GBDT是一个很受欢迎的机器学习算法,目前也有很多实现方法,比如说scikit-learn,LightGBM。其实关于梯度提升树不同的实现,本质就是所使用的损失函数和最小化损失函数的方法有所差异。而梯度提升算法的核心思想就是通过拟合负梯度值去学习决策树。关于梯度提升树算法的流程如下图所示:

而LightGBM与之前不同实现的区别在于,LightGBM提供一种数据类型的封装相对Numpy,Pandas,Array等数据对象而言节省了内存的使用,原因在于它只需要保存离散的直方图,LightGBM里默认的训练决策树时使用直方图算法,XGBoost里现在也提供了这一选项,不过默认的方法是对特征预排序,直方图算法是一种牺牲了一定的切分准确性而换取训练速度以及节省内存空间消耗的算法。
下面是LightGBM中GBDT的实现流程:
1.对所有特征进行分桶归一化(bin normalizing)

2.计算初始梯度值(初始值设置为0或随机值)
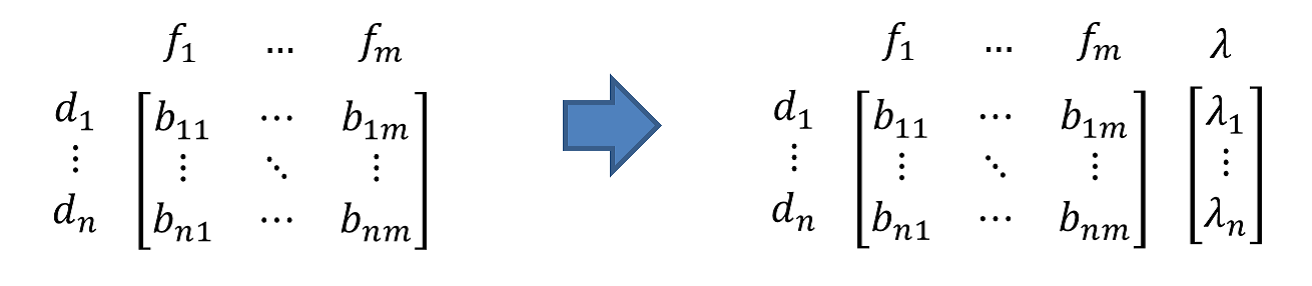
3.建立树
a)计算直方图
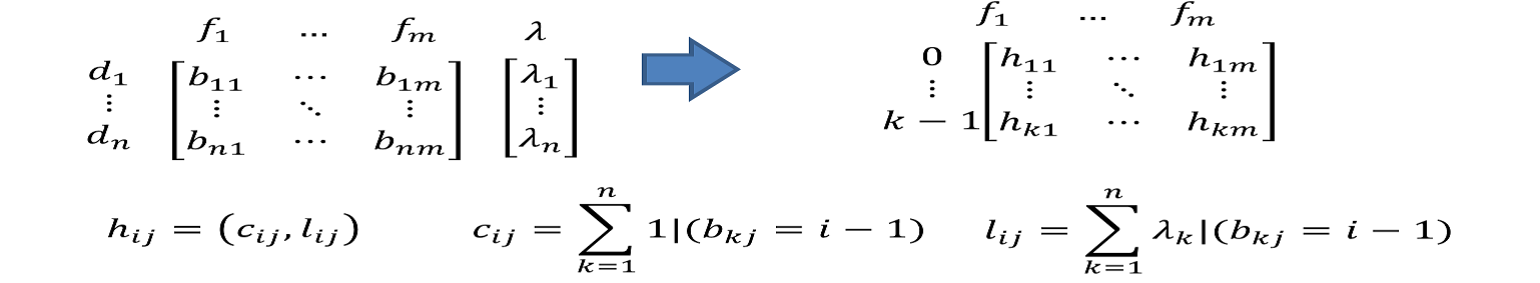
在训练决策树计算切分点的增益时,预排序需要对每个样本的切分位置计算,所以时间复杂度是O(#data)。而LightGBM则是计算将样本离散化为直方图后的直方图切割位置的增益即可,时间复杂度为O(#bins),时间效率上大大提高了
b)从直方图获得分裂收益,选取最佳分裂特征,分裂阈值
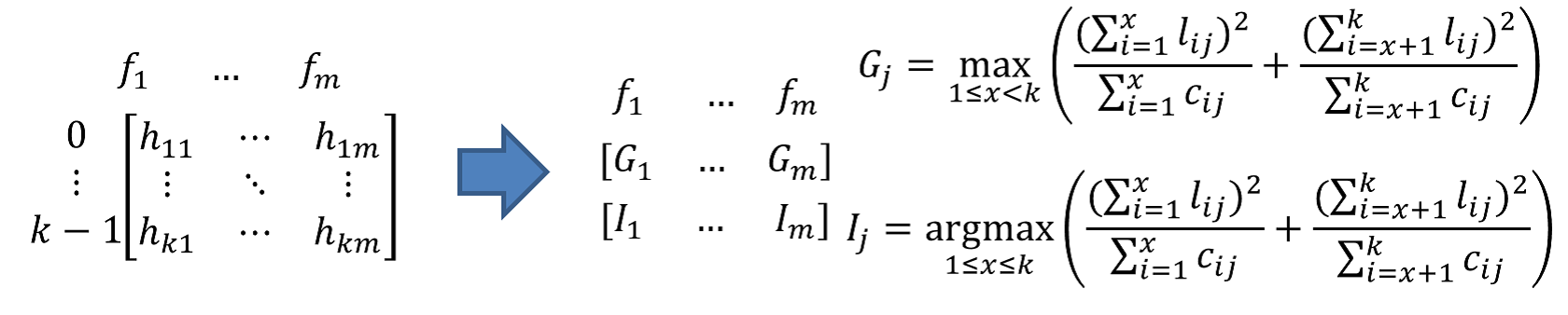
c)建立根节点

