契机
GBDT算法一个比较大的问题在于其耗时很大,因为每次建立一棵树的一个节点,都要遍历所有的特征,且对于每个特征,都要搜索所有可能的分割值,才能找到具有最优分割点的最优特征,训练的耗时在工业界是没有办法接受的,因而需要从入下两个方面入手来解决上述问题:
- 减少训练样本,从而减少训练时遍历样本的时间
- 减少参与计算的特征,从而减少寻找具有最优分割点的最优特征的耗时
后文会对上面两种手段分别讲述一种算法来介绍lightGBM是如何在不降低过多精度的前提下加快训练和预测的速度的。
具体手段
lightGBM中的两个减少耗时的算法分别为GOSS(Gradient-based One-Side Sampling)和EFB(Exclusive Feature Bundling),下面会具体讲述两种算法的做法。
1. GOSS
lightGBM无法像adaboost那样对每个训练样本赋予一个权重,但可以观察到,样本的梯度越大,其对训练的影响也就越大,因而它务必要参与到训练过程中,相反梯度小的样本对训练的影响不是很大,因而加入它参加训练的意义不是很大。受到上述内容的启发,可以通过对梯度的大小对每个训练样本进行排序,从而使得梯度大的样本参与训练的概率大,梯度小的参与训练的概率小,这样就能够做到在降低耗时的前提下精度不至于损失太多。算法的原理如下所示:
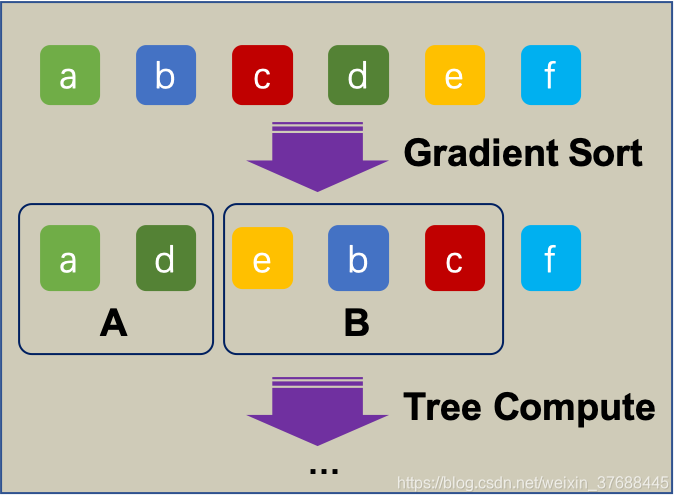
- 选择梯度top a%的数据A
- 从(1-a%)的数据中选择b%的数据B
- 在特征计算中,对B中的训练样本的info gain都乘以[(1-a%)/b%]
上述算法的简易图示如下所示:
2. EFB
如果特征是高维的,通常情况下特征的取值是较为稀疏的,因而如果能够将互斥的特征(不会同时不为0)合并为一个特征(bundle),那么就能大大降低特征数,从而降低训练的耗时。而如何确定哪些特征是绑定在一起的,本身就是NP难问题,这里给出了一个近似的解决方案。
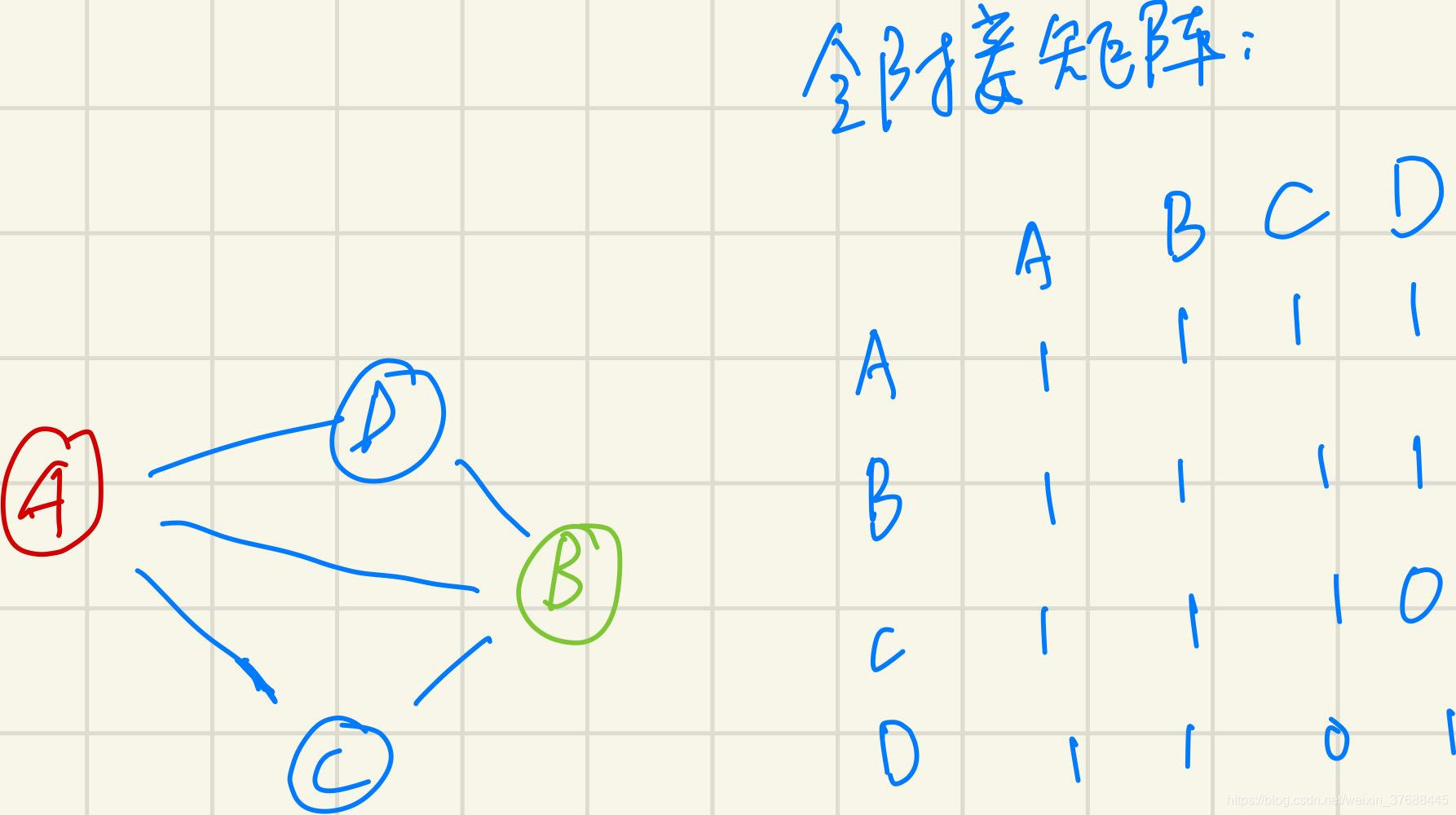
lightGBM的作者将寻找互斥特征的过程转化为图着色的过程,即构建一个图<V,E>,图的每个节点代表的是一个特征,如果特征
和特征
之间如果不是互斥的,则两个特征之间会有一条边相连。而现在的任务就是用最少的颜色去对所有的节点染色,使得相邻的节点之间颜色不同。简易图如下所示:
而现实情况下,并不是说只要两个特征之间有冲突,就无法并存在一个bundle中,而是两个特征的冲突在一定的容忍范围内,就可以作为互斥特征,于是有了如下原始算法:
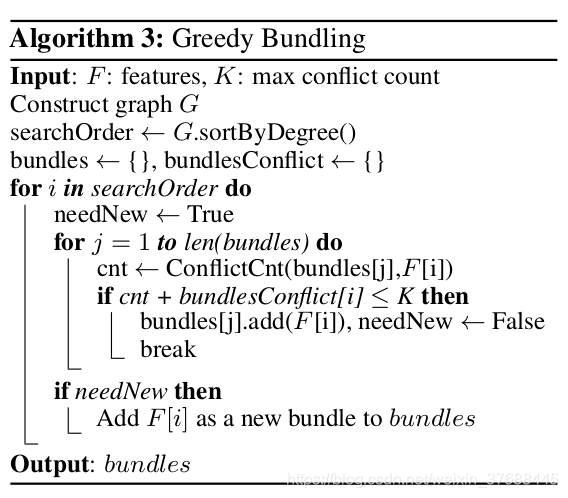
个人觉得这个算法的结构描述有些问题,不知道是因为个人没有理解透彻还是说作者本身发表的文章就有问题,我个人更改的算法如下所示:
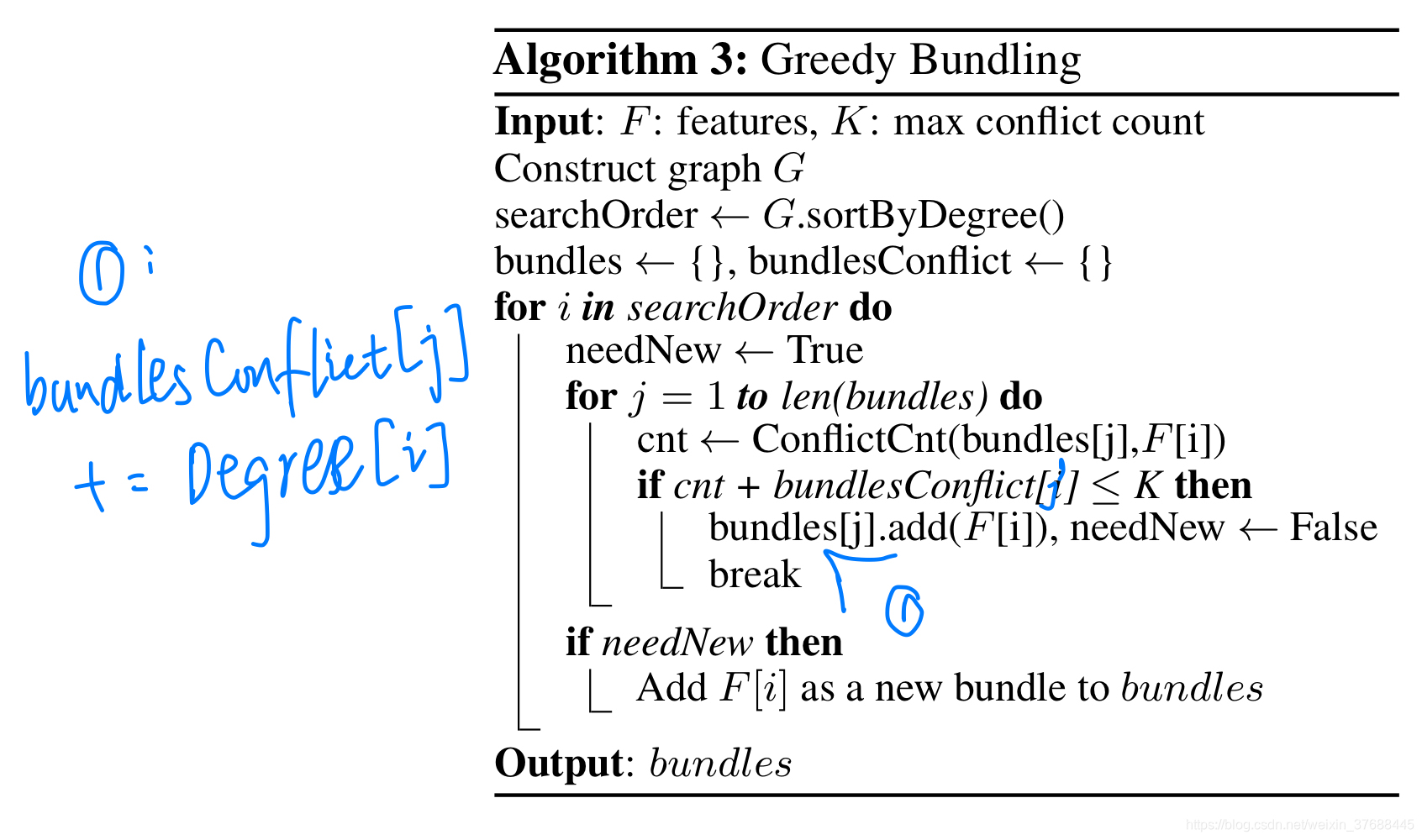
一开始根据度对图上的节点进行排序,之后外层遍历每一个
,内层去遍历bundles,如果
与
之间的冲突数和
中本身的累积冲突数的加和小于一定的数值(K)的话,则将
加入到
的阵营中,之后
本身的累积冲突数需要叠加上
的冲突数,这样就能够做到这个bundle累加到一定的地步的时候,就必须要创建一个新的bundle来装新的特征。
将bundles构建好之后开始进行merge特征,因为同一个bundle内的特征的取值范围需要统一,比如A和B是同一个bundle的,A的取值范围是[0,10), B的取值范围是[10,20), 则合并后的新的特征的取值范围是[0,30)。具体的算法目前没有看懂,需要看源码后再来做补充,因而这里未完待续…
