机器学习第1天
欢迎转载,请标明出处(http://blog.csdn.net/tonyshengtan),尊重劳动,尊重知识,欢迎讨论。
开篇废话
话说在高中数学统计的部分就有学过最小二乘法,现在想想,当时没有严格的推倒和实用背景,单纯的给了公式然后做应用题,不过也印证了乔布斯的一句话,不管你现在在做什么,你都无法预料到这对你以后是否有影响,你只能看到过去,无法看到未来。
最小二乘法(Least squares)
为什么叫最小二乘法,首先最小明确的告诉你,俺们求出来的是全局的最值,不是极值,就是最小的一个位置,二乘(square)是平方的意思,Ok,也就是说最小二乘法的理论是找到最小的平方值,什么的最小平方值?慢慢看下面。
参考书《机器学习基础教程》中的例子,以历届奥运会男子100米的夺冠时间为数据:
| No. | Year | time |
|---|---|---|
| 1 | 1896 | 12.0 |
| 2 | 1900 | 11.0 |
| 3 | 1904 | 11.0 |
| 4 | 1908 | 10.8 |
| 5 | 1912 | 10.8 |
| 6 | 1920 | 10.8 |
| 7 | 1924 | 10.6 |
| 8 | 1928 | 10.8 |
| 9 | 1932 | 10.3 |
| 10 | 1936 | 10.3 |
| 11 | 1948 | 10.3 |
| 12 | 1952 | 10.4 |
| 13 | 1956 | 10.5 |
| 14 | 1960 | 10.2 |
| 15 | 1964 | 10.0 |
| 16 | 1968 | 9.95 |
| 17 | 1972 | 10.14 |
| 18 | 1976 | 10.06 |
| 19 | 1980 | 10.25 |
| 20 | 1984 | 9.99 |
| 21 | 1988 | 9.92 |
| 22 | 1992 | 9.96 |
| 23 | 1996 | 9.84 |
| 24 | 2000 | 9.87 |
| 25 | 2004 | 9.85 |
| 26 | 2008 | 9.69 |
| 27 | 2012 | 9.63 |
注释:中间有三年数据缺失,原因是第一和第二次世界大战(闲的没事回家搞科研造福人类多好,打毛的仗)。
使用matlab显示下数据:
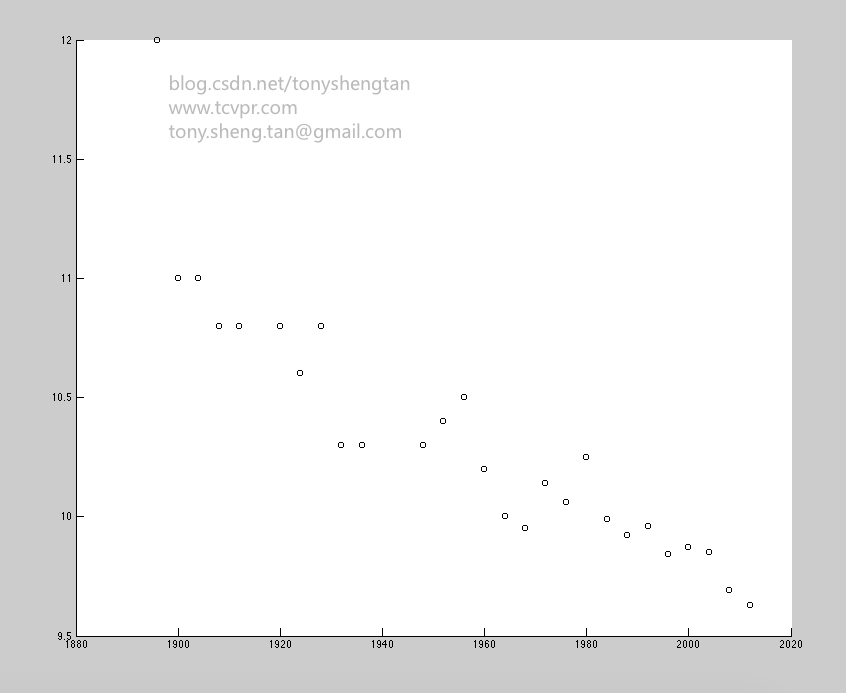
生成上图代码:
data=[1896 12.0;1900 11.0;1904 11.0;1908 10.8;1912 10.8;1920 10.8;1924 10.6;1928 10.8;1932 10.3;1936 10.3;1948 10.3;1952 10.4;1956 10.5;1960 10.2;1964 10.0;1968 9.95;1972 10.14;1976 10.06;1980 10.25;1984 9.99;1988 9.92;1992 9.96;1996 9.84;2000 9.87;2004 9.85;2008 9.69;2012 9.63];
x=data(:,1);
t=data(:,2);
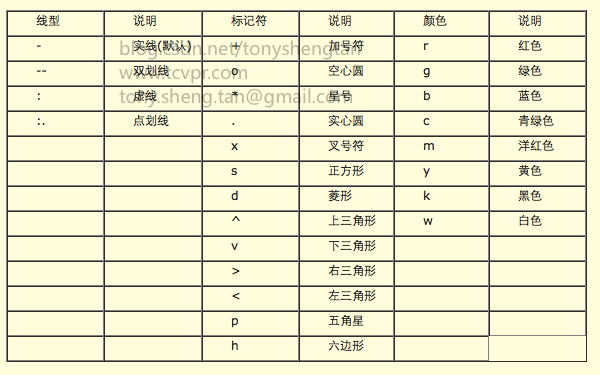
scatter(x,t,'k');其中第三个参数可以由下表中查出:
很明显的下降趋势,不太明显的线性关系,不过我们还是用线性来拟合这组数据,看看会有什么效果。
设直线为:
来解释下这个模型,我们的目的是让整条直线尽可能的和途中点数据相接近,而并不是要让一条直线穿过尽可能多的点,换句话说我们要追求一个全局的最优。
