 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
集成学习:Bagging、随机森林、Boosting、GBDT
5.5 lightGBM
1 写在介绍lightGBM之前
1.1 lightGBM演进过程
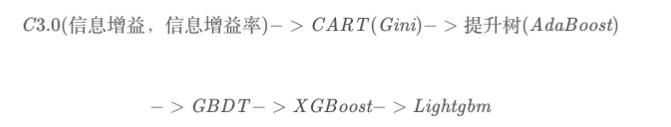
1.2 AdaBoost算法
AdaBoost是一种提升树的方法,和三个臭皮匠,赛过诸葛亮的道理一样。
AdaBoost两个问题:
- (1) 如何改变训练数据的权重或概率分布
- 提高前一轮被弱分类器错误分类的样本的权重,降低前一轮被分对的权重
- (2) 如何将弱分类器组合成一个强分类器,亦即,每个分类器,前面的权重如何设置
- 采取”多数表决”的方法.加大分类错误率小的弱分类器的权重,使其作用较大,而减小分类错误率大的弱分类器的权重,使其在表决中起较小的作用。
1.3 GBDT算法以及优缺点
GBDT和AdaBosst很类似,但是又有所不同。
- GBDT和其它Boosting算法一样,通过将表现一般的几个模型(通常是深度固定的决策树)组合在一起来集成一个表现较好的模型。
- AdaBoost是通过提升错分数据点的权重来定位模型的不足, Gradient Boosting通过负梯度来识别问题,通过计算负梯度来改进模型,即通过反复地选择一个指向负梯度方向的函数,该算法可被看做在函数空间里对目标函数进行优化。
因此可以说 。
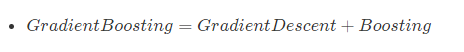
缺点:
GBDT ->预排序方法(pre-sorted)
- (1) 空间消耗大。
- 这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。
- (2) 时间上也有较大的开销。
- 在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
- (3) 对内存(cache)优化不友好。
- 在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。
- 同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
1.4 启发
常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制。
而GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。
如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
2 什么是lightGBM
lightGBM是2017年1月,微软在GItHub上开源的一个新的梯度提升框架。
在开源之后,就被别人冠以“速度惊人”、“支持分布式”、“代码清晰易懂”、“占用内存小”等属性。
LightGBM主打的高效并行训练让其性能超越现有其他boosting工具。在Higgs数据集上的试验表明,LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6。
higgs数据集介绍:这是一个分类问题,用于区分产生希格斯玻色子的信号过程和不产生希格斯玻色子的信号过程。
3 lightGBM原理
lightGBM 主要基于以下方面优化,提升整体特特性:
- 基于Histogram(直方图)的决策树算法
- Lightgbm 的Histogram(直方图)做差加速
- 带深度限制的Leaf-wise的叶子生长策略
- 直接支持类别特征
- 直接支持高效并行
具体解释见下,分节介绍。
3.1 基于Histogram(直方图)的决策树算法
直方图算法的基本思想是
- 先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。
- 在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
Eg:
[0, 0.1) --> 0;
[0.1,0.3) --> 1;
...

使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。

然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
3.2 Lightgbm 的Histogram(直方图)做差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。
通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。
利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

3.3 带深度限制的Leaf-wise的叶子生长策略
Level-wise便利一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。
- 但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。

Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。
- 因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
- Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。

3.4 直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1特征,降低了空间和时间的效率。
而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。
在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。目前来看,LightGBM是第一个直接支持类别特征的GBDT工具。
Expo数据集介绍:数据包含1987年10月至2008年4月美国境内所有商业航班的航班到达和离开的详细信息。这是一个庞大的数据集:总共有近1.2亿条记录。主要用于预测航班是否准时。
3.5 直接支持高效并行
LightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。
- 特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
- 数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化:
-
在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;

在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。

基于投票的数据并行(Voting Parallelization)则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。

