Python版本: python3.+
运行环境: Mac OS
IDE: pycharm
一 前言
之前捣鼓了几日wordcloud词云,觉得很有意思,能自定义背景图、设置各式各样的字体、还能设置词的颜色。生成词云的时候也很有成就感。(233333)但是哪来的数据源呢?于是就想到了豆瓣网的影评。
顺带(装模作样地)尝试了一下自顶向下的设计原则:
- 爬取豆瓣网指定电影的5000条影评;
- 存到数据库中;
- 从数据库中获取并处理评论,获得词频;
- 利用词频生成图云。
大(我)道(不)至(会)简(写),下面就按这个原则一步一步来。
不过在施工之前,要先准备好工具:
- mongodb的安装:这个安装攻略网上有很多,在这里推荐菜鸟教程的, MAC OS/Linux/Windows的教程都有
- jieba分词库的导入及简单使用:Github地址
- wordcloud库的导入及简单使用:Github地址
二 豆瓣网影评爬取
1 网页分析
我们以春宵苦短,少女前进吧! 夜は短し歩けよ乙女 这部电影为例。
URL:https://movie.douban.com/subject/26935251/
在这个页往下拉拉到分评论,点击更多短评,跳转到评论页。
能发现URL的变化:
https://movie.douban.com/subject/26935251/comments?sort=new_score&status=P
其核心部分就是https://movie.douban.com/subject/26935251/comments,后面的?sort=new_score&status=P说明该网页以GET方式发送参数
Chrome浏览器下,通过工具栏进入开发者工具(快捷键:command+alt+i)
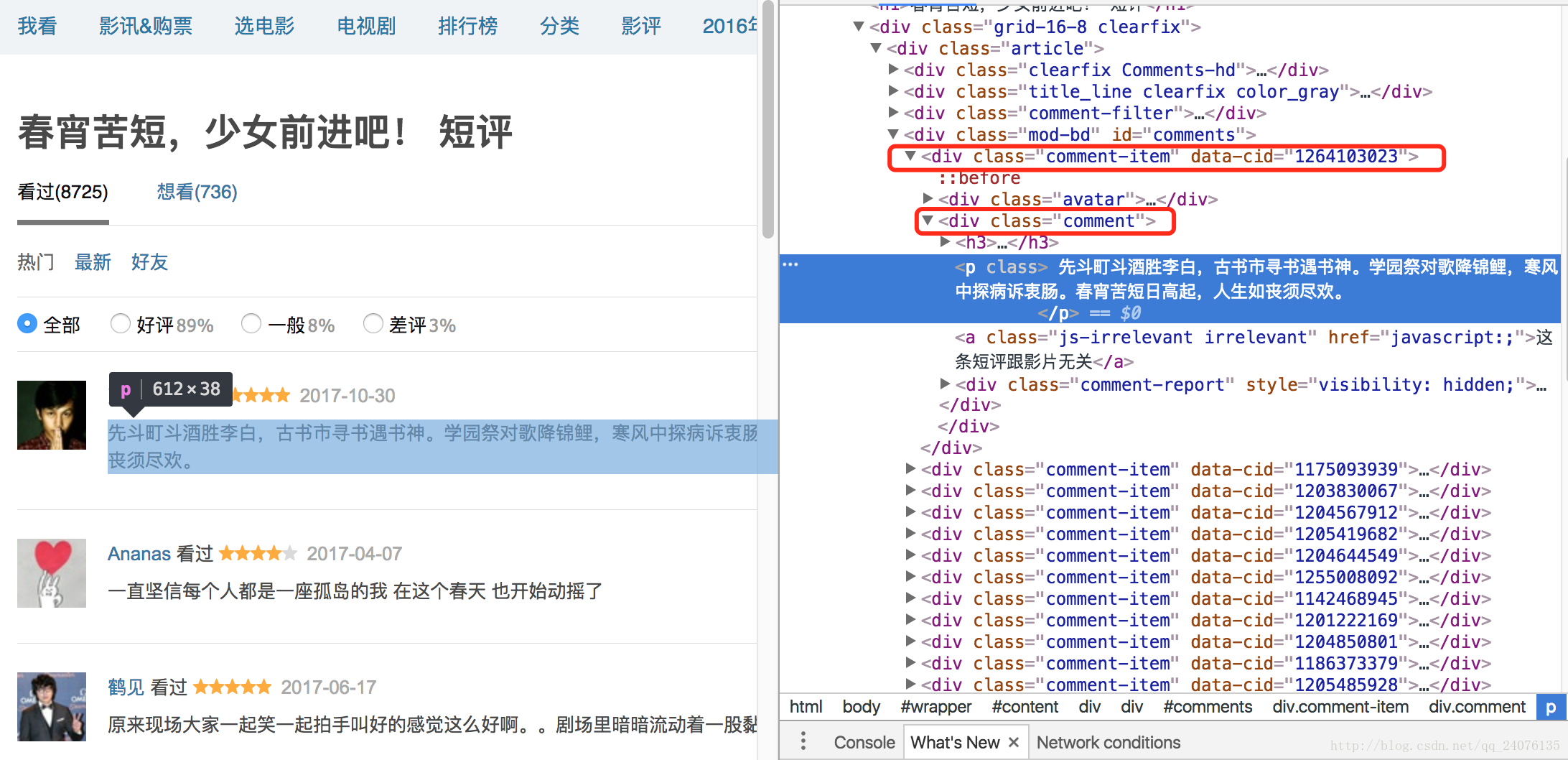
能发现评论的信息全在一个个的//div[@class="comment-item"]中间。
再拉倒页面底部,点击后页,在NetWork中抓包分析
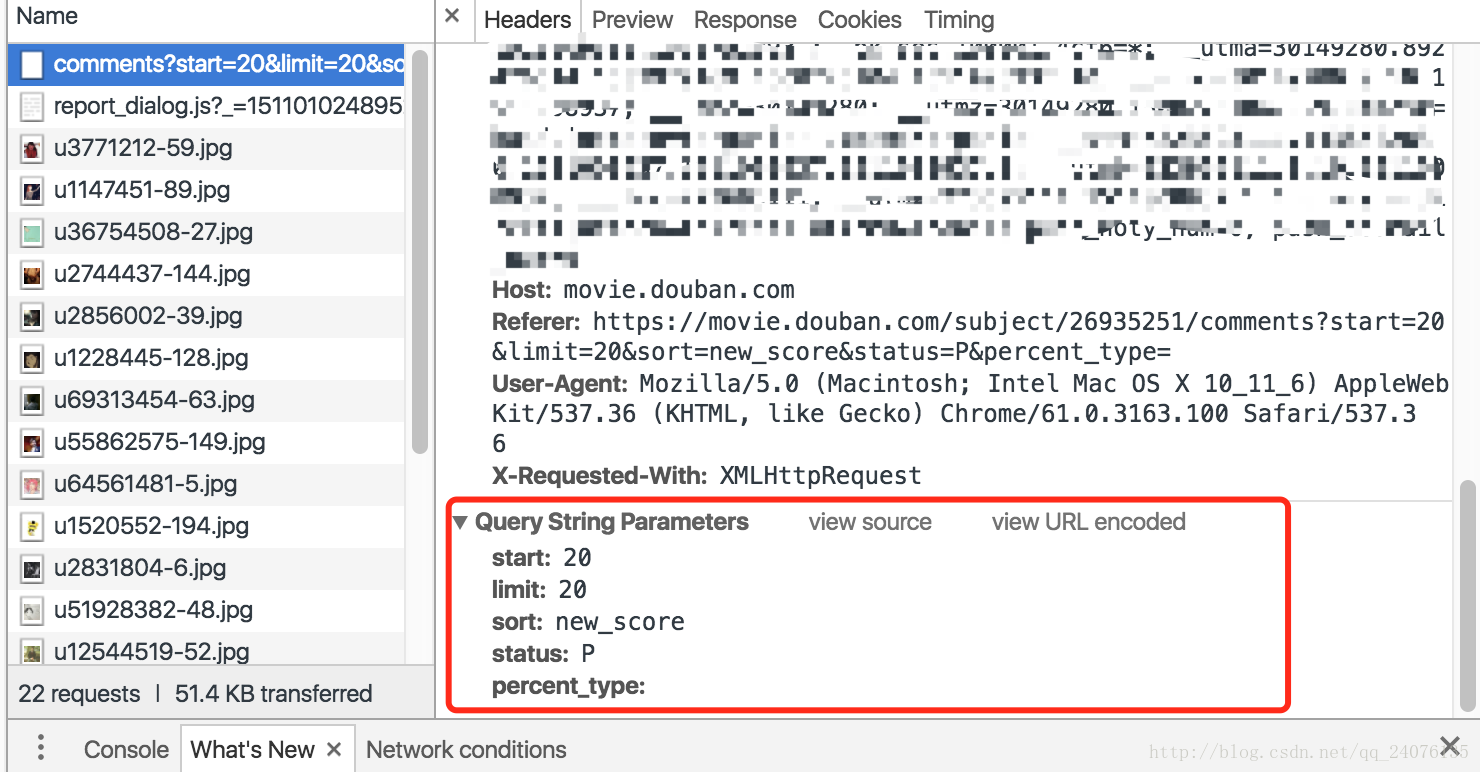
能观察到发送数据的内容。再结合页面信息,不难发现start就是从第start条评论开始,limit就是当前页显示limit条评论;那这样,我们就能直接在循环中,在每次发送的数据中,更新start=start+limit直至最后接收到的页面评论数不大于0。
2 代码编写
利用这一点,就能构造出我们想要的爬虫了,代码如下:
import requests
