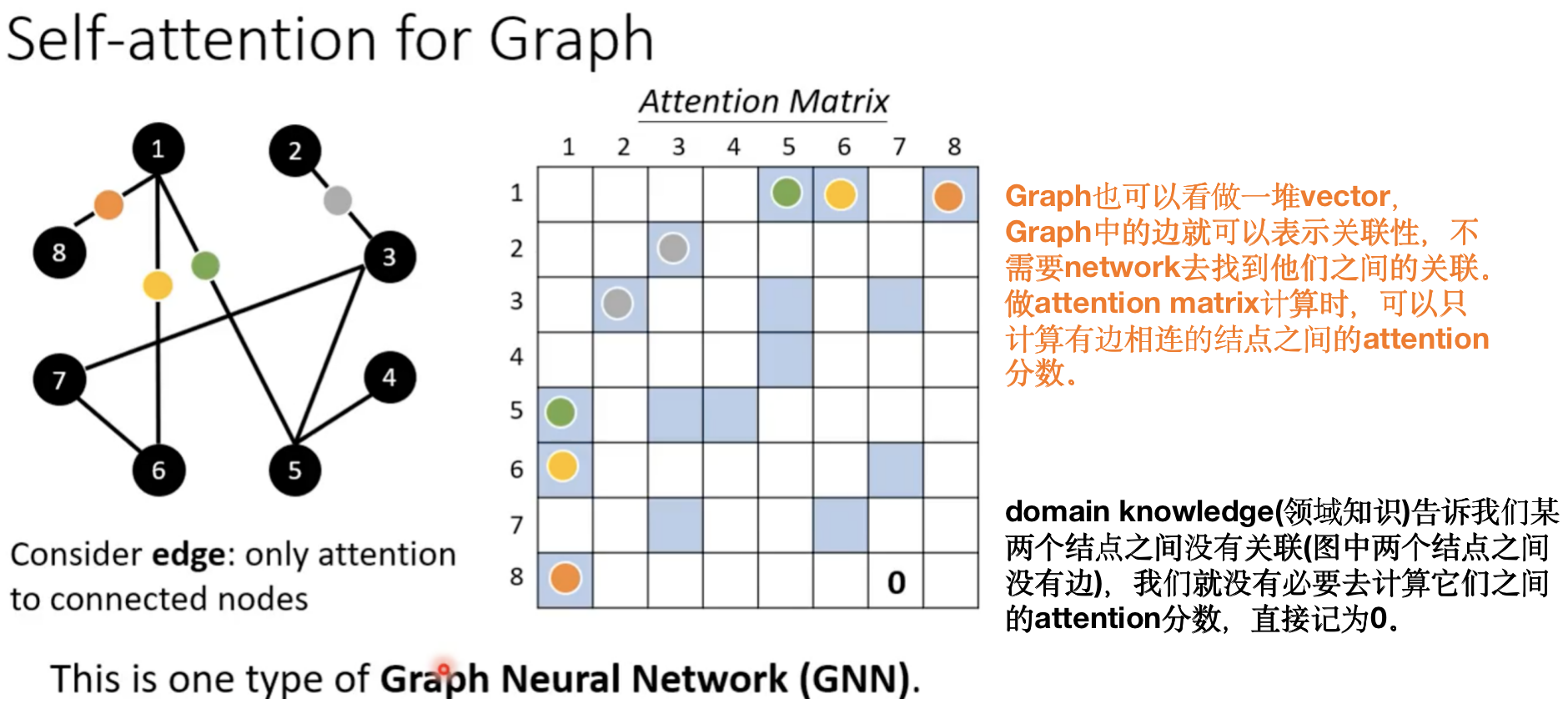
Self-attention for Graph
更多的变形:
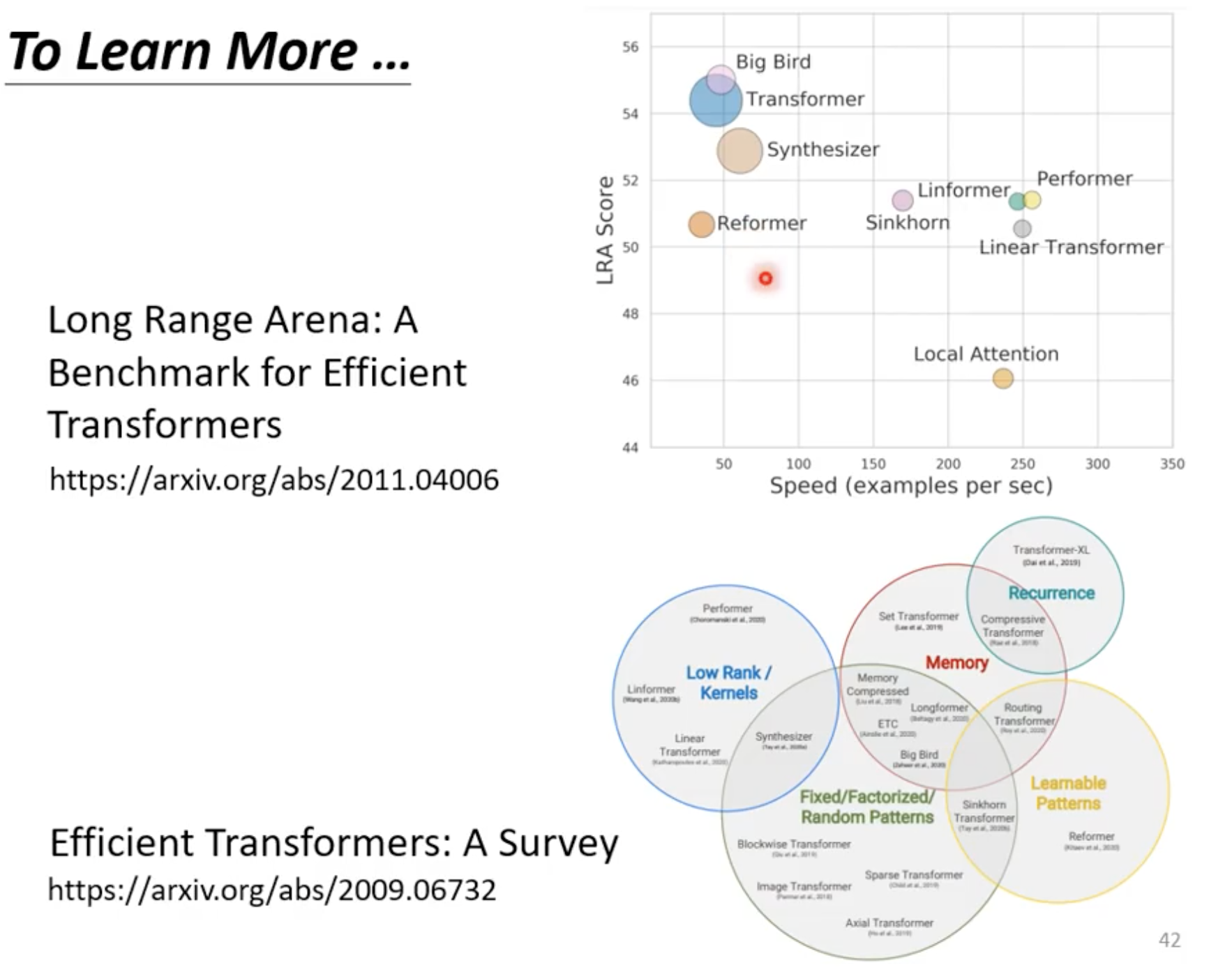
selt-attention最大的问题就是 运算量非常大
广义的transformer就是Self-attention
速度的提升在很多情况下带来的是performance的下降