4 小结
-
lightGBM 演进过程

lightGBM优势
- 基于Histogram(直方图)的决策树算法
- Lightgbm 的Histogram(直方图)做差加速
- 带深度限制的Leaf-wise的叶子生长策略
- 直接支持类别特征
- 直接支持高效并行
5.6 lightGBM算法api介绍
1 lightGBM的安装
- windows下:
pip3 install lightgbm
-
mac下:
2 lightGBM参数介绍
2.1 Control Parameters
| Control Parameters | 含义 | 用法 |
|---|---|---|
| max_depth | 树的最大深度 | 当模型过拟合时,可以考虑首先降低 max_depth |
| min_data_in_leaf | 叶子可能具有的最小记录数 | 默认20,过拟合时用 |
| feature_fraction | 例如 为0.8时,意味着在每次迭代中随机选择80%的参数来建树 | boosting 为 random forest 时用 |
| bagging_fraction | 每次迭代时用的数据比例 | 用于加快训练速度和减小过拟合 |
| early_stopping_round | 如果一次验证数据的一个度量在最近的early_stopping_round 回合中没有提高,模型将停止训练 | 加速分析,减少过多迭代 |
| lambda | 指定正则化 | 0~1 |
| min_gain_to_split | 描述分裂的最小 gain | 控制树的有用的分裂 |
| max_cat_group | 在 group 边界上找到分割点 | 当类别数量很多时,找分割点很容易过拟合时 |
| n_estimators | 最大迭代次数 | 最大迭代数不必设置过大,可以在进行一次迭代后,根据最佳迭代数设置 |
2.2 Core Parameters
| Core Parameters | 含义 | 用法 |
|---|---|---|
| Task | 数据的用途 | 选择 train 或者 predict |
| application | 模型的用途 | 选择 regression: 回归时, binary: 二分类时, multiclass: 多分类时 |
| boosting | 要用的算法 | gbdt, rf: random forest, dart: Dropouts meet Multiple Additive Regression Trees, goss: Gradient-based One-Side Sampling |
| num_boost_round | 迭代次数 | 通常 100+ |
| learning_rate | 学习率 | 常用 0.1, 0.001, 0.003… |
| num_leaves | 叶子数量 | 默认 31 |
| device | cpu 或者 gpu | |
| metric | mae: mean absolute error , mse: mean squared error , binary_logloss: loss for binary classification , multi_logloss: loss for multi classification |
2.3 IO parameter
| IO parameter | 含义 |
|---|---|
| max_bin | 表示 feature 将存入的 bin 的最大数量 |
| categorical_feature | 如果 categorical_features = 0,1,2, 则列 0,1,2是 categorical 变量 |
| ignore_column | 与 categorical_features 类似,只不过不是将特定的列视为categorical,而是完全忽略 |
| save_binary | 这个参数为 true 时,则数据集被保存为二进制文件,下次读数据时速度会变快 |
3 调参建议
| IO parameter | 含义 |
|---|---|
num_leaves |
取值应 <= 2^{(max\_depth)}2(max_depth), 超过此值会导致过拟合 |
min_data_in_leaf |
将它设置为较大的值可以避免生长太深的树,但可能会导致 underfitting,在大型数据集时就设置为数百或数千 |
max_depth |
这个也是可以限制树的深度 |
下表对应了 Faster Speed ,better accuracy ,over-fitting 三种目的时,可以调的参数
| Faster Speed | better accuracy | over-fitting |
|---|---|---|
将 max_bin 设置小一些 |
用较大的 max_bin |
max_bin 小一些 |
num_leaves 大一些 |
num_leaves 小一些 |
|
用 feature_fraction来做 sub-sampling |
用 feature_fraction |
|
用 bagging_fraction 和 bagging_freq |
设定 bagging_fraction 和 bagging_freq |
|
| training data 多一些 | training data 多一些 | |
用 save_binary来加速数据加载 |
直接用 categorical feature | 用 gmin_data_in_leaf 和 min_sum_hessian_in_leaf |
| 用 parallel learning | 用 dart | 用 lambda_l1, lambda_l2 ,min_gain_to_split 做正则化 |
num_iterations 大一些,learning_rate小一些 |
用 max_depth 控制树的深度 |
5.7 lightGBM案例介绍
接下来,通过鸢尾花数据集对lightGBM的基本使用,做一个介绍。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
加载数据,对数据进行基本处理
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
模型训练
gbm = lgb.LGBMRegressor(objective='regression', learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
gbm.score(X_test, y_test)
# 0.810605595102488

