由于豆瓣在今年5月份已经禁止展示所有短评,只展示最热的500条数据,并且在爬取到240条的时候,如果没有登录的话,会提示登录。
因此几天的爬虫,包括豆瓣的自动登录和数据爬取后批量存入pymysql数据库。
在这个爬虫完成后,其实我也在页面上找了下,在全部评论里还是能看到带有页数分页的评论的,在下面代码的基础上修改下路径和爬取数据的逻辑,其实也是能爬取的。
本文是基于scrapy框架,python 3.x下完成的。爬取了9月3日前碟中谍6的最热短评数据
这是爬虫文件结构:
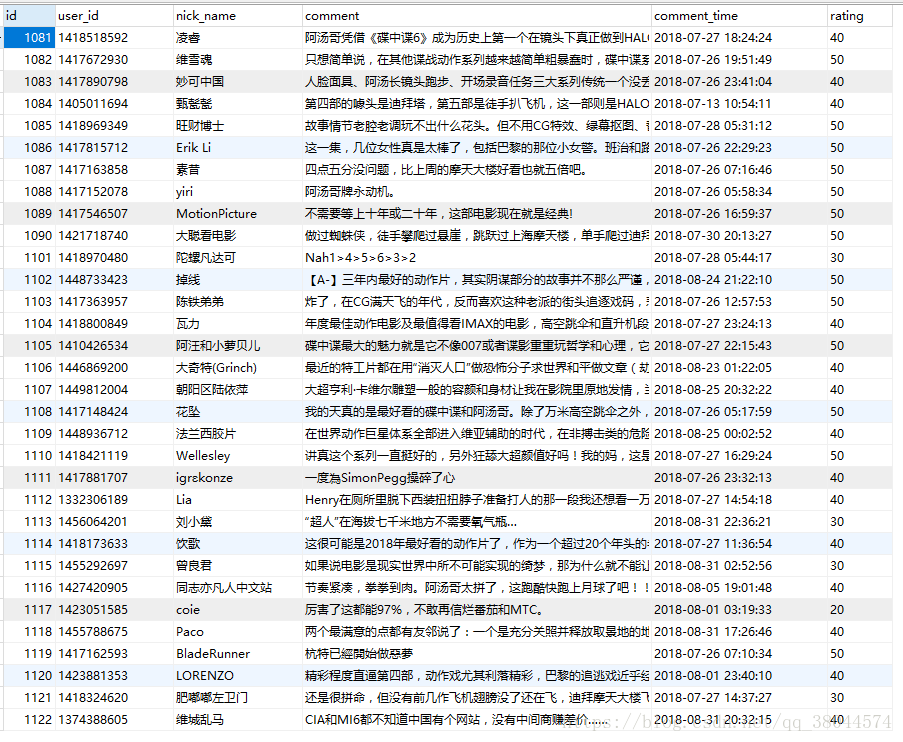
这是爬取的数据截图:
下面上代码:
dzd-content
# -*- coding: utf-8 -*-
import scrapy
from dzd.items import DzdItem
import time
import random
from faker import Factory
from urllib import parse
f = Factory.create()
class DzdContentSpider(scrapy.Spider):
name = 'dzd'
allowed_domains = ['movie.douban.com']
#构建豆瓣的登陆数据,详细的数据豆瓣可能会根据时间不同,修改相关的一些字段,但登陆的账号和密码是不会变的
formdata = {'source': 'index_nav',
# 'redir': 'https://www.douban.com',
# 'login': '登录',
'form_email': '你的账号',
'form_password': '你的密码'}
#构建访问的头文件
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection': 'keep-alive',
#使用faker中的Factory,动态生成不同的userAgent
'User-Agent': f.user_agent()
}
#重写了start_request方法
def start_requests(self):
print('------爬取开始--------')
#豆瓣有大量数据观看后的屏蔽策略,需要登录,所以要从一开始访问就要带上cookie进行访问
return [scrapy.Request(url='https://www.douban.com/accounts/login',
headers=self.headers,
meta={'cookiejar': 1},
callback=self.parse_login)]
def parse_login(self, response):
# 获取登录页面是否有验证码
img_url = response.xpath('//img[@class="captcha_image"]/@src').extract_first()
if img_url is not None:
print('Copy the link:')
link = response.xpath('//img[@class="captcha_image"]/@src').extract()[0]
print(link)
captcha_solution = input('captcha-solution:')
captcha_id = parse.parse_qs(parse.urlparse(link).query, True)['id']
#继续构造有验证码的formdata结构,将验证码的id和应该输入的值加入进去
self.formdata['captcha-solution'] = captcha_solution
self.formdata['captcha-id'] = captcha_id
#使用FormRequest进行直接提交访问
return [scrapy.FormRequest.from_response(response,
formdata=self.formdata,
headers=self.headers,
meta={'cookiejar': response.meta['cookiejar']},
callback=self.after_login,
dont_filter=True
)]
def after_login(self, response):
print('判断是否登陆成功。。。。')
# 这个位置写上你登录后自己的主页地址,用来判断是不是已经正确登录的
test_url = "https://www.douban.com/people/181618569/"
if response.url == test_url:
if response.status == 200:
print('***************')
print(u'登录成功')
print('***************\n')
else:
print('***************')