from lxml import etree
import time
def get_comments(url,headers,start,max_restart_num,movie_name,collection):
'''
:param url: 请求页面的url
:param headers: 请求头
:param start: 第start条数据开始
:param max_restart_num: 当获取失败时,最大重新请求次数
:param movie_name: 电影名字
:param collection: mongodb数据库的集合
:return:
'''
if start >= 5000:
print("已爬取5000条评论,结束爬取")
return
data = {
'start': start,
'limit': 20,
'sort': 'new_score',
'status': 'P',
}
response = requests.get(url=url, headers=headers, params=data)
tree = etree.HTML(response.text)
comment_item = tree.xpath('//div[@id ="comments"]/div[@class="comment-item"]')
len_comments = len(comment_item)
if len_comments > 0:
for i in range(1, len_comments + 1):
votes = tree.xpath('//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="votes"]'.format(i))
commenters = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="comment-info"]/a'.format(i))
ratings = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="comment-info"]/span[contains(@class,"rating")]/@title'.format(
i))
comments_time = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="comment-info"]/span[@class="comment-time "]'.format(
i))
comments = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]/div[@class="comment"]/p'.format(i))
vote = (votes[0].text.strip())
commenter = (commenters[0].text.strip())
try:
rating = (str(ratings[0]))
except:
rating = 'null'
comment_time = (comments_time[0].text.strip())
comment = (comments[0].text.strip())
comment_dict = {}
comment_dict['vote'] = vote
comment_dict['commenter'] = commenter
comment_dict['rating'] = rating
comment_dict['comments_time'] = comment_time
comment_dict['comments'] = comment
comment_dict['movie_name'] = movie_name
#存入数据库
print("正在存取第{}条数据".format(start+i))
print(comment_dict)
# collection.update({'commenter': comment_dict['commenter']}, {'$setOnInsert': comment_dict}, upsert=True)
headers['Referer'] = response.url
start += 20
data['start'] = start
time.sleep(5)
return get_comments(url, headers, start, max_restart_num,movie_name,collection)
else:
# print(response.status_code)
if max_restart_num>0 :
if response.status_code != 200:
print("fail to crawl ,waiting 10s to restart continuing crawl...")