# 网格搜索,参数优化
estimator = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40]
}
gbm = GridSearchCV(estimator, param_grid, cv=4)
gbm.fit(X_train, y_train)
print('Best parameters found by grid search are:', gbm.best_params_)
# Best parameters found by grid search are: {'learning_rate': 0.1, 'n_estimators': 40}
模型调优训练
gbm = lgb.LGBMRegressor(num_leaves=31, learning_rate=0.1, n_estimators=40)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
gbm.score(X_test, y_test)
# 0.9536626296481988In [1]:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
读取数据
In [2]:
iris = load_iris()
data = iris.data
target = iris.target
In [3]:
data
Out[3]:
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1],
[5.4, 3.7, 1.5, 0.2],
[4.8, 3.4, 1.6, 0.2],
[4.8, 3. , 1.4, 0.1],
[4.3, 3. , 1.1, 0.1],
[5.8, 4. , 1.2, 0.2],
[5.7, 4.4, 1.5, 0.4],
[5.4, 3.9, 1.3, 0.4],
[5.1, 3.5, 1.4, 0.3],
[5.7, 3.8, 1.7, 0.3],
[5.1, 3.8, 1.5, 0.3],
[5.4, 3.4, 1.7, 0.2],
[5.1, 3.7, 1.5, 0.4],
[4.6, 3.6, 1. , 0.2],
[5.1, 3.3, 1.7, 0.5],
[4.8, 3.4, 1.9, 0.2],
[5. , 3. , 1.6, 0.2],
[5. , 3.4, 1.6, 0.4],
[5.2, 3.5, 1.5, 0.2],
[5.2, 3.4, 1.4, 0.2],
[4.7, 3.2, 1.6, 0.2],
[4.8, 3.1, 1.6, 0.2],
[5.4, 3.4, 1.5, 0.4],
[5.2, 4.1, 1.5, 0.1],
[5.5, 4.2, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.2],
[5. , 3.2, 1.2, 0.2],
[5.5, 3.5, 1.3, 0.2],
[4.9, 3.6, 1.4, 0.1],
[4.4, 3. , 1.3, 0.2],
[5.1, 3.4, 1.5, 0.2],
[5. , 3.5, 1.3, 0.3],
[4.5, 2.3, 1.3, 0.3],
[4.4, 3.2, 1.3, 0.2],
[5. , 3.5, 1.6, 0.6],
[5.1, 3.8, 1.9, 0.4],
[4.8, 3. , 1.4, 0.3],
[5.1, 3.8, 1.6, 0.2],
[4.6, 3.2, 1.4, 0.2],
[5.3, 3.7, 1.5, 0.2],
[5. , 3.3, 1.4, 0.2],
[7. , 3.2, 4.7, 1.4],
[6.4, 3.2, 4.5, 1.5],
[6.9, 3.1, 4.9, 1.5],
[5.5, 2.3, 4. , 1.3],
[6.5, 2.8, 4.6, 1.5],
[5.7, 2.8, 4.5, 1.3],
[6.3, 3.3, 4.7, 1.6],
[4.9, 2.4, 3.3, 1. ],
[6.6, 2.9, 4.6, 1.3],
[5.2, 2.7, 3.9, 1.4],
[5. , 2. , 3.5, 1. ],
[5.9, 3. , 4.2, 1.5],
[6. , 2.2, 4. , 1. ],
[6.1, 2.9, 4.7, 1.4],
[5.6, 2.9, 3.6, 1.3],
[6.7, 3.1, 4.4, 1.4],
[5.6, 3. , 4.5, 1.5],
[5.8, 2.7, 4.1, 1. ],
[6.2, 2.2, 4.5, 1.5],
[5.6, 2.5, 3.9, 1.1],
[5.9, 3.2, 4.8, 1.8],
[6.1, 2.8, 4. , 1.3],
[6.3, 2.5, 4.9, 1.5],
[6.1, 2.8, 4.7, 1.2],
[6.4, 2.9, 4.3, 1.3],
[6.6, 3. , 4.4, 1.4],
[6.8, 2.8, 4.8, 1.4],
[6.7, 3. , 5. , 1.7],
[6. , 2.9, 4.5, 1.5],
[5.7, 2.6, 3.5, 1. ],
[5.5, 2.4, 3.8, 1.1],
[5.5, 2.4, 3.7, 1. ],
[5.8, 2.7, 3.9, 1.2],
[6. , 2.7, 5.1, 1.6],
[5.4, 3. , 4.5, 1.5],
[6. , 3.4, 4.5, 1.6],
[6.7, 3.1, 4.7, 1.5],
[6.3, 2.3, 4.4, 1.3],
[5.6, 3. , 4.1, 1.3],
[5.5, 2.5, 4. , 1.3],
[5.5, 2.6, 4.4, 1.2],
[6.1, 3. , 4.6, 1.4],