如何来衡量这个直线和各点之间的接近程度呢?这里给出一个平方损失函数,请注意,这并不是唯一的办法,不过是一种简单的方法,比如绝对值也能完成此类任务,但绝对值计算过于复杂,四次六次八次函数也能完成,很明显计算量也过大,所以我们的损失函数定义为:
其中:

这样就给出了“二乘的部分”,求最小二乘的目的是得出全局最优解参数
求最小值,一般的方法是求一阶导数,对于上式,我们认为自变量是
这样,求导前简化掉没用项:
当对
整理求导后得到:
同理对
根据一阶导数为0时有可能为最值点(有可能是极值或者驻点,进一步判断需要求二阶偏导数得出,但对于平方形函数,一阶导数为零可以确定为最值)
这样就能求出:
w0^=t¯−w1x¯ w1^=xt¯−x¯t¯x2¯−(x¯2)
用一下代码对最上面图进行最小二乘拟合得到:
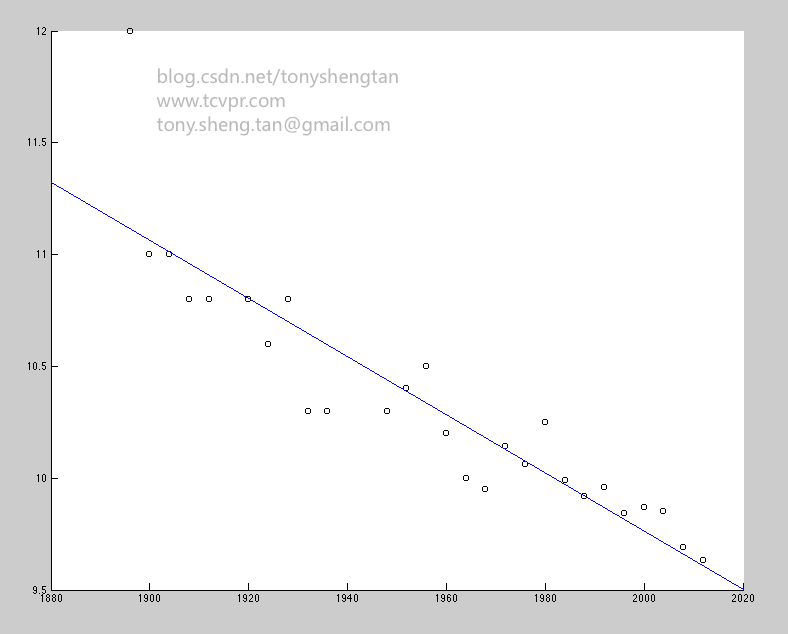
Matlab Code:
data=[1896 12.0;1900 11.0;1904 11.0;1908 10.8;1912 10.8;1920 10.8;1924 10.6;1928 10.8;1932 10.3;1936 10.3;1948 10.3;1952 10.4;1956 10.5;1960 10.2;1964 10.0;1968 9.95;1972 10.14;1976 10.06;1980 10.25;1984 9.99;1988 9.92;1992 9.96;1996 9.84;2000 9.87;2004 9.85;2008 9.69;2012 9.63];
[m,n]=size(data);%m行,n列
x=data(:,1);
t=data(:,2);
scatter(x,t,'k');
xt=0;
x_=mean(x);
t_=mean(t);
x_2=0;
for i=1:m
xt=xt+x(i)*t(i);
x_2=x_2+x(i)^2;
end
xt_mean=xt/m;
x_2_mean=x_2/m;
w1=(xt_mean-x_*t_)/((x_2_mean)-x_^2);
w0=t_-w1*x_;
x=data(:,1);
t=data(:,2);
scatter(x,t,'k');
[m,n]=size(data);%m行,n列
xt=0;
x_=mean(x);
t_=mean(t);
x_2=0;
for i=1:m
xt=xt+x(i)*t(i);
x_2=x_2+x(i)^2;
end
xt_mean=xt/m;
x_2_mean=x_2/m;
w1=(xt_mean-x_*t_)/((x_2_mean)-x_^2);
w0=t_-w1*x_;
%%使用矩阵解决
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for i=1:m
X(i,1)=1;
X(i,2)=x(i);
end
w=(X'*X)^(-1)*X'*t;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
refline(w1,w0);%w1斜率,w0截距
refline(w1,w0);%w1斜率,w0截距以上针对二维数据,对于超过二维的数据的线性回归我们使用矩阵来做等效处理。
对于超过二维的数据,损失函数定义如下:
此处推导过程,与上二维数据推导过程类似,但使用矩阵为工具,故省略:
总结
至此,最小二乘法的基本过程已经介绍完了,基础算法可能数学推导过多,但对后面的高级算法理解还是很有用的。
待续。。。。