d)根据最佳分裂特征,分裂阈值将样本切分
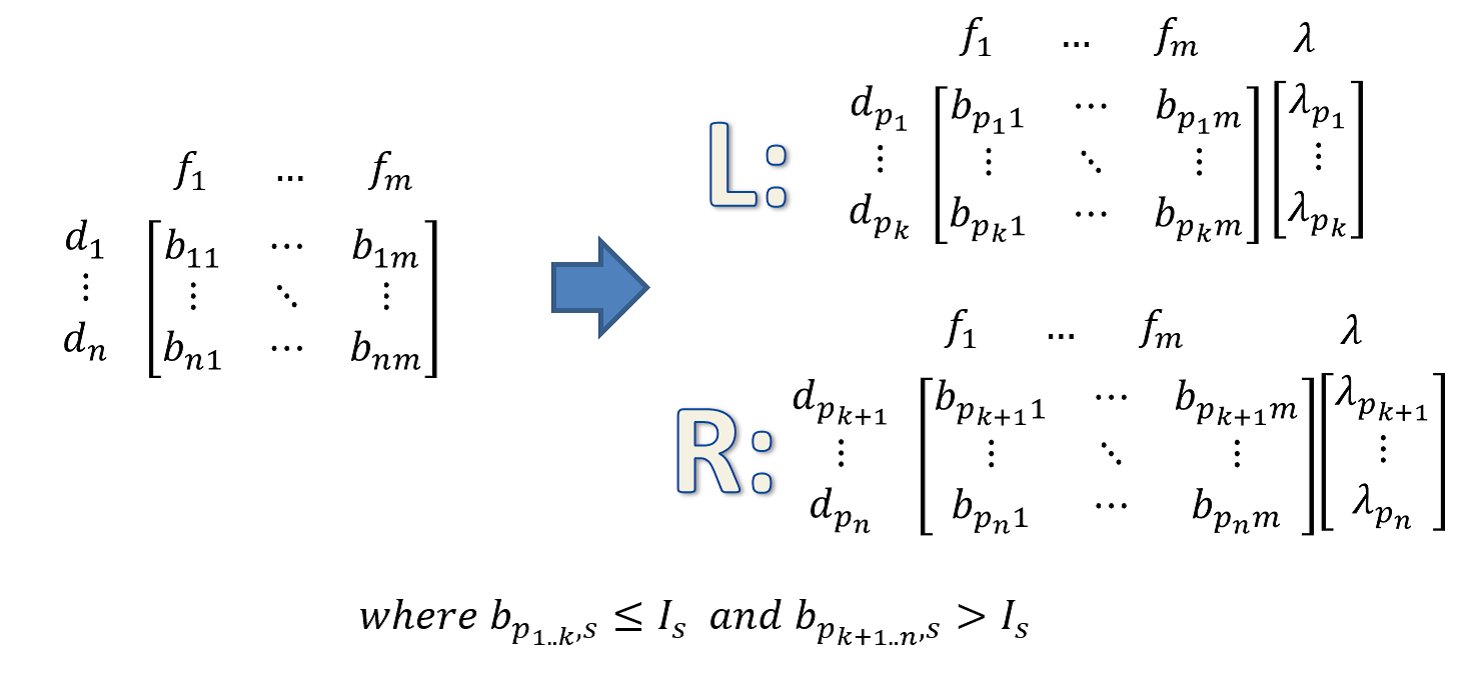
直方图做差进一步提高效率,计算某一节点的叶节点的直方图可以通过将该节点的直方图与另一子节点的直方图做差得到,所以每次分裂只需计算分裂后样本数较少的子节点的直方图然后通过做差的方式获得另一个子节点的直方图,进一步提高效率。
e)重复3.a-3.d选取最佳分裂叶子,分裂特征,分裂阈值,切分样本,直到达到叶子数目限制或者所有叶子不能分割
f)更新当前每个样本的输出值
4.根据之前得到的树更新梯度值
5.重复3,4直到所有的树都建立好
文中截图皆来源于网上,此番总结只是学习笔记。