Encoder-Decoder框架:
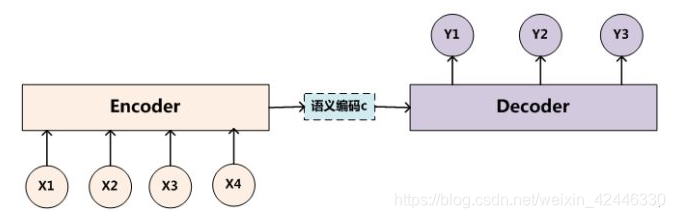
可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。

Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
![]()
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息,来生成i时刻要生成的单词:
![]()
如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。
Attention机制:

- 根据根据Query和某个Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

- 引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:

- 计算结果a_i即为value_i对应的权重系数,然后进行加权求和即可得到Attention数值:

Self Attention模型:

指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度 ,其中
为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为
其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式:

Transformer模型:

Transformer用于执行翻译任务,实验表明,这一模型表现极好,可并行化,并且大大减少训练时间。其本质上是一个Encoder-Decoder的结构,编码器由6个编码block组成(encoder每个block由self-attention,FFNN组成),同样解码器是6个解码block组成(decoder每个block由self-attention,encoder-decoder attention以及FFNN组成),与所有的生成模型相同的是,编码器的输出会作为解码器的输入。
模型结构如下图所示:

编码器:编码器有6个完全的层堆栈而成,每一层都有两个子层。第一个子层是多头的self-attention机制上面讲过了,第二层是一层简单的前馈网络全连接层。在每一层子层都有residual和归一化。

解码器:解码器也是有6个完全相同的层堆栈而成,每一层有三个子层,在编码栈的输出处作为多头的attention机制。
多头注意力机制:点乘注意力的升级版本。相当于 个不同的self-attention的集成(ensemble),在这里我们以
举例说明。Multi-Head Attention的输出分成3步:
- 将数据
分别输入到上面的8个self-attention中,得到8个加权后的特征矩阵
。
- 将8个
按列拼成一个大的特征矩阵;
- 特征矩阵经过一层全连接后得到输出
。

参考:深度学习:transformer模型、放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较
EMLO模型:
ELMO是“Embedding from Language Models”的简称,ELMO的论文题目:“Deep contextualized word representation”更能体现其精髓:在deep contextualized这个短语,一个是deep,一个是context,其中context更关键。ELMO的本质思想是:我事先用语言模型学好一个单词的Word Embedding,根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义。ELMO采用了典型的两阶段过程:
- 利用语言模型进行预训练;

- 在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。

优点:
- 引入上下文动态调整单词的embedding后解决了多义词问题;
- 适用范围是非常广的,普适性强
缺点:
- LSTM抽取特征能力弱于Transformer
- 拼接方式双向融合特征融合能力偏弱
GPT模型:
GPT是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训练。GPT也采用两阶段过程:
- 利用语言模型进行预训练;

- 通过Fine-tuning的模式解决下游任务;

一个新问题:对于NLP各种花样的不同任务,怎么改造才能靠近GPT的网络结构呢?

- 对于分类问题,不用怎么动,加上一个起始和终结符号即可;
- 对于句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;
- 对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
- 对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。
与ELMO区别:
- 特征抽取器不是用的RNN,而是用的Transformer
- 采用的是单向的语言模型
优点:
- 引入Transformer任务性能提升非常明显
缺点:
- 单项语言模型只采用Context-before这个单词的上文来进行预测,而抛开了下文,白白丢掉了很多信息
Bert模型:
Bert采用和GPT完全相同的两阶段模型:
- 首先是语言模型预训练;
- 其次是使用Fine-Tuning模式解决下游任务。

改造下游任务:

- 对于句子关系类任务,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。
- 对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造;
- 对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
- 对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在S2S结构上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。这是相当直观的一种改造方法。当然,也可以更简单一点,比如直接在单个Transformer结构上加装隐层产生输出也是可以的。
与GPT区别:
- 最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型
- 另外一点是语言模型的数据规模要比GPT大
优点:
- 在各种类型的NLP任务中达到目前最好的效果,某些任务性能有极大的提升
Bert最关键两点:
- 一点是特征抽取器采用Transformer;
- 第二点是预训练的时候采用双向语言模型。

创新点:
- Masked 语言模型:
①随机选择语料中15%的单词,用[Mask]掩码代替原始单词,
②然后要求模型去正确预测被抠掉的单词。
③15%的被上天选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记
④10%被狸猫换太子随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。 - Next Sentence Prediction:
①一种是选择语料中真正顺序相连的两个句子;
②另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。