[5.8, 2.6, 4. , 1.2],
[5. , 2.3, 3.3, 1. ],
[5.6, 2.7, 4.2, 1.3],
[5.7, 3. , 4.2, 1.2],
[5.7, 2.9, 4.2, 1.3],
[6.2, 2.9, 4.3, 1.3],
[5.1, 2.5, 3. , 1.1],
[5.7, 2.8, 4.1, 1.3],
[6.3, 3.3, 6. , 2.5],
[5.8, 2.7, 5.1, 1.9],
[7.1, 3. , 5.9, 2.1],
[6.3, 2.9, 5.6, 1.8],
[6.5, 3. , 5.8, 2.2],
[7.6, 3. , 6.6, 2.1],
[4.9, 2.5, 4.5, 1.7],
[7.3, 2.9, 6.3, 1.8],
[6.7, 2.5, 5.8, 1.8],
[7.2, 3.6, 6.1, 2.5],
[6.5, 3.2, 5.1, 2. ],
[6.4, 2.7, 5.3, 1.9],
[6.8, 3. , 5.5, 2.1],
[5.7, 2.5, 5. , 2. ],
[5.8, 2.8, 5.1, 2.4],
[6.4, 3.2, 5.3, 2.3],
[6.5, 3. , 5.5, 1.8],
[7.7, 3.8, 6.7, 2.2],
[7.7, 2.6, 6.9, 2.3],
[6. , 2.2, 5. , 1.5],
[6.9, 3.2, 5.7, 2.3],
[5.6, 2.8, 4.9, 2. ],
[7.7, 2.8, 6.7, 2. ],
[6.3, 2.7, 4.9, 1.8],
[6.7, 3.3, 5.7, 2.1],
[7.2, 3.2, 6. , 1.8],
[6.2, 2.8, 4.8, 1.8],
[6.1, 3. , 4.9, 1.8],
[6.4, 2.8, 5.6, 2.1],
[7.2, 3. , 5.8, 1.6],
[7.4, 2.8, 6.1, 1.9],
[7.9, 3.8, 6.4, 2. ],
[6.4, 2.8, 5.6, 2.2],
[6.3, 2.8, 5.1, 1.5],
[6.1, 2.6, 5.6, 1.4],
[7.7, 3. , 6.1, 2.3],
[6.3, 3.4, 5.6, 2.4],
[6.4, 3.1, 5.5, 1.8],
[6. , 3. , 4.8, 1.8],
[6.9, 3.1, 5.4, 2.1],
[6.7, 3.1, 5.6, 2.4],
[6.9, 3.1, 5.1, 2.3],
[5.8, 2.7, 5.1, 1.9],
[6.8, 3.2, 5.9, 2.3],
[6.7, 3.3, 5.7, 2.5],
[6.7, 3. , 5.2, 2.3],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]])In [4]:
target
Out[4]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])数据基本处理
In [5]:
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
模型训练
模型基本训练
In [14]:
gbm = lgb.LGBMRegressor(objective="regression", learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric="l1", early_stopping_rounds=3)
gbm.score(X_test, y_test)
[1] valid_0's l1: 0.653531 valid_0's l2: 0.626219
Training until validation scores don't improve for 3 rounds
[2] valid_0's l1: 0.626209 valid_0's l2: 0.57348
[3] valid_0's l1: 0.60108 valid_0's l2: 0.525437
[4] valid_0's l1: 0.577988 valid_0's l2: 0.482521
[5] valid_0's l1: 0.555301 valid_0's l2: 0.443297
[6] valid_0's l1: 0.534806 valid_0's l2: 0.408881
[7] valid_0's l1: 0.510834 valid_0's l2: 0.372852
[8] valid_0's l1: 0.491373 valid_0's l2: 0.344015
[9] valid_0's l1: 0.469678 valid_0's l2: 0.314384
[10] valid_0's l1: 0.451908 valid_0's l2: 0.290418
[11] valid_0's l1: 0.433932 valid_0's l2: 0.268274
[12] valid_0's l1: 0.414266 valid_0's l2: 0.245211
[13] valid_0's l1: 0.398027 valid_0's l2: 0.227095
[14] valid_0's l1: 0.380293 valid_0's l2: 0.208076
[15] valid_0's l1: 0.365621 valid_0's l2: 0.193252
[16] valid_0's l1: 0.34957 valid_0's l2: 0.177498
[17] valid_0's l1: 0.336313 valid_0's l2: 0.16537
[18] valid_0's l1: 0.321785 valid_0's l2: 0.152308