print(u'登录失败')
print('***************\n')
yield scrapy.Request(test_url,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.after_login)
#这个里的url就是需要在登录成功后爬取的地址了
yield scrapy.Request(
url='https://movie.douban.com/subject/26336252/comments?start=0&limit=20&sort=new_score&status=P&percent_type=',
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.parse)
#这个是爬取数据结构的方法,就不详细说,都能看懂的,因为没有做分布和代理池,为了防止异步
#瞬时访问次数哦过多导致封IP,在下面我做了一个延时的操作。使用time.sleep()。
def parse(self, response):
item = DzdItem()
next_url = ''
if response.status == 200:
comments_list = response.css('#comments div[class="comment-item"]')
# print(len(comments_list))
next_url = response.css('#paginator a[class="next"]::attr(href)').extract_first()
for comments in comments_list:
user_id = comments.css('::attr(data-cid)').extract_first()
comment = comments.css('.comment p span.short::text').extract_first()
nick_name = comments.css('span[class = "comment-info"] a::text').extract_first()
rating = comments.css(
'span[class = "comment-info"] span:nth-child(3)::attr(class)').extract_first().replace(' ', '')[
7:9]
comment_time = comments.css(
'span[class = "comment-info"] span:nth-child(4)::attr(title)').extract_first()
item['user_id'] = user_id
item['comment'] = comment.replace(' ', '')
item['nick_name'] = nick_name
item['rating'] = rating
item['comment_time'] = comment_time
yield item
if next_url is not None:
next_url = 'https://movie.douban.com/subject/26336252/comments' + next_url
time.sleep(random.random() * 3)
#因为是带着cookie状态进行访问的,所以不能按照以前的那种直接
#request(url,callback=)的方式,需要带上已经从登陆后的cookie
yield scrapy.Request(url=next_url,
meta={'cookiejar': response.meta['cookiejar']},#也就是说它
headers=self.headers,
callback=self.parse)
else:
print('已经没有更多的评论了')
print('评论爬取完毕')
else:
print('Request访问错误,正在尝试重新访问。。。')
time.sleep(5)
yield scrapy.Request(url=next_url,
meta={'cookiejar': response.meta['cookiejar']},
headers=self.headers,
callback=self.parse)
下面的item.py
import scrapy
class DzdItem(scrapy.Item):
#在这里声明爬取的数据有哪些需要在spider中流转的
# define the fields for your item here like:
# name = scrapy.Field()
user_id = scrapy.Field() #用户id
nick_name = scrapy.Field()#用户昵称
comment = scrapy.Field()#评论