time.sleep(10)
# headers['User-Agent'] = Headers.getUA()
# print(start)
return get_comments(url, headers, start, max_restart_num-1, movie_name, collection)
else:
print("finished crawling")
return
else:
print("max_restart_num has run out")
with open('log.txt',"a") as fp:
fp.write('\n{}--latest start:{}'.format(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), start))
return
if __name__ =='__main__':
base_url = 'https://movie.douban.com/subject/26935251'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Upgrade-Insecure-Requests': '1',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'Host':'movie.douban.com',
}
start = 0
response = requests.get(base_url,headers)
tree = etree.HTML(response.text)
movie_name = tree.xpath('//div[@id="content"]/h1/span')[0].text.strip()
# print(movie_name)
url = base_url+'/comments'
try:
get_comments(url, headers,start, 5, movie_name,None)
finally:
pass
执行这个程序就能在控制台输不断地输出获取到的评论信息了,但是才爬了200多条评论,就会出现以下信息:
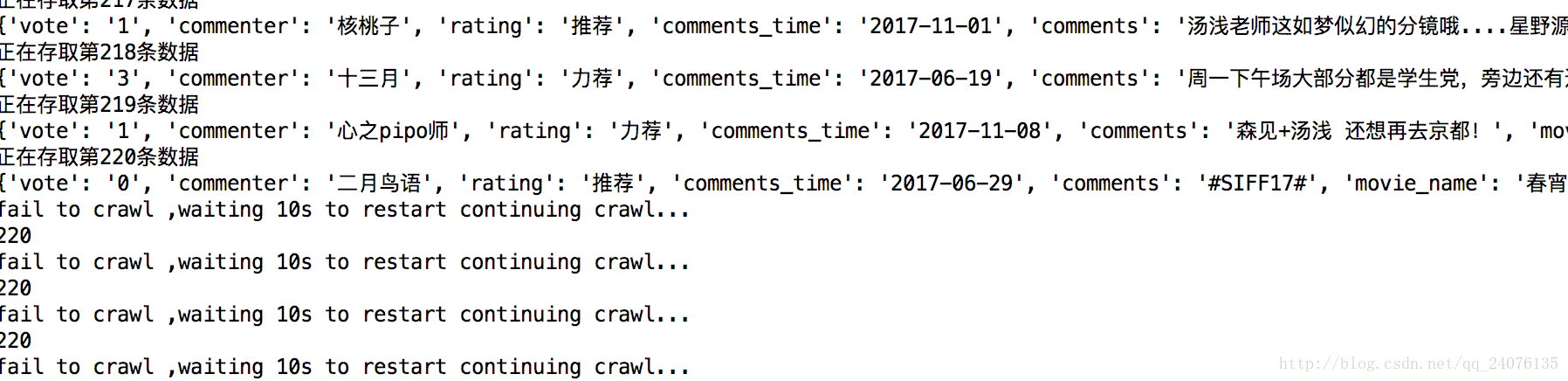
这是因为没有登录。这个问题有2种解决方法:
1. 用程序模拟登录豆瓣网并保存cookies。
2. 直接在网页上登录,再通过抓包,获得登录后的cookie值,直接加在我们发送的请求头中。
在这里为了方便,我选择了第二种方法,改造headers:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Cookie': '**********************',#请自行修改各自的cookie放入其中
'Upgrade-Insecure-Requests': '1',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'Host':'movie.douban.com',
}为了验证可行性,我们将以上程序的start修改成上次访问结束的值220,再次运行程序,发现程序又能继续显示评论了,至此…爬虫的核心部分已经搞定了。下面只要再加上存储数据库,中文分词,词频筛选、统计,绘制词云。那么这个任务就完成了。
三 数据库实装
关于python操作mongodb 使用的是pymongo库,具体的教程需要自行谷歌百度了,这里只介绍具体的用法
#数据库连接
client = MongoClient('localhost', 27017)#链接数据库 参数分别为 ip/端口号
db = client.douban #相当于 use douban 进入到 douban db中
db.authenticate('douban_sa','sa') #db授权,如果没有在启动mongod的时候加上 --auth 可以忽略这一步
collection = db.movie_comments #选中db库中的具体table
#数据库的写入
collection.update({'commenter': comment_dict['commenter']}, {'$setOnInsert': comment_dict}, upsert=True) #简单的说 就是不存在时插入,存在时不更新;
#具体来说:向表中插入comment_dict数据,如果表中已经存在 commenter == comment_dict['commenter'],则不更新;若不存在,则插入这条数据
#这里'$setOnInsert'和upsert=True是一致的,只有当upsert=True时,才会执行 存在时不更新四 中文分词
在这里我使用了jieba分词,它的官方描述很诱人‘做最好的中文分词’ 哈哈,感觉也不是不可能,就我的使用体验来说,简单,轻巧,可扩展性高。
def get_words_frequency(collection,stop_set):
'''
中文分词并返回词频
:param collection: 数据库的table表
:param stop_set: 停用词集
:return:
'''
array = collection.find({"movie_name": "春宵苦短,少女前进吧! 夜は短し歩けよ乙女","rating":{"$in":['力荐','推荐']}},{"comments":1})
num = 0
words_list = []
for doc in array:
num+=1
# print(doc['comments'])
comment = doc['comments']
t_list = jieba.lcut(str(comment),cut_all=False)
for word in t_list: #当词不在停用词集中出现,并且长度大于1小于5,将之视为课作为词频统计的词
if word not in stop_set and 5>len(word)>1:
words_list.append(word)
words_dict = dict(Counter(words_list))
return words_dict
def classify_frequenc(word_dict,minment=5):
'''
词频筛选,将词频统计中出现次数小于minment次的次剔除出去,获取更精确的词频统计
:param word_dict:
:param minment:
:return:
'''
num = minment - 1
dict = {k:v for k,v in word_dict.items() if v > num}
return dict
def load_stopwords_set(stopwords_path):
'''
载入停词集
:param stopwords_path: 文本存放路径
:return:集合
'''
stop_set = set()
with open(str(stopwords_path),'r') as fp:
line=fp.readline()
while line is not None and line!= "":
# print(line.strip())
stop_set.add(line.strip())
line = fp.readline()
# time.sleep(2)
return stop_set五 词云生成
本着简洁、强大、易用的目的,我选择用wordcloud库来制作词云。
def get_wordcloud(dict,title,save=False):
'''
:param dict: 词频字典
