一个简单的Python爬虫示例,本文讲解该怎么爬取网页信息,分析页面结构,将信息存入MongoDB(如果没有MongoDB也可以存txt里,并不影响整体程序运行),对影评使用jieba分词来构成词云(解决中文生成词云是空方格)。
使用到的包
import requests
#连接失败的异常
from requests.exceptions import ConnectionError
#MongoDB的包
import pymongo
from pymongo.mongo_client import MongoClient
#MongoDB连接失败的异常
from pymongo.errors import PyMongoError
#使用BeautifulSoup来处理页面
from bs4 import BeautifulSoup
#使用结巴分词
import jieba
#wordcloud词云包,STOPWORDS是默认的弃用词
from wordcloud import WordCloud, STOPWORDS
#将词云的图绘出
import matplotlib.pyplot as plt
import numpy as np
#导入图片用的包
from PIL import Image
#多线程用的包
import threading
下载包用到的命令
jieba包下载,一开始我用的是conda install -c conda-forge jieba但后面发现conda里的jieba包是小于0.4的。
jieba的github网址
在jieba里我看到有一个paddle模式,感觉很厉害就用pip把jieba升级了。如果也想用paddle模式就按图里的命令即可

#jieba下载,后面那个部分是使用清华源下载
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddlepaddle-tiny==1.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
#wordcloud下载
pip install wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple
其他包都比较常见,就不写了
程序主要由爬取和生成词云两个部分组成
1.爬取豆瓣影评
1.1先访问豆瓣电影看看能不能请求成功
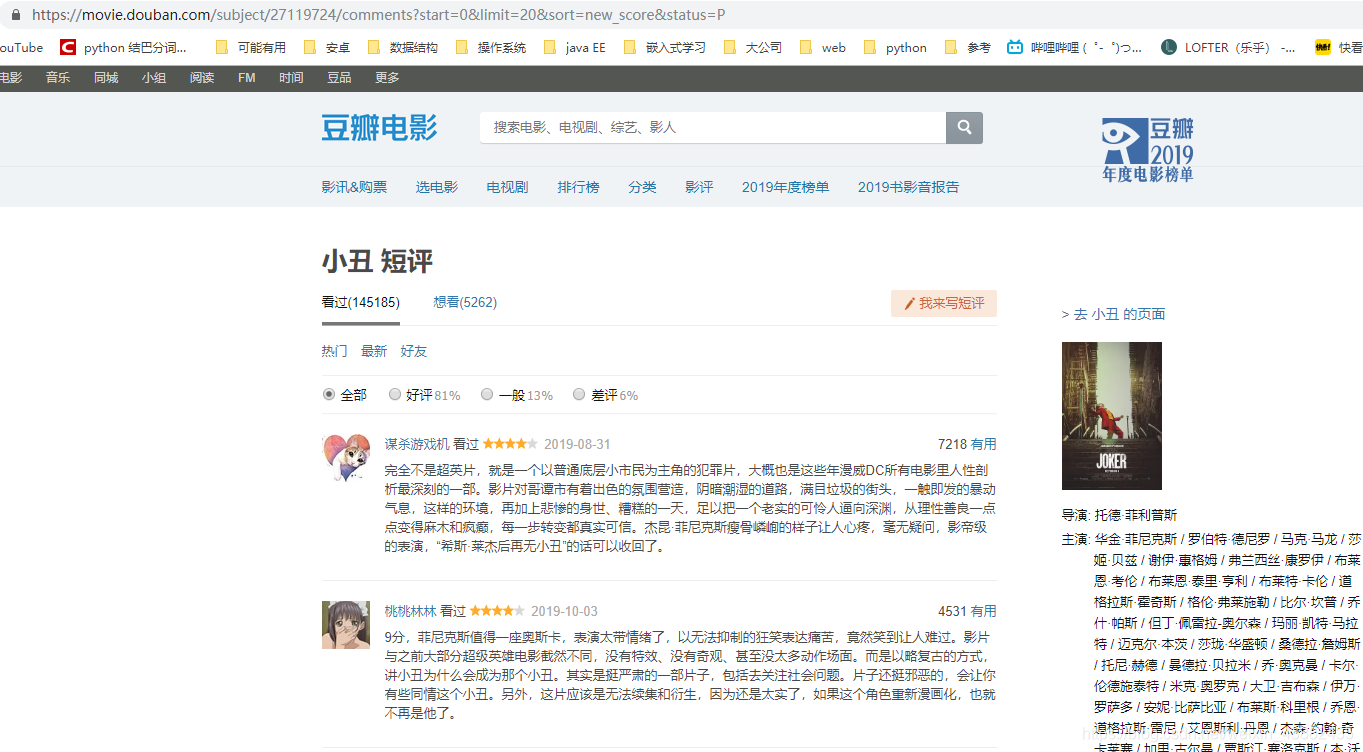
打算爬取的是豆瓣电影里的小丑影评
def scrape(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'
}
res = request.get(url, headers=headers)
print(res.text)
except ConnectionError:
print("爬取失败")
if __name__ == '__main__':
urls = [
'https://movie.douban.com/subject/27119724/comments?start=0&limit=20&sort=new_score&status=P',
]
for i in range(0, len(urls)):
scrape(urls[i])
createWordCloud()
print('结束')
运行了下页面由出来,大致的看了下的确是小丑的短评
1.2分析页面,思考要把什么信息拿出来

我们将在MongoDB里存入用户名,用户做出的评价,短评的内容
易知用户名,评论都在class=comment-info里span里面
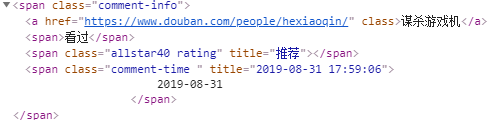
用户名是这个span里唯一的a标签,评论是class=rating里title代表的值
短评是class=short里的内容
1.3爬取相应的信息
# 连接MongoDb
def mongo():
try:
mongoClient = MongoClient('localhost', 27017)
# 连接叫local的库
mongoDatabase = mongoClient.local
# 连接叫douban_two的集合
collection = mongoDatabase.douban_two
# 返回集合
return collection
except PyMongoError as e:
print('出错', e)
# 爬取豆瓣短评
def scrape(url):
try:
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'
}
res = requests.get(url, headers=headers)
# 这个是想如果没请求成功就再请求5次
for i in range(0, 5):
if res.status_code is 403:
print('出现403')
res = request.get(url, headers=headers)
else:
break
print("爬取成功%s,收到%s" % (url, res.status_code))
