本篇内容本来想在写在上篇博客中的,那样篇幅过长,就单独提出来了。
文章目录
机器学习中经常用到scikit-learn,他是一个建立在Scipy基础上的用于机器学习的Python模块。在不同的应用领域中,已经发展出为数众多的基于Scipy的工具包,他们统称为Scikits。而在所有的分支版本中,scikit-learn是最有名的,是开源的,任何人都可以免费地使用这个库或者进行二次开发。
scikit-learn包含众多顶级机器学习算法,主要有六大基本功能,分别是分类、回归、聚类、数据降维、模型选择和数据预处理。scikit-learn拥有非常活跃的用户社区,基本上其所有的功能都有非常详尽的文档供用户查阅。可以研读scikit-learn的用户指南及文档,对其算法的使用有更充分的了解。
本篇文章采用两种方式实现线性回归,一种是使用scikit-learn。而通过上篇博客,我们已经知道了最小二乘法求解线性回归参数,所以完全可以自己手动实现。
一、使用scikit-learn
API
使用到的线性回归的API::

而该API内部实现就是使用的普通最小二乘法。
功能
现有一批描述家庭用电情况的数据,对数据进行算法模型预测,并最终得到预测模型(每天各个时间段和功率之间的关系、功率与电流之间的关系等)。数据来源:Individual household electric power consumption Data Set,点击Data Folder -->household_power_consumption.zip 下载即可。
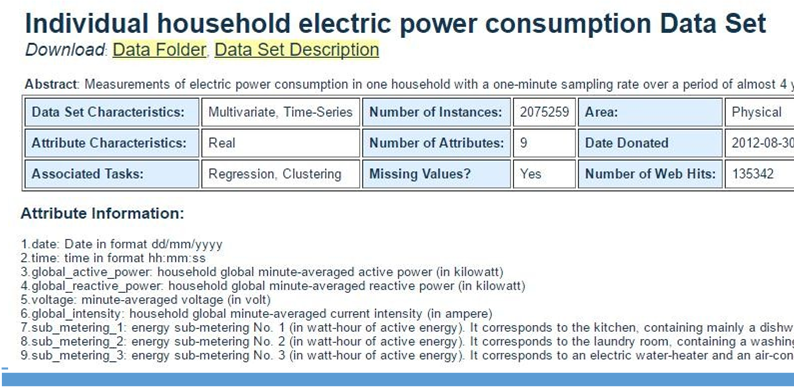
代码
代码是基于“jupyter notebook”环境下的,为了知道代码的一些中间环节,代码会中断来展示一些中间数据、图形等。
#引入线性回归的API
from sklearn.model_selection import train_test_split # 数据划分的类
from sklearn.linear_model import LinearRegression # 线性回归的类
from sklearn.preprocessing import StandardScaler # 数据标准化
# 引入其他所需要的全部包
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
import time
# 解决中文显示问题
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
# 加载数据
# 日期、时间、有功功率、无功功率、电压、电流、厨房用电功率、洗衣服用电功率、热水器用电功率
path1='datas/household_power_consumption_1000.txt'
df = pd.read_csv(path1, sep=';', low_memory=False)#没有混合类型的时候可以通过low_memory=F调用更多内存,加快效率)
df.head() ## 获取前五行数据查看查看

# 查看格式信息
df.info()

数据中会有一些异常数据,所以需要处理一下:
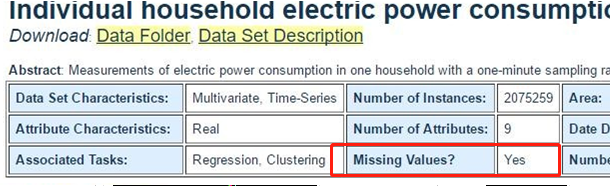
通过上图会知道有缺失的数据。
# 异常数据处理(异常数据过滤)
new_df = df.replace('?', np.nan) # 替换非法字符为np.nan
datas = new_df.dropna(axis=0, how = 'any') # 只要有一个数据为空,就进行行删除操作
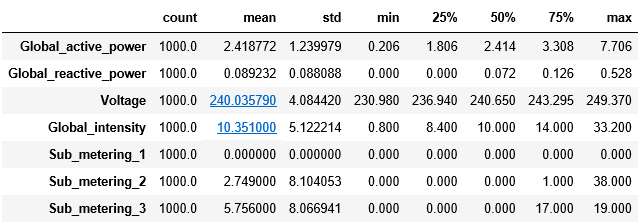
datas.describe().T # 观察数据的多种统计指标(只能看数值型的)
## 创建一个时间函数格式化字符串
def date_format(dt):
# dt显示是一个series/tuple;dt[0]是date,dt[1]是time
# import time
t = time.strptime(' '.join(dt), '%d/%m/%Y %H:%M:%S')
return (t.tm_year, t.tm_mon, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec)
## 需求:构建时间和功率之间的映射关系,可以认为:特征属性为时间;目标属性为功率值。
# 获取x和y变量, 并将时间转换为数值型连续变量
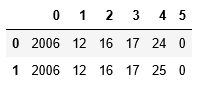
X = datas.iloc[:,0:2]
X = X.apply(lambda x: pd.Series(date_format(x)), axis=1)
Y = datas['Global_active_power']
X.head(2)
## 对数据集进行测试集合训练集划分
# X:特征矩阵(类型一般是DataFrame)
# Y:特征对应的Label标签(类型一般是Series)
# test_size: 对X/Y进行划分的时候,测试集合的数据占比, 是一个(0,1)之间的float类型的值
# random_state: 数据分割是基于随机器进行分割的,该参数给定随机数种子;给一个值(int类型)的作用就是保证每次分割所产生的数数据集是完全相同的
X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)