:param title: 标题(电影名)
:param save: 是否保存到本地
:return:
'''
# 词云设置
mask_color_path = "bg_1.png" # 设置背景图片路径
font_path = '*****' # 为matplotlib设置中文字体路径;各操作系统字体路径不同,以mac ox为例:'/Library/Fonts/华文黑体.ttf'
imgname1 = "color_by_defualut.png" # 保存的图片名字1(只按照背景图片形状)
imgname2 = "color_by_img.png" # 保存的图片名字2(颜色按照背景图片颜色布局生成)
width = 1000
height = 860
margin = 2
# 设置背景图片
mask_coloring = imread(mask_color_path)
# 设置WordCloud属性
wc = WordCloud(font_path=font_path, # 设置字体
background_color="white", # 背景颜色
max_words=150, # 词云显示的最大词数
mask=mask_coloring, # 设置背景图片
max_font_size=200, # 字体最大值
# random_state=42,
width=width, height=height, margin=margin, # 设置图片默认的大小,但是如果使用背景图片的话,那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
# 生成词云
wc.generate_from_frequencies(dict)
bg_color = ImageColorGenerator(mask_coloring)
# 重定义字体颜色
wc.recolor(color_func=bg_color)
# 定义自定义字体,文件名从1.b查看系统中文字体中来
myfont = FontProperties(fname=font_path)
plt.figure()
plt.title(title, fontproperties=myfont)
plt.imshow(wc)
plt.axis("off")
plt.show()
if save is True:#保存到
wc.to_file(imgname2)六 代码合并
import requests,time
from lxml import etree
import time
from all_headers import Headers
from pymongo import MongoClient
import jieba
from collections import Counter
from wordcloud import WordCloud,ImageColorGenerator
from scipy.misc import imread
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
def get_comments(url,headers,start,max_restart_num,movie_name,collection):
if start >= 5000:
print("已爬取5000条评论,结束爬取")
return
data = {
'start': start,
'limit': 20,
'sort': 'new_score',
'status': 'P',
}
response = requests.get(url=url, headers=headers, params=data)
tree = etree.HTML(response.text)
comment_item = tree.xpath('//div[@id ="comments"]/div[@class="comment-item"]')
len_comments = len(comment_item)
if len_comments > 0:
for i in range(1, len_comments + 1):
votes = tree.xpath('//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="votes"]'.format(i))
commenters = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="comment-info"]/a'.format(i))
ratings = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="comment-info"]/span[contains(@class,"rating")]/@title'.format(
i))
comments_time = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]//span[@class="comment-info"]/span[@class="comment-time "]'.format(
i))
comments = tree.xpath(
'//div[@id ="comments"]/div[@class="comment-item"][{}]/div[@class="comment"]/p'.format(i))
vote = (votes[0].text.strip())
commenter = (commenters[0].text.strip())
try:
rating = (str(ratings[0]))
except:
rating = 'null'
comment_time = (comments_time[0].text.strip())
comment = (comments[0].text.strip())
comment_dict = {}
comment_dict['vote'] = vote
comment_dict['commenter'] = commenter
comment_dict['rating'] = rating
comment_dict['comments_time'] = comment_time
comment_dict['comments'] = comment
comment_dict['movie_name'] = movie_name
#存入数据库
print("正在存取第{}条数据".format(start+i))
print(comment_dict)
# collection.update({'commenter': comment_dict['commenter']}, {'$setOnInsert': comment_dict}, upsert=True)
headers['Referer'] = response.url
start += 20
data['start'] = start
time.sleep(5)
return get_comments(url, headers, start, max_restart_num,movie_name,collection)
else:
# print(response.status_code)
if max_restart_num>0 :
if response.status_code != 200:
print("fail to crawl ,waiting 10s to restart continuing crawl...")