# 使用BeautifulSoup
soup = BeautifulSoup(res.text, 'html.parser')
# 包含用户名和评价的列表,通过class查出
username_list = soup.find_all('span', attrs={'class': 'comment-info'})
# 短评的列表,通过class=short找出
content_list = soup.find_all('span', attrs={'class': 'short'})
# 因为两个列表的长度是对应的所以用长度来循环
for indexOf in range(0, len(username_list)):
# 找出评论
rate = username_list[indexOf].find('span', attrs='rating')
# 调用连接MongoDB的方法获取集合
collection = mongo()
title = ''
# 说出来你可能不信,在start=220那页有个人没打分,在此处进行判空
if rate is not None:
#通过get()来获取title里的值
title = rate.get('title')
# 调用insert_one添加记录,username_list[indexOf].a.string,这个的意思就是在这个位置取a标签里的文本
collection.insert_one(
{'context': content_list[indexOf].string, 'username': username_list[indexOf].a.string, 'rate': title})
except ConnectionError:
print("爬取失败")
if __name__ == '__main__':
urls = [
'https://movie.douban.com/subject/27119724/comments?start=20&limit=20&sort=new_score&status=P',
'https://movie.douban.com/subject/27119724/comments?start=40&limit=20&sort=new_score&status=P',
'https://movie.douban.com/subject/27119724/comments?start=60&limit=20&sort=new_score&status=P',
# 先注解掉下面这个,这个需要登录才能看,最后的完整代码里会展示以登录的状态爬取短评
#'https://movie.douban.com/subject/27119724/comments?start=220&limit=20&sort=new_score&status=P'
]
for i in range(0, len(urls)):
scrape(urls[i])
print('结束')
运行结果:

我用的可视化工具是MongoDB Compass,这个工具对于文本很长的是不能全部展开的,除了这点用起来还行。
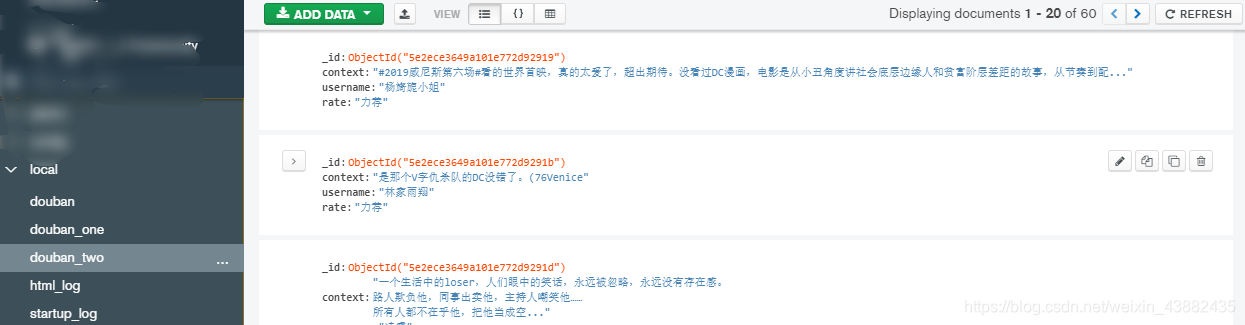
到此已经爬取到了豆瓣的影评并存入了MongoDB里
2.根据影评生成词云
过程:对影评切分,根据切分后的文本生成词云
代码:此处代码为了简单展示只拿一条短评来生成词云,后面完整的代码是80个短评一起
# 这个请加在包引用的后面,这个用于开启paddle模式
jieba.enable_paddle()
# 分词
def getCutWord():
# 获取集合
collection = mongo()
# 通过[0]来只取出第一条数据
douban = collection.find()[0]
# word_total = ''
# 获取短评
context = douban['context']
list_paddle = jieba.cut(context, use_paddle=True)
# 通过join()通过空格来连接list_paddle来生成一段文本
word = " ".join(list_paddle)
return word
# 生成词云
def createWordCloud():
# 调用分词方法
text = getCutWord()
print(text)
# mask = np.array(Image.open('img5.jpg'))
# 下面这两行是将这些,电影加入屏蔽词中让词云不分析它们
word = {'这些', '电影'}
stopwords = STOPWORDS.update(word)
# 背景白,font_path字体要加
# 这里是个坑,因为wordcloud是针对字母的,如果是中文的话是识别不了的,需要设置字体
wordcloud = WordCloud(background_color='white', font_path="msyh.ttc", stopwords=stopwords, max_words=300)