# 查看训练集上的数据信息(X)
X_train.describe()
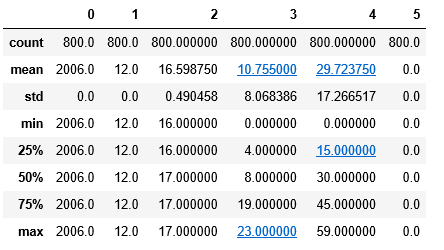
## 数据标准化
# StandardScaler:将数据转换为标准差为1的数据集(有一个数据的映射)
# scikit-learn中:如果一个API名字有fit,那么就有模型训练的含义,没法返回值
# scikit-learn中:如果一个API名字中有transform, 那么就表示对数据具有转换的含义操作
# scikit-learn中:如果一个API名字中有predict,那么就表示进行数据预测,会有一个预测结果输出
# scikit-learn中:如果一个API名字中既有fit又有transform的情况下,那就是两者的结合(先做fit,再做transform)
ss = StandardScaler() # 模型对象创建
X_train = ss.fit_transform(X_train) # 训练模型并转换训练集
X_test = ss.transform(X_test) ## 直接使用在模型构建数据上进行一个数据标准化操作 (测试集)
pd.DataFrame(X_train).describe()
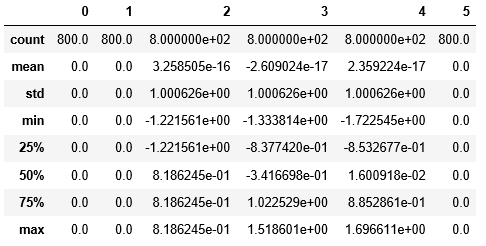
## 模型训练
lr = LinearRegression(fit_intercept=True) # 模型对象构建
'''
LinearRegression(fit_intercept=True, normalize=False,copy_X=True,n_jobs=1)
fit_intercept:是否需要截距
normalize:是否做标准化,上面已在单拿出来做了标准化
copy_X:是否进行数据复制,如果复制了,对数据进行修改,就不会改变原数据
n_jobs:并行运行。但需要CPU至少双核,基本不怎么用
'''
lr.fit(X_train, Y_train) ## 训练模型
## 模型校验
y_predict = lr.predict(X_test) ## 预测结果
print("训练集上R2:",lr.score(X_train, Y_train))
print("测试集上R2:",lr.score(X_test, Y_test))
mse = np.average((y_predict-Y_test)**2)
rmse = np.sqrt(mse)
print("rmse:",rmse)

这里的R²可以当成准确率,后续的文章中会有详细介绍。
# 输出模型训练得到的相关参数
print("模型的系数(θ):", end="")
print(lr.coef_)
print("模型的截距:", end='')
print(lr.intercept_)
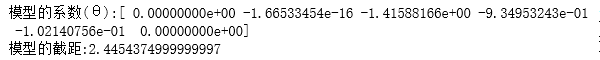
θ中的第1,2,6个为0,说明这一维度的数据对于模型而言不起作用。观察上面X_train.describe()输出的数据,发现这几维度的数据的方差都为0,说明这几个维度的数据是一样的,肯定对模型而言,起不了作用。
## 模型保存/持久化
# 在机器学习部署的时候,实际上其中一种方式就是将模型进行输出;另外一种方式就是直接将预测结果输出
# 模型输出一般是将模型输出到磁盘文件
from sklearn.externals import joblib
# 保存模型要求给定的文件所在的文件夹比较存在
joblib.dump(ss, "result/data_ss.model") ## 将标准化模型保存
joblib.dump(lr, "result/data_lr.model") ## 将模型保存
# 加载模型
ss3 = joblib.load("result/data_ss.model") ## 加载模型
lr3 = joblib.load("result/data_lr.model") ## 加载模型
# 使用加载的模型进行预测
data1 = [[2006, 12, 17, 12, 25, 0]]
data1 = ss.transform(data1)
print(data1)
lr.predict(data1)