[19] valid_0's l1: 0.310088 valid_0's l2: 0.142386
[20] valid_0's l1: 0.298266 valid_0's l2: 0.131543
Did not meet early stopping. Best iteration is:
[20] valid_0's l1: 0.298266 valid_0's l2: 0.131543
Out[14]:
0.7578964818630016通过网格搜索进行训练
In [11]:
estimators = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
"learning_rate": [0.01, 0.1, 1],
"n_estmators":[20, 40, 60, 80]
}
gbm = GridSearchCV(estimators, param_grid, cv=5)
gbm.fit(X_train, y_train)
Out[11]:
GridSearchCV(cv=5, error_score=nan,
estimator=LGBMRegressor(boosting_type='gbdt', class_weight=None,
colsample_bytree=1.0,
importance_type='split', learning_rate=0.1,
max_depth=-1, min_child_samples=20,
min_child_weight=0.001, min_split_gain=0.0,
n_estimators=100, n_jobs=-1, num_leaves=31,
objective=None, random_state=None,
reg_alpha=0.0, reg_lambda=0.0, silent=True,
subsample=1.0, subsample_for_bin=200000,
subsample_freq=0),
iid='deprecated', n_jobs=None,
param_grid={'learning_rate': [0.01, 0.1, 1],
'n_estmators': [20, 40, 60, 80]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)In [12]:
gbm.best_params_
Out[12]:
{'learning_rate': 0.1, 'n_estmators': 20}In [13]:
gbm = lgb.LGBMRegressor(objective="regression", learning_rate=0.1, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric="l1", early_stopping_rounds=3)
gbm.score(X_test, y_test)
[1] valid_0's l1: 0.625261 valid_0's l2: 0.571453
Training until validation scores don't improve for 3 rounds
[2] valid_0's l1: 0.574385 valid_0's l2: 0.477181
[3] valid_0's l1: 0.531459 valid_0's l2: 0.403427
[4] valid_0's l1: 0.483888 valid_0's l2: 0.33428
[5] valid_0's l1: 0.447306 valid_0's l2: 0.284716
[6] valid_0's l1: 0.413883 valid_0's l2: 0.243537
[7] valid_0's l1: 0.377047 valid_0's l2: 0.203656
[8] valid_0's l1: 0.348048 valid_0's l2: 0.175576
[9] valid_0's l1: 0.318049 valid_0's l2: 0.148479
[10] valid_0's l1: 0.29463 valid_0's l2: 0.129983
[11] valid_0's l1: 0.27226 valid_0's l2: 0.111468
[12] valid_0's l1: 0.2489 valid_0's l2: 0.0960426
[13] valid_0's l1: 0.230634 valid_0's l2: 0.0833998
[14] valid_0's l1: 0.216687 valid_0's l2: 0.0759234
[15] valid_0's l1: 0.1993 valid_0's l2: 0.0670385
[16] valid_0's l1: 0.188099 valid_0's l2: 0.0622206
[17] valid_0's l1: 0.178022 valid_0's l2: 0.058299
[18] valid_0's l1: 0.168954 valid_0's l2: 0.0551119
[19] valid_0's l1: 0.158303 valid_0's l2: 0.0505529
[20] valid_0's l1: 0.149623 valid_0's l2: 0.0466022
Did not meet early stopping. Best iteration is:
[20] valid_0's l1: 0.149623 valid_0's l2: 0.0466022
Out[13]:
0.9142290887795029