# 如果你要设置背景的话使用这个添加mask
# wordcloud = WordCloud(background_color='white', font_path="msyh.ttc",mask=mask, stopwords=stopwords, max_words=300)
# 以text生成词云
wordcloud.generate(text=text)
# 显示词云
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# 保存词云为图片
wordcloud.to_file('cloud_one.png')
if __name__ == '__main__':
createWordCloud()
print('结束')
运行生成的图片:

关于上面的代码,最需要注意的是中文字体设置font_path这个地方
如果你不设置,结果将是:

显示中文字体该如何设置:
打开C:\Windows\Fonts在搜索框里搜 微软雅黑

搜出这个后将其复制到项目中,我这个一粘贴就直接三个文件不知道你们的和我一不一样。
到此Python爬取豆瓣影评和生成词云都已结束。
全代码一份
关于登录这块学习了Python登录豆瓣并爬取影评
需要注意的地方: s = requests.Session(),还有登录的地方账号密码改成自己的
import requests
from requests.exceptions import ConnectionError
import pymongo
from pymongo.mongo_client import MongoClient
from pymongo.errors import PyMongoError
from bs4 import BeautifulSoup
import jieba
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import threading
jieba.enable_paddle()
# 生成Session对象用来保存Cookie
s = requests.Session()
# 连接MongoDb
def mongo():
try:
mongoClient = MongoClient('localhost', 27017)
# 连接叫local的库
mongoDatabase = mongoClient.local
# 连接叫douban_two的集合
collection = mongoDatabase.douban_two
# 返回集合
return collection
except PyMongoError as e:
print('出错', e)
# 分词
def getCutWord():
# 获取集合
collection = mongo()
# 全数据
douban = collection.find()
word_total = ''
#进行遍历
for row in douban:
context = row['context']
list_paddle = jieba.cut(context, use_paddle=True)
word = " ".join(list_paddle)
# 将80个短评加入word_total里
word_total = word_total + ' ' + word
return word_total
# 生成词云
def createWordCloud():
# 调用分词方法
text = getCutWord()
print(text)
#以这张图片为背景来生成词云
mask = np.array(Image.open('img5.jpg'))
# 下面这两行是将这些,电影加入屏蔽词中让词云不分析它们
word = {'这些', '电影'}
stopwords = STOPWORDS.update(word)
# 背景白,font_path字体要加
# 这里是个坑,因为wordcloud是针对字母的,如果是中文的话是识别不了的,需要设置字体
# wordcloud = WordCloud(background_color='white', font_path="msyh.ttc", stopwords=stopwords, max_words=300)
# 如果你要设置背景的话使用这个添加mask
wordcloud = WordCloud(background_color='white', font_path="msyh.ttc",mask=mask, stopwords=stopwords, max_words=300)
# 以text生成词云
wordcloud.generate(text=text)
# 显示词云
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# 保存词云为图片
wordcloud.to_file('cloud_one.png')
# 发送登录请求
def Login():
url = 'https://accounts.douban.com/j/mobile/login/basic'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'