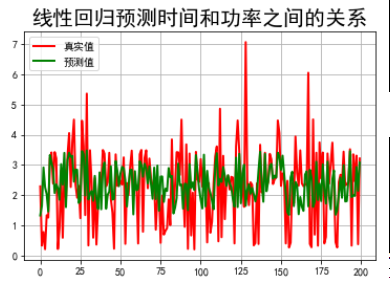
## 预测值和实际值画图比较
t=np.arange(len(X_test))
plt.figure(facecolor='w')#建一个画布,facecolor是背景色
plt.plot(t, Y_test, 'r-', linewidth=2, label='真实值')
plt.plot(t, y_predict, 'g-', linewidth=2, label='预测值')
plt.legend(loc = 'upper left')#显示图例,设置图例的位置
plt.title("线性回归预测时间和功率之间的关系", fontsize=20)
plt.grid(b=True)#加网格
plt.show()
## 功率和电流之间的关系
X = datas.iloc[:,2:4]
Y2 = datas.iloc[:,5]
## 数据分割
X2_train,X2_test,Y2_train,Y2_test = train_test_split(X, Y2, test_size=0.2, random_state=0)
## 数据归一化
scaler2 = StandardScaler()
X2_train = scaler2.fit_transform(X2_train) # 训练并转换
X2_test = scaler2.transform(X2_test) ## 直接使用在模型构建数据上进行一个数据标准化操作
## 模型训练
lr2 = LinearRegression()
lr2.fit(X2_train, Y2_train) ## 训练模型
## 结果预测
Y2_predict = lr2.predict(X2_test)
## 模型评估
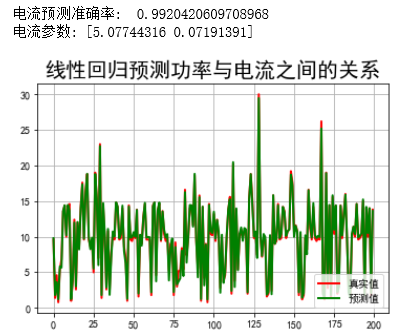
print("电流预测准确率: ", lr2.score(X2_test,Y2_test))
print("电流参数:", lr2.coef_)
## 绘制图表
#### 电流关系
t=np.arange(len(X2_test))
plt.figure(facecolor='w')
plt.plot(t, Y2_test, 'r-', linewidth=2, label=u'真实值')
plt.plot(t, Y2_predict, 'g-', linewidth=2, label=u'预测值')
plt.legend(loc = 'lower right')
plt.title(u"线性回归预测功率与电流之间的关系", fontsize=20)
plt.grid(b=True)
plt.show()
【总结】
发现使用scikitlearn做机器学习特别简单:
- 首先考虑做什么事,如我要做时间和功率之间的映射关系
- 然后找相关的数据:时间是什么、功率是什么
- 找到数据,把数据分成两块:训练集、测试集
- 对数据进行一些操作:格式化、异常值处理、标准化
- 接下来做模型的训练
就一个模型来讲,流程就是这些。
二、自己实现
对于最小二乘法已经了解了,代码实现的过程也知道。我们完全可以自己通过代码实现最小二乘法,来进行预测。
# 引入所需要的全部包
from sklearn.model_selection import train_test_split # 数据划分的类
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
import time
## 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
# 加载数据
# 日期、时间、有功功率、无功功率、电压、电流、厨房用电功率、洗衣服用电功率、热水器用电功率
path1='datas/household_power_consumption_1000.txt'
df = pd.read_csv(path1, sep=';', low_memory=False)#没有混合类型的时候可以通过low_memory=F调用更多内存,加快效率)
df.head(2)

## 功率和电流之间的关系
X = df.iloc[:,2:4]
Y2 = df.iloc[:,5]
## 数据分割
X2_train,X2_test,Y2_train,Y2_test = train_test_split(X, Y2, test_size=0.2, random_state=0)
type(X2_train)
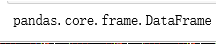
发现不是矩阵,必须转换成矩阵才能进行最小二乘公式计算。
# 将X和Y转换为矩阵的形式
X = np.mat(X2_train)
Y = np.mat(Y2_train).reshape(-1,1)
type(X)

此时发现,已经转成矩阵。
# 计算θ
theta = (X.T * X).I * X.T * Y
print(theta)
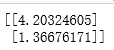
用到的就是我们上篇博客中最小二乘法得到的解析式:
# 对测试集合进行测试
y_hat = np.mat(X2_test) * theta
# 画图看看
#### 电流关系
t=np.arange(len(X2_test))
plt.figure(facecolor='w')
plt.plot(t, Y2_test, 'r-', linewidth=2, label=u'真实值')
plt.plot(t, y_hat, 'g-', linewidth=2, label=u'预测值')
plt.legend(loc = 'lower right')
plt.title(u"线性回归预测功率与电流之间的关系", fontsize=20)
plt.grid(b=True)
plt.show()
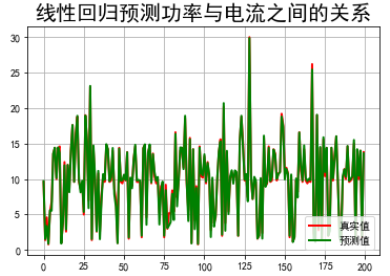
运行代码,发现运行效果跟scikitlearn的运行效果差不多。
最后,再总结一下: 其实很简单,除去画图的代码,主要部分就剩下数据处理和训练那几行代码。好了,掌声,起!