comment_time = scrapy.Field()#评论时间
rating = scrapy.Field()#评分
pipelines.py
这部分就是讲数据批量存入数据库中了
在实际运行中,会因为短评的字段过长,导致同一批插入失败导致数据回滚,可以尝试在建表的时候,将comments列的varchar设置大写
import pymysql
class DzdPipeline(object):
comments = []
def open_spider(self, spider):
self.conn = pymysql.connect(host="localhost", user="root", passwd="Cs123456.", db="movie", charset="utf8")
self.cursor = self.conn.cursor()
# 批量插入mysql数据库
def bulk_insert_to_mysql(self, bulkdata):
try:
sql = "insert into movie_comments (user_id,nick_name,comment,comment_time,rating) values(%s, %s,%s,%s,%s)"
self.cursor.executemany(sql, bulkdata)
self.conn.commit()
except:
print('数据插入有误。。')
self.conn.rollback()
def process_item(self, item, spider):
self.comments.append([item['user_id'], item['nick_name'],item['comment'],item['comment_time'],item['rating']])
comments2=[]
comments2.append([item['user_id'], item['nick_name'],item['comment'],item['comment_time'],item['rating']])
if len(self.comments) == 5:
self.bulk_insert_to_mysql(comments2)
# 清空缓冲区
self.comments.clear()
return item
def close_spider(self, spider):
#print( "closing spider,last commit", len(self.comments))
self.bulk_insert_to_mysql(self.comments)
self.conn.commit()
self.cursor.close()
self.conn.close()
setting.py文件里,主要一步就是要设置COOKIES_ENABLED = True为True,因为我这里使用了的带着cookie访问的,scrapy默认的事False。如果想用代理池的话,可以在中间件中,如何使用代理池更换IP,百度下你就知道了。
好了,今天的代码就到这里。小伙伴如果有什么疑问或者建议,欢迎评论。我看到了一定会回复的。
我又来了,刚顺手又把数据的词云图和统计图做了
import numpy as np
import pandas as pd
import jieba
import wordcloud
from scipy.misc import imread
import matplotlib.pyplot as plt
from pylab import mpl
import seaborn as sns
from PIL import Image
import pymysql
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus']
def txt_cut(novel, stop_list):
return [w for w in jieba.cut(novel) if w not in stop_list and len(w) > 1]
def Statistics(txtcut,save_path):
# Series是指pandas的一维,获取txtcut中按照降序排列后0~20的数据
word_count = pd.Series(txtcut).value_counts().sort_values(ascending=False)[0:20]
# print(word_count)
# 是以这种形式展现的数据,
# 创建一个图形是咧 大小是15*8(长*宽)单位是英寸
plt.figure(figsize=(15, 8))
x = word_count.index.tolist() # 获取的是index列,转换成list
y = word_count.values.tolist() # 获取的是values列,转换成list