time.sleep(10)
headers['User-Agent'] = Headers.getUA()
print(start)
return get_comments(url, headers, start, max_restart_num-1, movie_name, collection)
else:
print("finished crawling")
return
else:
print("max_restart_num has run out")
with open('log.txt',"a") as fp:
fp.write('\n{}--latest start:{}'.format(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), start))
return
def get_words_frequency(collection,stop_set):
'''
中文分词并返回词频
:param collection: 数据库的table表
:param stop_set: 停用词集
:return:
'''
# array = collection.find({"movie_name": "春宵苦短,少女前进吧! 夜は短し歩けよ乙女","rating":{"$in":['力荐','推荐']}},{"comments":1})
array = collection.find({"movie_name": "春宵苦短,少女前进吧! 夜は短し歩けよ乙女","$or":[{'rating':'力荐'},{'rating':'推荐'}]},{"comments":1})
num = 0
words_list = []
for doc in array:
num+=1
# print(doc['comments'])
comment = doc['comments']
t_list = jieba.lcut(str(comment),cut_all=False)
for word in t_list:
if word not in stop_set and 5>len(word)>1:
words_list.append(word)
words_dict = dict(Counter(words_list))
return words_dict
def classify_frequenc(word_dict,minment=5):
num = minment - 1
dict = {k:v for k,v in word_dict.items() if v > num}
return dict
def load_stopwords_set(stopwords_path):
stop_set = set()
with open(str(stopwords_path),'r') as fp:
line=fp.readline()
while line is not None and line!= "":
# print(line.strip())
stop_set.add(line.strip())
line = fp.readline()
# time.sleep(2)
return stop_set
def get_wordcloud(dict,title,save=False):
'''
:param dict: 词频字典
:param title: 标题(电影名)
:param save: 是否保存到本地
:return:
'''
# 词云设置
mask_color_path = "bg_1.png" # 设置背景图片路径
font_path = '/Library/Fonts/华文黑体.ttf' # 为matplotlib设置中文字体路径没
imgname1 = "color_by_defualut.png" # 保存的图片名字1(只按照背景图片形状)
imgname2 = "color_by_img.png" # 保存的图片名字2(颜色按照背景图片颜色布局生成)
width = 1000
height = 860
margin = 2
# 设置背景图片
mask_coloring = imread(mask_color_path)
