lightGBM分类模型使用
/2019年5月11日/
1.以下我们使用sklearn中自带的数据进行lightGBM的使用示范
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
iris = load_iris()
data=iris.data
print(data)
target = iris.target
print(target)
X_train,X_test,y_train,y_test =train_test_split(data,target,test_size=0.2,random_state=42)
#对于整个data和target进行的重新的分割,test_size是指测试集占总的的比例
print(y_test,y_train)
# 创建成lgb特征的数据集格式
lgb_train = lgb.Dataset(X_train, y_train)#data (string, numpy array, pandas DataFrame, scipy.sparse or list of numpy arrays) – Data source of Dataset. If string, it represents the path to txt file. 如果是图片的话就是将图片的矩阵形式输入进去
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)#参考(数据集或无,可选(默认值=无))–如果这是用于验证的数据集,则应将培训数据用作参考。
#print(type(lgb_eval))
# 将参数写成字典下形式
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 20, # 叶子节点数
'learning_rate': 0.07, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
print('Start training...')
# 训练 cv and train
gbm = lgb.train(params,lgb_train,num_boost_round=100,valid_sets=lgb_eval,early_stopping_rounds=5)
print('Save model...')
# 保存模型到文件
gbm.save_model('model.txt')
print('Start predicting...')
# 预测数据集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# 评估模型
print(y_pred,y_test)
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) **0.5)
原理之类的如果只是要使用,其实也没有必要理解,以下推荐一位大神的博客可以了解一下。
https://blog.csdn.net/qq_24519677/article/details/82811215
2.关于lightGBM的调参问题:
a.参数微调 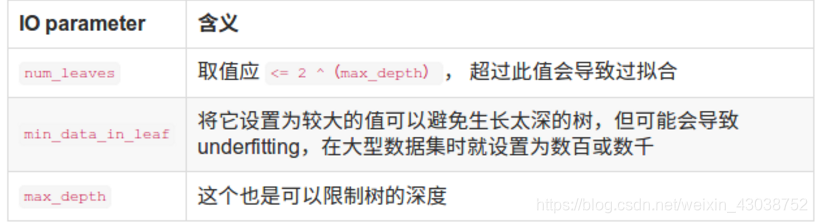
以下是某知乎作者的看法:
(1).num_leaves. This is the main parameter to control the complexity of the tree model. Theoretically, we can set num_leaves = 2^(max_depth) to convert from depth-wise tree. However, this simple conversion is not good in practice. The reason is, when number of leaves are the same, the leaf-wise tree is much deeper than depth-wise tree. As a result, it may be over-fitting. Thus, when trying to tune the num_leaves, we should let it be smaller than 2^ (max_depth). For example, when the max_depth=6 the depth-wise tree can get good accuracy, but setting num_leaves to 127 may cause over-fitting, and setting it to 70 or 80 may get better accuracy than depth-wise. Actually, the concept depth can be forgotten in leaf-wise tree, since it doesn’t have a correct mapping from leaves to depth.
(2).min_data_in_leaf This is a very important parameter to deal with over-fitting in leaf-wise tree. Its value depends on the number of training data and num_leaves. Setting it to a large value can avoid growing too deep a tree, but may cause under-fitting. In practice, setting it to hundreds or thousands is enough for a large dataset.
(3).max_depth You also can use max_depth to limit the tree depth explicitly.
b.不同情况下的参数调整

1.For Faster Speed Use bagging by setting bagging_fraction and bagging_freq Use feature sub-sampling by setting feature_fraction Use small max_bin Use save_binary to speed up data loading in future learning Use parallel learning, refer to Parallel Learning Guide
2.For Better Accuracy Use large max_bin (may be slower) Use small learning_rate with large num_iterations Use large num_leaves (may cause over-fitting) Use bigger training data Try dart
3.Deal with Over-fitting Use small max_bin Use small num_leaves Use min_data_in_leaf and min_sum_hessian_in_leaf Use bagging by set bagging_fraction and bagging_freq Use feature sub-sampling by set feature_fraction Use bigger training data Try lambda_l1, lambda_l2 and min_gain_to_split for regularization Try max_depth to avoid growing deep tree.
c.几个主要的参数:
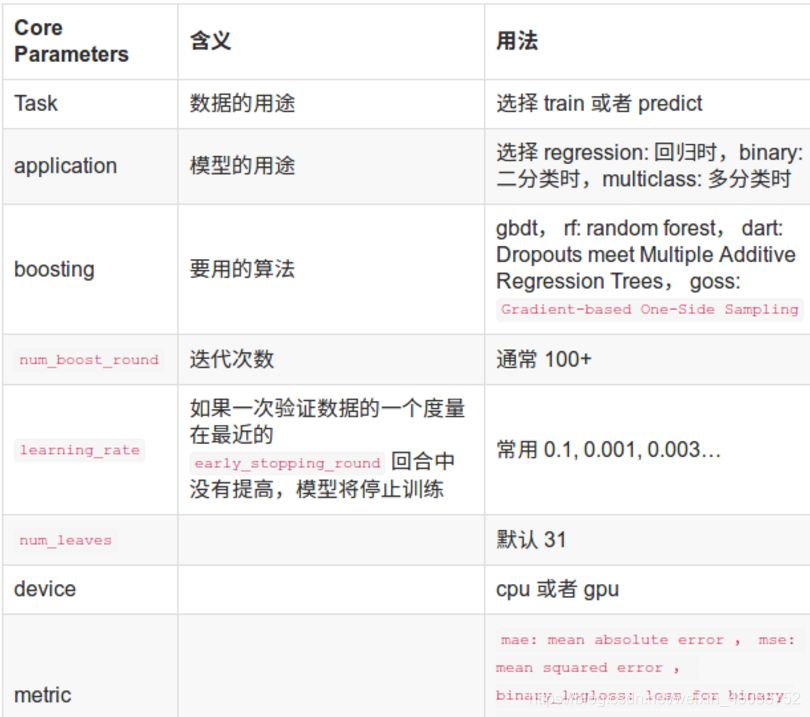 3.调参过程的自我体会
3.调参过程的自我体会
其实上面说的大都是废话,调参的过程就是一个个的去试,不同的数据集,不同的训练集测试集比例,最优的参数都是不一样的,没有捷径。要么你手动去调,要么你就自动化去测(网格搜索,随机搜索等)。别人给的只能是一定的参考范围,这仅仅是可以用在自动化去测的过程中。所有的调参都是这样的。
当然,这里还存在两个问题:如果分类过程中,准确率怎么也调不上去,维持在一个很低的水平,那么可能和输入的特征数据的结构,分布关系很大,这时考虑对特征进行降维等操作;
也有可能准确率特别高,那么就基本可以肯定是过拟合了,过拟合的原因很多,从调参角度,可以参见以上表格,从数据角度,有可能是数据量太小,或者特征不独立等。具体问题具体分析。