}
# 请输入自己登录豆瓣的用户名和密码
data = {
'name': '******',
'password': '*****',
'remember': 'false'
}
try:
re = s.post(url, headers=headers, data=data)
print(re.status_code)
except:
print('失败')
# 爬取豆瓣短评
def scrape(url):
try:
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'
}
res = s.get(url, headers=headers)
# 这个是想如果没请求成功就再请求5次
for i in range(0, 5):
if res.status_code is 403:
print('出现403')
res = s.get(url, headers=headers)
else:
break
print("爬取成功%s,收到%s" % (url, res.status_code))
# 使用BeautifulSoup
soup = BeautifulSoup(res.text, 'html.parser')
# 包含用户名和评价的列表,通过class查出
username_list = soup.find_all('span', attrs={'class': 'comment-info'})
# 短评的列表,通过class=short找出
content_list = soup.find_all('span', attrs={'class': 'short'})
# 因为两个列表的长度是对应的所以用长度来循环
for indexOf in range(0, len(username_list)):
# 找出评论
rate = username_list[indexOf].find('span', attrs='rating')
# 调用连接MongoDB的方法获取集合
collection = mongo()
title = ''
# 说出来你可能不信,在start=220那页有个人没打分,在此处进行判空
if rate is not None:
title = rate.get('title')
# 调用insert_one添加记录,username_list[indexOf].a.string,这个的意思就是在这个位置取a标签里的文本
collection.insert_one(
{'context': content_list[indexOf].string, 'username': username_list[indexOf].a.string, 'rate': title})
except ConnectionError:
print("爬取失败")
# 使用线程
class MyThread(threading.Thread):
def __init__(self, target, args):
threading.Thread.__init__(self)
self.target = target
self.args = args
def run(self):
self.target(self.args)
if __name__ == '__main__':
# 进行登录
Login()
urls = [
'https://movie.douban.com/subject/27119724/comments?start=20&limit=20&sort=new_score&status=P',
'https://movie.douban.com/subject/27119724/comments?start=40&limit=20&sort=new_score&status=P',
'https://movie.douban.com/subject/27119724/comments?start=60&limit=20&sort=new_score&status=P',
'https://movie.douban.com/subject/27119724/comments?start=220&limit=20&sort=new_score&status=P'
]
# for i in range(0, len(urls)):
# scrape(urls[i])
# 通过多线程来并发爬取
thread_list = []
for i in range(0, len(urls)):
thread = MyThread(target=scrape, args=urls[i])
thread_list.append(thread)
for i in range(0, len(urls)):
thread_list[i].start()
for i in range(0, len(urls)):
thread_list[i].join()
createWordCloud()
print('结束')
怎么登录分析这条就可以得出
运行结果:

