在开始这个内容之前,我们先来一张效果图:
实现它,需要几个过程:
- 调用王者荣耀助手的数据接口获取所有英雄的图片
- 通过迭代,把所有图片转换成二进制数据流
- 把这些数据导入MySQL数据库中
由于项目需求,需要爬取某网站数据并储存在mysql中,但这几天遇到了一些问题,不得不暂停来补一补数据抓取的相关知识,于是今天花了半天时间来补习json.我以下写的内容是 居然老师 教我的,我经过整理,写在这里,给大家一起学习.
手机端请求王者荣耀服务器的url地址即爬取王者荣耀app的数据接口: http://gamehelper.gm825.com/wzry/hero/list,具体获取方法需要用到网络抓包工具,该地址可直接使用.
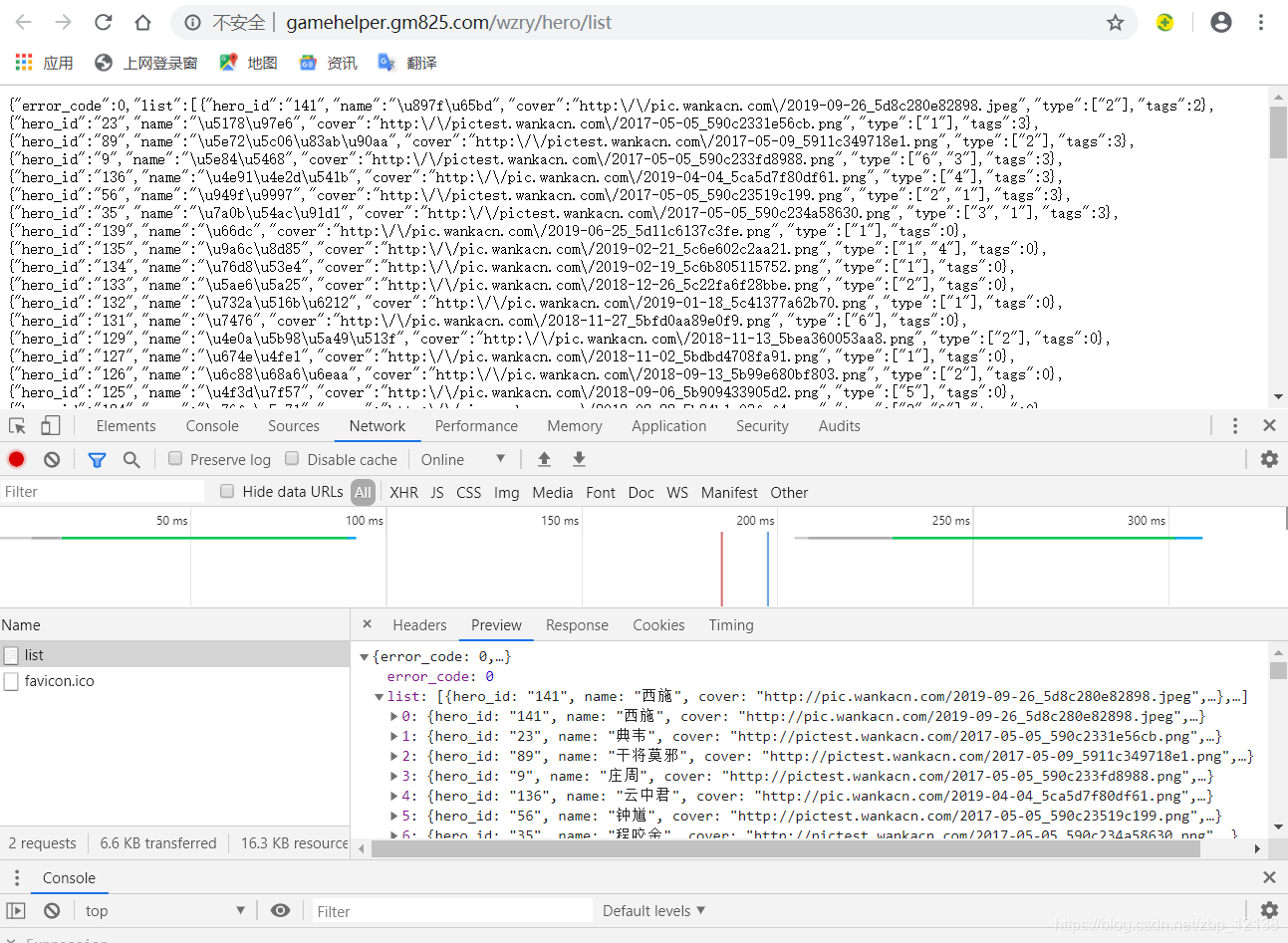
进入后,会发现这是一个英雄列表,咱们来解析一下,在这里,我使用的是: 在线JSON校验格式化工具(Be JSON),把刚刚的json串复制下来:
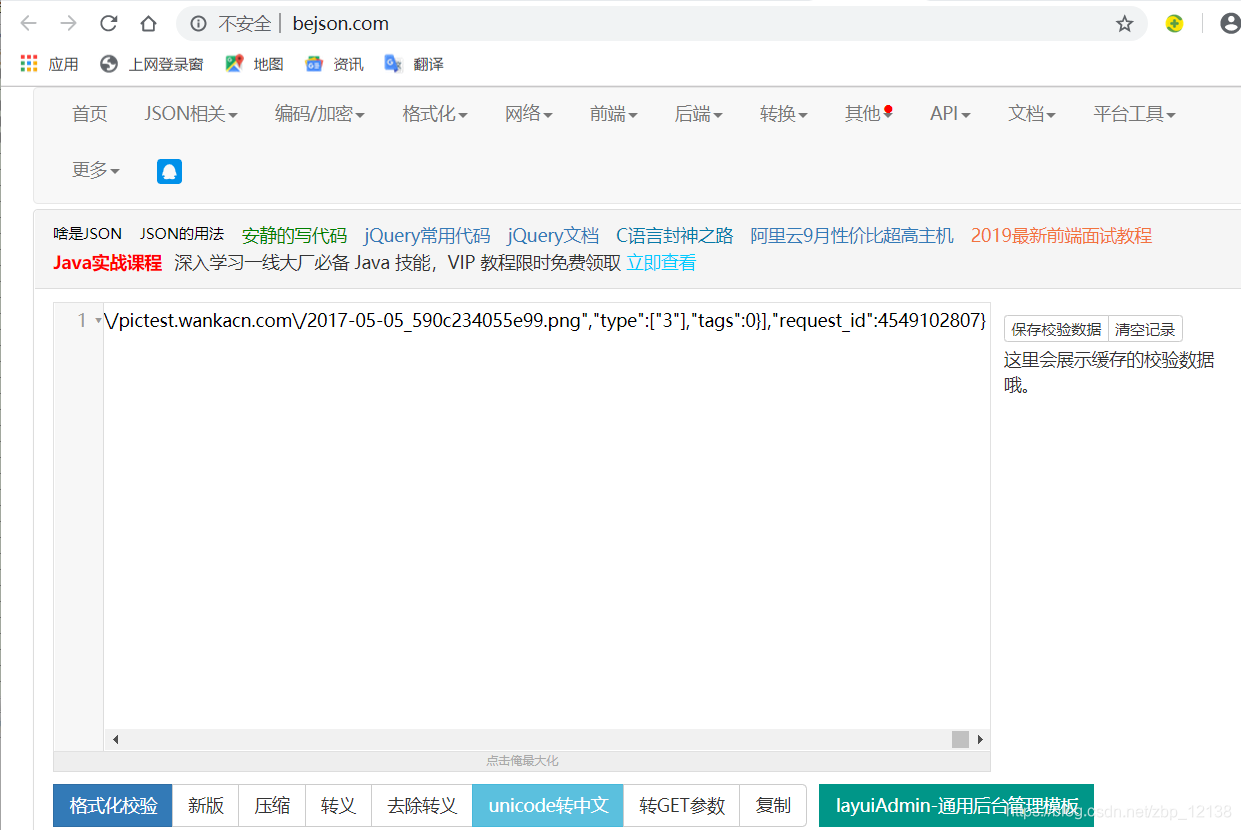
点击格式化校验后,点击unicode转中文,就可以明显看到我们想要获取的数据了.
