要想理解ElasticNet回归,正则化是必须要首先知道的,其次是岭回归和Lasso回归,知道了这些,弹性网回归自然也就明白了。
所以我们从一个最小二乘做线性回归问题开始,逐渐推导出ElasticNet回归
一个问题:
我们都知道利用最小二乘法来做线性回归,即让损失函数达到最小值,可得到的最优的拟合参数(即θ )。
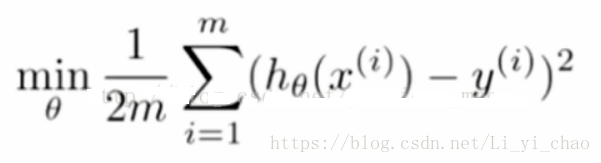
但是如果我们用来拟合的特征变量过多,而且特征变量之前存在很高的相关关系,比如下面这种情况:

正则化
以上两个函数都可以很好的拟合数据,但右边的函数显然有过拟合的嫌疑,为了避免这种情况,有两种方法:
1、特征选择,舍掉x^3和x^4这两个变量(可以人工选择,也可以利用算法来做。但有些时候我们可能并不希望舍弃数据,一方面特征选择有一定的不确定性,另一方面这个过程是比较繁琐的,这种时候我们可以采用第二种方法来解决这一问题。);

2、正则化,减小θ3和θ4的值(保留所有特征变量,但减少变量参数的值)。要减小θ3和θ4的值,我们可以在损失函数的后面加上(1000*θ3^2+1000*θ4^2):
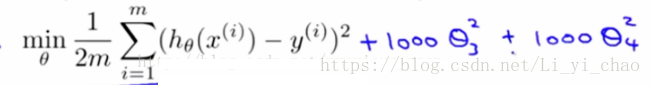
如此一来在最小化目标函数时,因为θ3和θ4前面乘了1000这样大的数字,导致θ3和θ4的值会非常的小,目标达成。
岭回归和Lasso回归:
上面我们有选择的让θ3和θ4的值变小,实际情况中,我们很难判断哪些特征变量需要正则化,所以一般情况下,我们是对所有的参数都正则化处理:
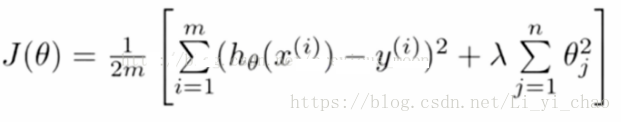
即目标函数设为J(θ),其中新增部分是正则项,lambda为正则参数。需要注意的是,j是从1开始的,这意味着函数的常数项(θ0)并没有被正则化。所以lambda不能设的太大,否则会导致除了常数项外,所有的参数值都很小,因变量近似等于常数项,出现欠拟合现象。
好了,说到这里我要告诉你,上面的目标函数就是岭回归的目标函数。
Lasso回归呢? 其实和岭回归的区别只在于惩罚项的不同,Lasso回归的惩罚项用的是绝对值(也称为L1正则化),而岭回归中惩罚项用的是平方(L2正则化)。通俗地说,Lasso回归就是一个回归,并且回归系数不要太大,防止过拟合。
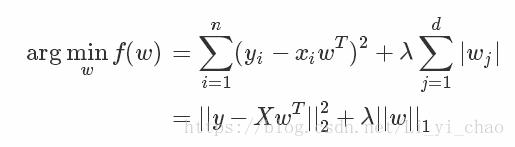
L1正则与L2正则的区别:
这时你可能就要思考了,L1正则、L2正则有什么区别呢?
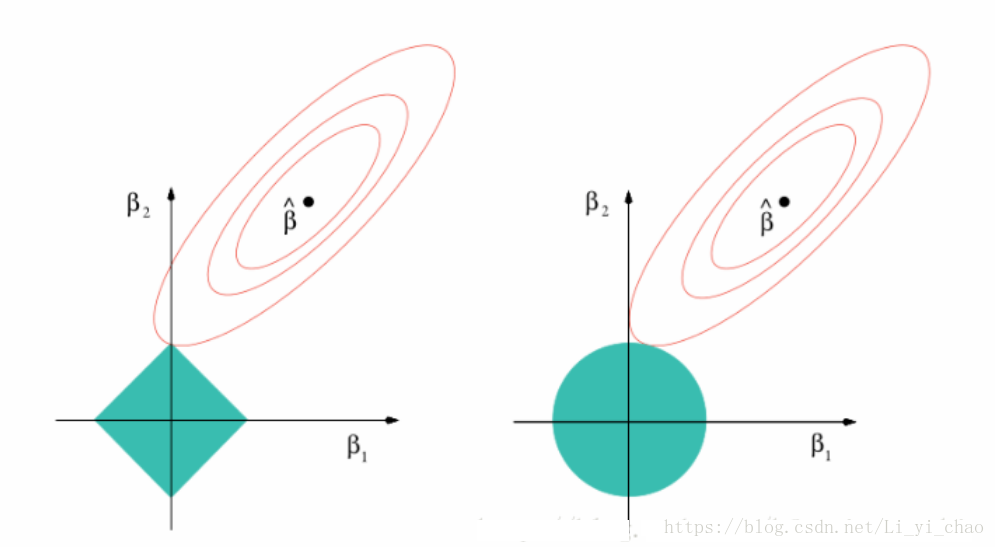
L1正则化是指权值向量w中各个元素的绝对值之和,对应下图的蓝色方块
L2正则化是指权值向量w中各个元素的平方和然后再求平方根,对应下图的蓝色圆
图中的红色线圈表示,损失函数的等值线,要使损失函数最小化,即为图中红色线与蓝色图形的交点。
L1的妙处就在这个地方,在第一范数的约束下,一部分回归系数刚好可以被约束为0.这样的话,就达到了特征选择的效果。
L2的妙处,在第二范数的约束下,使得回归系数尽可能取较小的值,从而防止一开始问题中的过拟合。
ElasticNet回归
说到这里,其实你已经知道ElasticNet回归了,其实就是岭回归和Lasso回归的组合
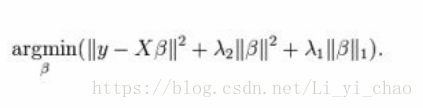
Python实现ElasticNet回归,有sklearn.linear_model.ElasticNetCV和sklearn.linear_model.ElasticNet两个函数可供选择,前者可以通过迭代选择最佳的lambda1和lambda2(当然你可以指定一组值),后者需要你指定lambda1和lambda2的值。
因为目标函数的形式是:
1 / (2 * n_samples) * ||y - Xw||^2_2+ alpha * l1_ratio * ||w||_1+ 0.5 * alpha * (1 - l1_ratio) * ||w||^2_2
所以lambda1和lambda2的指定是通过l1_ratio和alpha来完成