# 设置WordCloud属性
wc = WordCloud(font_path=font_path, # 设置字体
background_color="white", # 背景颜色
max_words=150, # 词云显示的最大词数
mask=mask_coloring, # 设置背景图片
max_font_size=200, # 字体最大值
# random_state=42,
width=width, height=height, margin=margin, # 设置图片默认的大小,但是如果使用背景图片的话,那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
# 生成词云
wc.generate_from_frequencies(dict)
bg_color = ImageColorGenerator(mask_coloring)
# 重定义字体颜色
wc.recolor(color_func=bg_color)
# 定义自定义字体,文件名从1.b查看系统中文字体中来
myfont = FontProperties(fname=font_path)
plt.figure()
plt.title(title, fontproperties=myfont)
plt.imshow(wc)
plt.axis("off")
plt.show()
if save is True:#保存到
wc.to_file(imgname2)
if __name__ =='__main__':
base_url = 'https://movie.douban.com/subject/26935251'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Upgrade-Insecure-Requests': '1',
'Cookie': '******', #各位根据自己账号的Cookie进行填充
'Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'Host':'movie.douban.com',
}
start = 0
response = requests.get(base_url,headers)
tree = etree.HTML(response.text)
movie_name = tree.xpath('//div[@id="content"]/h1/span')[0].text.strip()
# print(movie_name)
url = base_url+'/comments'
stopwords_path = 'stopwords.txt'
stop_set = load_stopwords_set(stopwords_path)
#数据库连接
client = MongoClient('localhost', 27017)
db = client.douban
db.authenticate('douban_sa','sa')
collection = db.movie_comments
# # print(Headers.getUA())
try:
#抓取评论 保存到数据库
get_comments(url, headers,start, 5, movie_name,None)
#从数据库获取评论 并分好词
frequency_dict = get_words_frequency(collection,stop_set)
# 对词频进一步筛选
cl_dict = classify_frequenc(frequency_dict,5)
# print(frequency_dict)
# 根据词频 生成词云
get_wordcloud(cl_dict,movie_name)
finally:
# pass
client.close()这里的背景图bg_1.png图片如下:

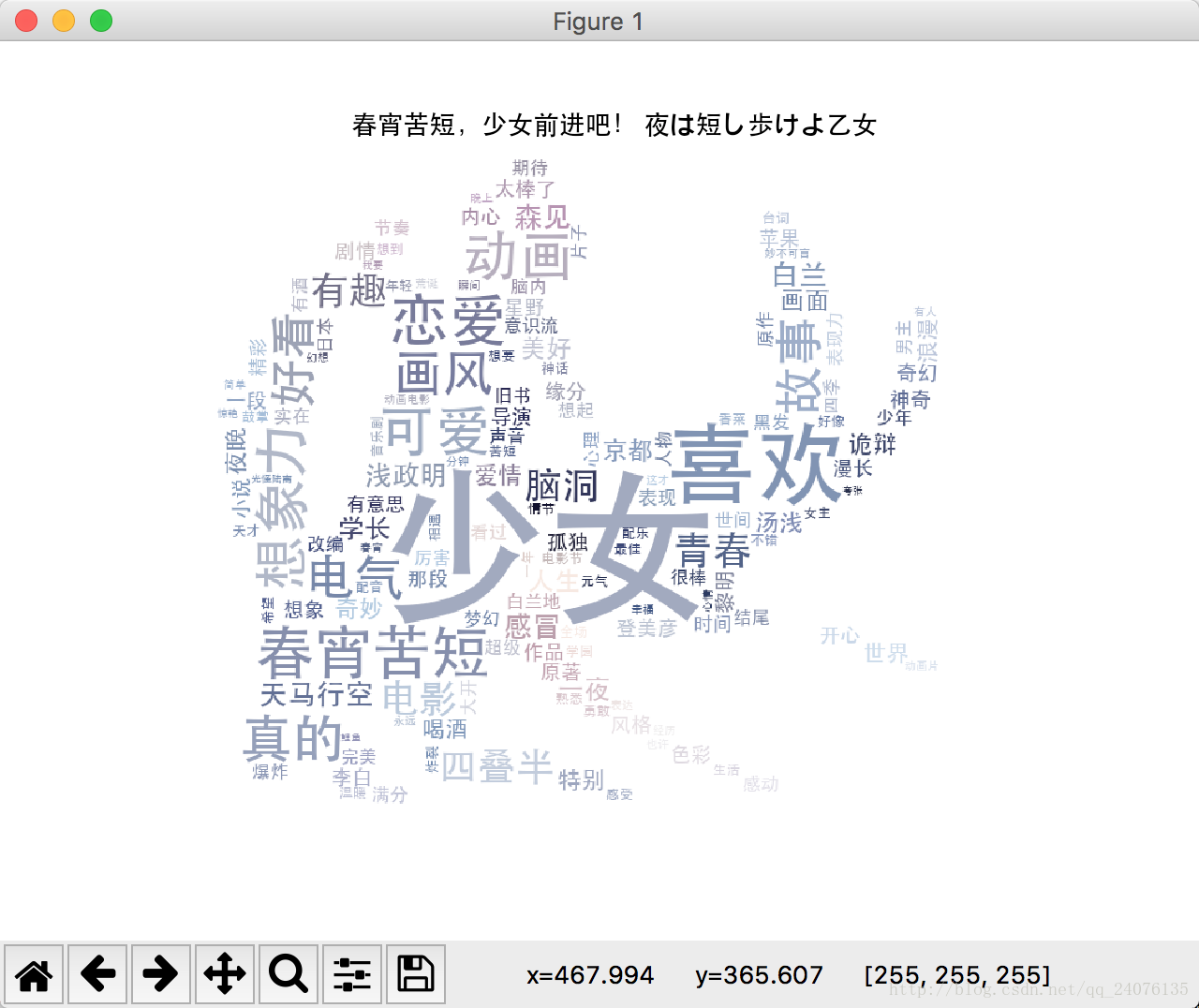
最后生成的词云如下:
七 小结
哈哈 是不是很简单,但是最终实现出来,还是觉得满满的成就感 2333
github链接:https://github.com/hylusst/requests_douban