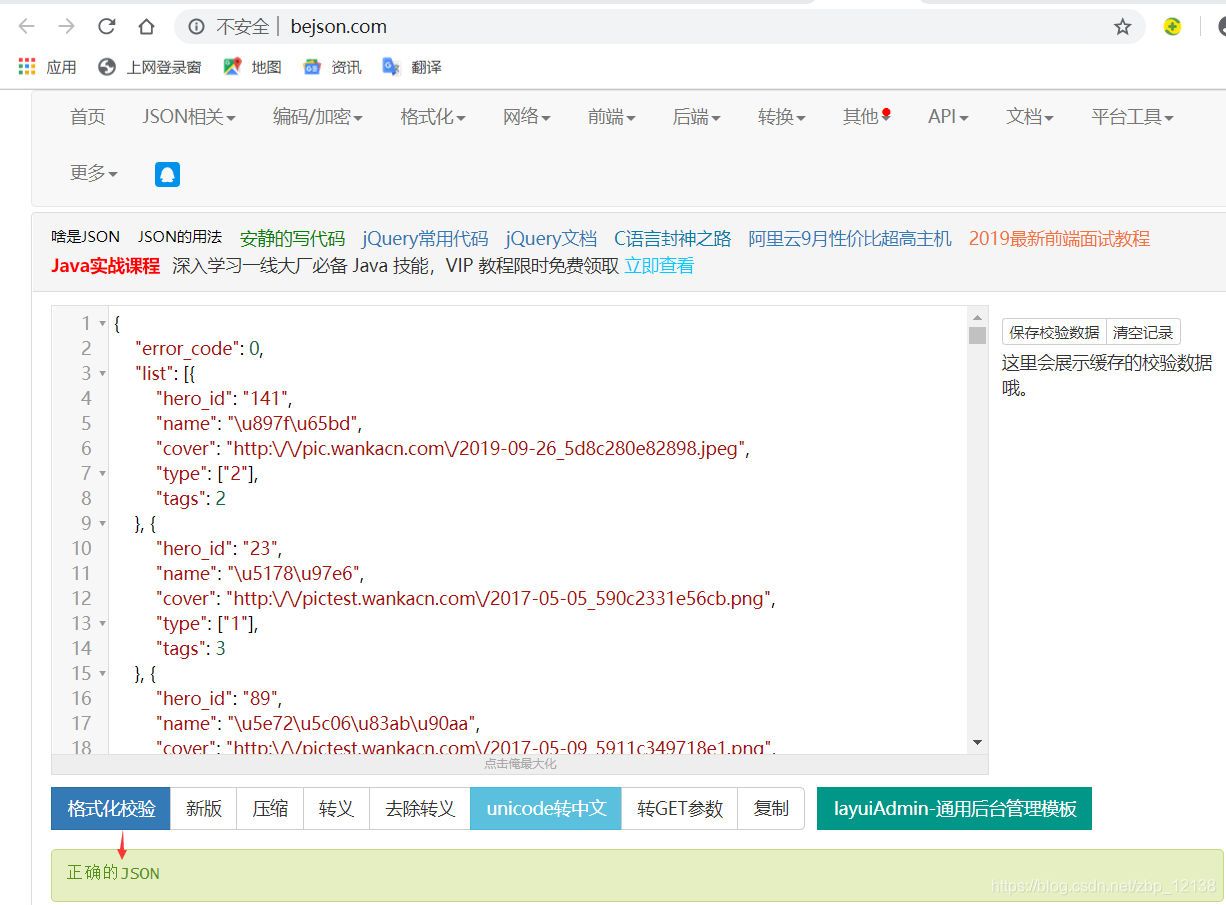
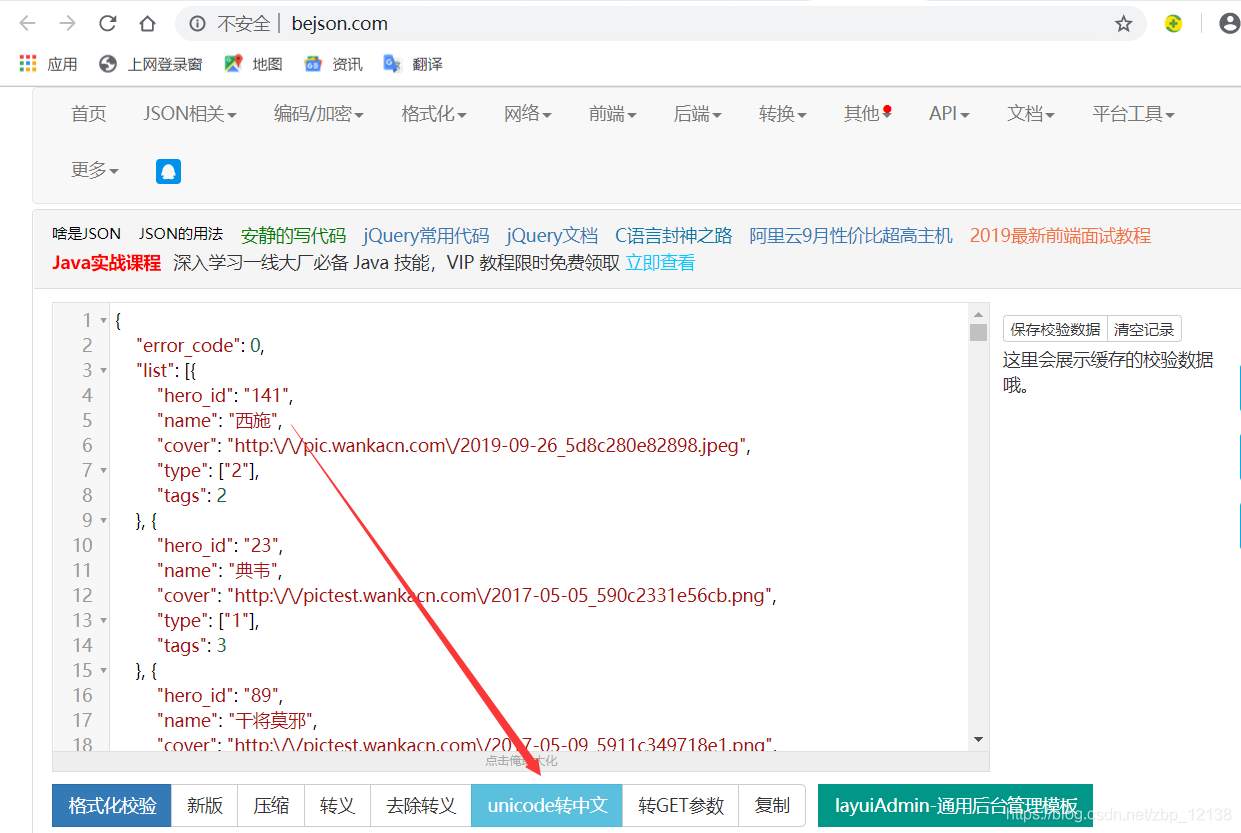
可以看到,每个英雄都有一个hero_id,还有name, 接下来的cover里存的是该英雄的图片地址,既然有了地址,那就可以爬取到图片了.
那么问题又来了,爬虫的原理到底是什么呢?在此之前,我们先来讲讲目前的网站结构,以PHP动态网站为例以下是PHP动态网站的组成:

由图可知,我们日常的上网,无非就是用我们的电脑访问对方的电脑(服务器),以此来获取我们想要的东西,但是一个服务器上存放的数据是相当庞大的,普通用户如果要用一个个复制粘贴的方法,会浪费很多的时间,因此,就有了网络爬虫.
简单来说,网络爬虫无非就是一个自动化抓取服务器数据的过程,只要你想要爬的服务器开放了端口,那么一定就有方法获取其中的数据.
接下来,我们进入代码的部分:
首先,写一个main函数,然后再定义一个主函数:
def main():
Pass