# barplot是作图方法,传入xy值,palette="BuPu_r" 设置的是柱状图的颜色样式
# BuPu_r 从左到右,颜色由深到浅,BuPu与之相反
sns.barplot(x, y, palette="BuPu_r")
plt.title('词频Top20') # 标题
plt.ylabel('count') # Y轴标题
# 如果不加这局,那么出现的就是个四方的框,这个是用来溢出轴脊柱的,加上bottom=tur,意思就是连下方的轴脊柱也溢出
sns.despine(bottom=True)
# 图片保存
plt.savefig(save_path, dpi=400)
plt.show()
def cloud(result, img_path, cloud_path, cloud_name):
result = " ".join(result) # 必须给个符号分隔开分词结果,否则不能绘制词云
# 1、初始化自定义背景图片
image = Image.open(img_path)
graph = np.array(image)
# 2、产生词云图
# 有自定义背景图:生成词云图由自定义背景图像素大小决定
wc = wordcloud.WordCloud(font_path=r"I:\word-ttf\XingKai.ttf", # 字体地址
background_color='white', # 背景色
max_font_size=100, # 显示字体最大值
max_words=100, # 最大词数
mask=graph) # 导入的图片
wc.generate(result)
# 3、绘制文字的颜色以背景图颜色为参考
image_color = wordcloud.ImageColorGenerator(graph) # 从背景图片生成颜色值
wc.recolor(color_func=image_color)
wc.to_file(cloud_path) # 按照背景图大小保存绘制好的词云图,比下面程序显示更清晰
# 4、显示图片
plt.title(cloud_name) # 指定所绘图名称
plt.imshow(wc) # 以图片的形式显示词云
plt.axis("off") # 关闭图像坐标系
plt.show()
#链接数据库,获取存入的数据
def open_db():
conn = pymysql.connect(host="localhost", user="root", passwd="Cs123456.", db="movie", charset="utf8")
cursor = conn.cursor()
sql = 'select * from movie_comments'
cursor.execute(sql)
data = cursor.fetchall()
cursor.close()
conn.close()
return data
#对数据处理,获取想要的数据,我这里的list[3]就是查询出的数据获取的
def data_process(data):
comment_ob = ''
if data is not None:
for list in data:
comment_ob += list[3] + ','
return comment_ob
def stop_list(stop_path):
stopwords_path = stop_path
stop_list = []
stop_list1 = open(stopwords_path, encoding="utf-8").readlines()
for line in stop_list1:
stop_list.append(line.strip('\n').strip())
return stop_list
if __name__ == '__main__':
#停词地址
stop_path = 'I:/鬼吹灯小说分析/stop_word2.txt'
stop_list = stop_list(stop_path)
#词云背景图地址
img_path = "C:/Users/Administrator/Desktop/timg.jpg"
#词云图保存地址
cloud_path = 'C:/Users/Administrator/Desktop/dzd6_cloud.jpg'
#柱状图保存地址
stat_path = 'C:/Users/Administrator/Desktop/dzd6_stat.jpg'
#词云名称
cloud_name = '碟中谍6词云图'
data = open_db()
ob = data_process(data)
jb_comment = txt_cut(ob, stop_list)
Statistics(jb_comment,stat_path)
cloud(jb_comment, img_path, cloud_path, cloud_name)
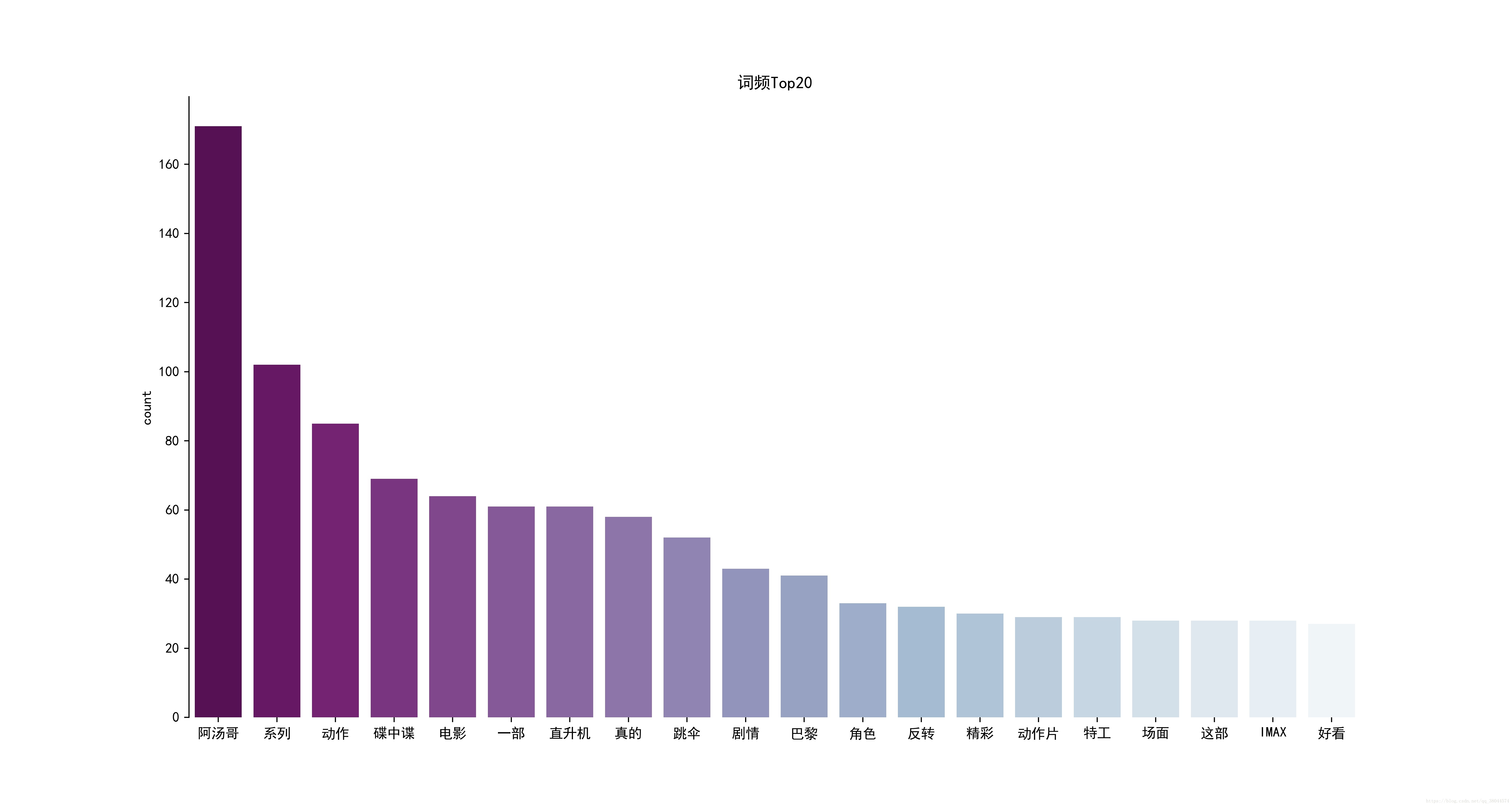

好了。这篇文章真的就只到这里了。
咱们下次见。