if __name__ == '__main__':
main()
接下来,定义一个函数,我在这里把它命名为: download.在这个函数里,我们需要请求url地址,把数据获取到之后,再把数据转换成我们想要的格式,然后下载,在下载时,我们需要用到”name”和”cover”.明确目标以后,我们开始导入模块:
import requests
继续在download这个函数里写代码:
url = 'http://gamehelper.gm825.com/wzry/hero/list'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
response = requests.get(url,headers=header)
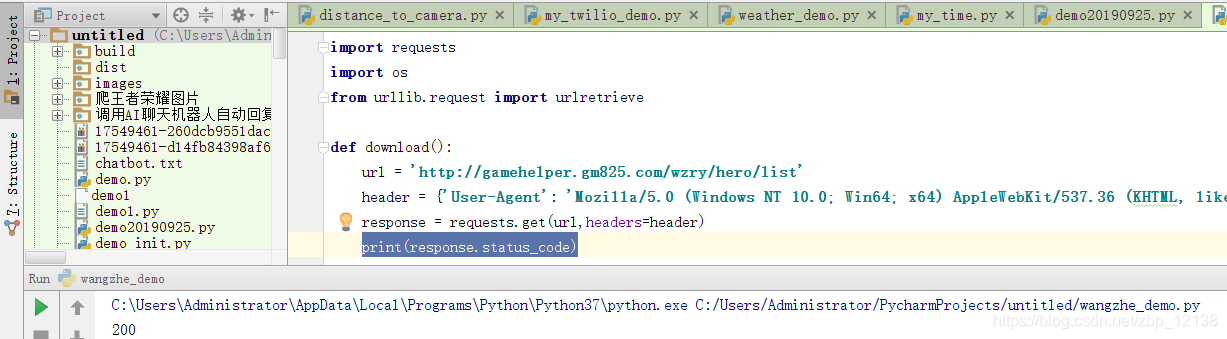
用response接收请求的数据,这个时候我们来打印一下,查看是否请求到了:
print(response.status_code)
显示200,说明请求成功!
此外,requests还有一个小技巧:
assert response.status_code == 200
如果运行后不报错,则说明请求成功!
接下来,获取数据,用json_data保存:
json_data = response.json()
打印json_data:

成功获取!
刚刚获取到的是所有信息,我们要筛选一下,获取我们想要的那部分数据,我们先试一下,先获取英雄名字.
print(json_data['list'][0]['name'])

可以看到,第一个list的name已经打印出来了,是最近新出的英雄.接下来,我们可以通过循环,把所有英雄的name和cover提取出来:
for item in json_data['list']:
name = item['name']
image_url = item['cover']
然后保存即可.在这里,我们需要用到一个能实现下载功能的函数: urlretrieve,它只需要两个参数:
- url地址
- 下载文件名称
代码如下:
urlretrieve(image_url,name+'.png')
为了显示下载过程,我们可以在前面加一句”正在下载第几张”的提示:
print("正在下载%s的图片"%name)
我们先来看看效果:
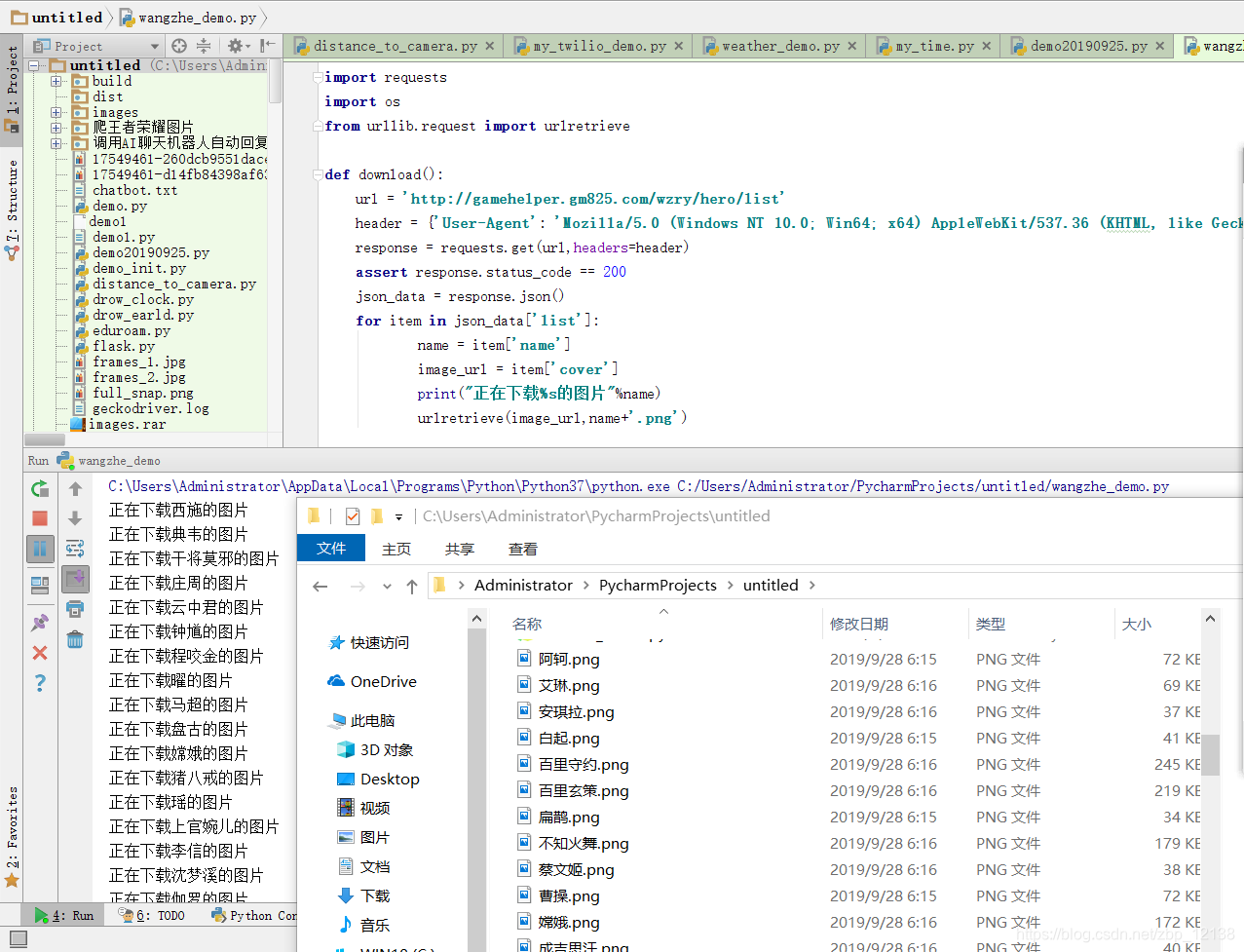
图片直接保存到我的文件目录下了!这样的做法不是我想要的,为了方便今后查看,我决定保存在一个文件夹里,我们用os这个模块判断文件夹是否创建,文件夹不存在,则创建:
image_path = 'wzry_image'
if not os.path.exists(image_path):
os.mkdir(image_path)
刚刚的urlretrieve函数也要改改:
urlretrieve(image_url, image_path+'/'+name+'.png')
但是,这样的写法并不”优雅”,因此,我们改成下面这种写法:
file_path = image_path+'/'+name+'.png'
urlretrieve(image_url,file_path)
最后运行一下:
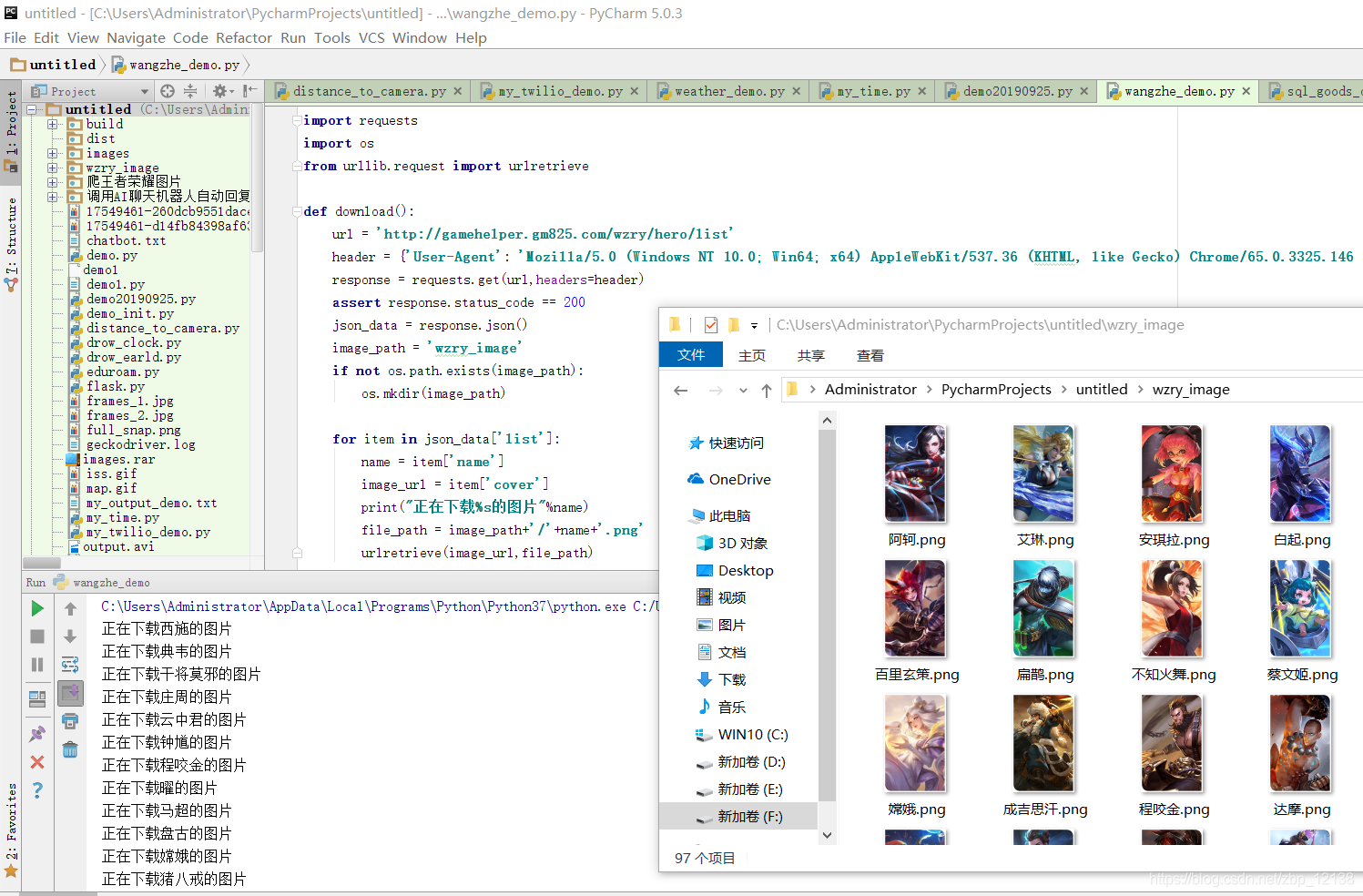
对于我来说,把图片存在文件夹里,虽然方便查看,但是还有着诸多的缺点,因此,我决定把图片存入mysql数据库中. 解决方法一般有两种:
- 将图片保存的路径存储到数据库;
- 将图片以二进制数据流的形式直接写入数据库字段中
我这里将采用第二种方法进行存储,基本思路是在图片文件以二进制流的方式读入到计算机中后,将该二进制流转换为字符串,即“图片字符串”
fp = open(file_path, 'rb')
image_data = fp.read()
这两行是关键代码,其实非常简单,只是需要注意几个细节:
- r表示是文本文件,rb是二进制文件。而这个mode参数默认值就是r
- read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中
接下来我们打印一下:
print(image_data)
某张图片的部分输出结果是:
b’\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00\xc8\x00\x00\x01@\x08\x03\x00\x00\x00\xce\x12\xc3\xad\x00\x00\x03\x00PLTE\x00\x00\x00\xb5\x82W\xd9\xb7\xa6\xd4\xa2O\x9fiG\xe1\xaeq\xe6\x814\xde\xb4_G=G\xea\x9a:\x8bXG1!"cX`$\x… … …
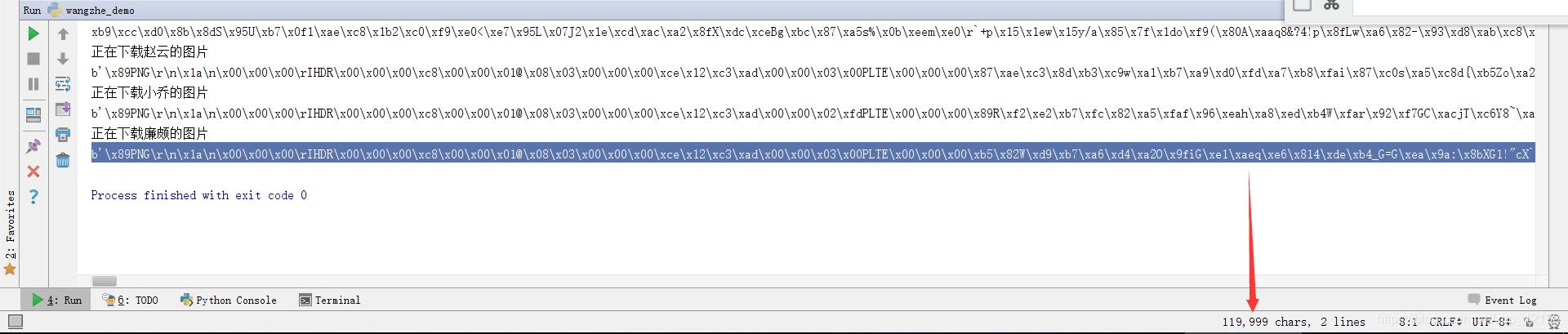
可以看到, 这张图的“图片字符串”长达12万!
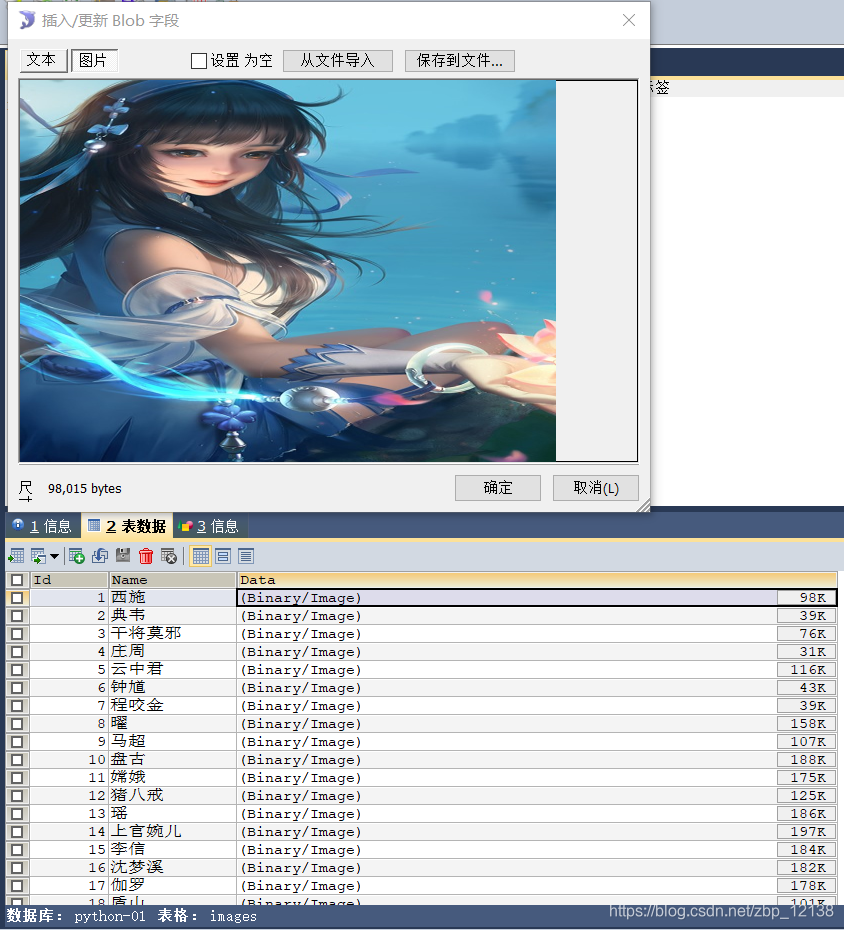
我们进入MySQL中看一看数据表:
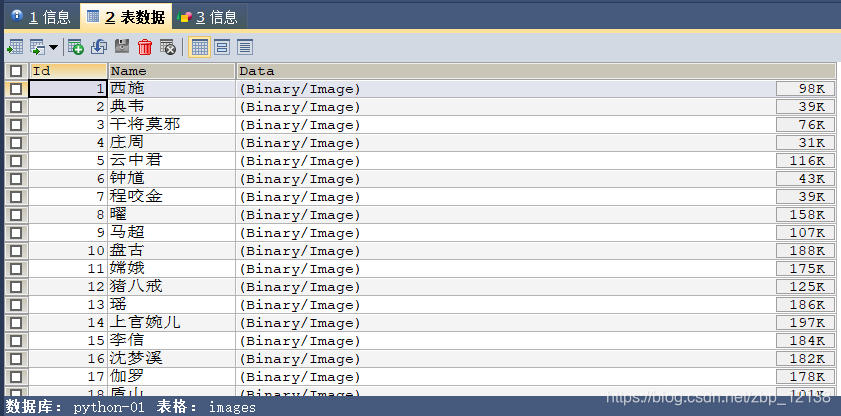
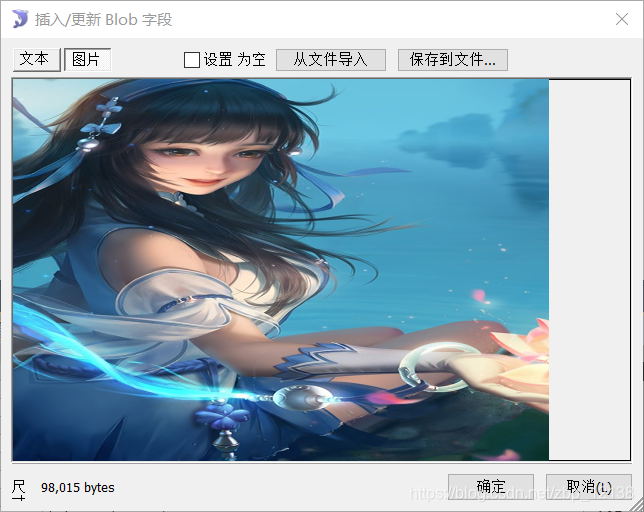
图片在数据库中的可视化结果:
以上就是我今天要分享的内容,欢迎大家跟我交流:
QQ:2733821739 哓哓晓培
