一、环境搭建
pip install requests
pip install lxml
pip install bs4
pip install wordcloud
pip install jieba
pip install cv2
| 库名 | 作用 |
|---|---|
| requests | 访问网页 |
| lxml | 网页解析器 |
| bs4 | 使用 BeautifulSoup 的接口将网页字符串生成一个对象,用来提取数据。 |
| wordcloud | 词云库 |
| jieba | 分词,中文引用库 |
| cv2 | opencv选取图片背景 |
二、网络爬取数据以txt格式保存数据
(一)爬取入门
# -*- coding:UTF-8 -*-
import requests
try:
target = 'https://baidu.com/'
req = requests.get(url=target)
print(req.text)
except:
print("爬取失败")

(二)教程示例
引用网上教程爬取豆瓣网前250部电影名称,并存入txt:

三、生成词云图片
读取txt内容,引入中文字体库(宋体)
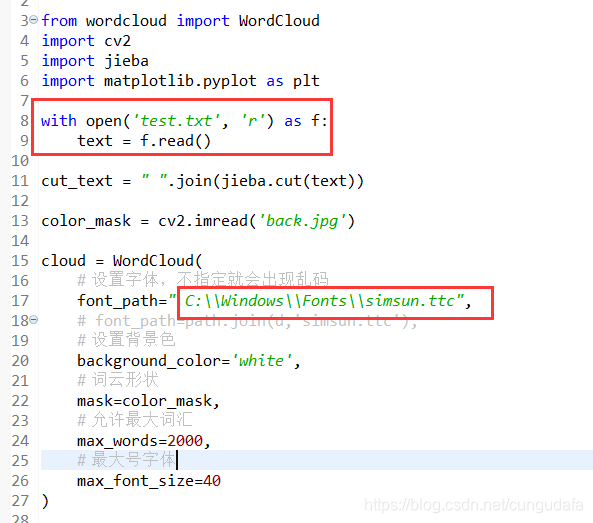

附:
总工程目录:
GetData.py 源码:
#!/usr/bin/python
# coding:utf-8
import requests
from bs4 import BeautifulSoup
test_url = 'http://movie.douban.com/top250/'
def download_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content
return data
movie_name_list = []
def parse_html(html):
soup = BeautifulSoup(html)
movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})
if movie_list_soup != None:
for movie_li in movie_list_soup.find_all('li'):
detail = movie_li.find('div', attrs={'class': 'hd'})
movie_name = detail.find(
'span', attrs={'class': 'title'}).getText()
movie_name_list.append(movie_name)
next_page = soup.find('span', attrs={'class': 'next'}).find('a')
if next_page:
parse_html(download_page(test_url + next_page['href']))
return movie_name_list
def main():
file = r"pythonworkinfo.txt"
fp = open(file, "w")
handle = parse_html(download_page(test_url))
if handle != None:
handle = list(handle)
for ele in handle:
fp.write(ele[0])
print(ele)
fp.close()
if __name__ == '__main__':
main()
MakeCloud.py 源码:
# coding: utf-8
from wordcloud import WordCloud
import cv2
import jieba
import matplotlib.pyplot as plt
with open('test.txt', 'r') as f:
text = f.read()
cut_text = " ".join(jieba.cut(text))
color_mask = cv2.imread('back.jpg')
cloud = WordCloud(
# 设置字体,不指定就会出现乱码
font_path=" C:\\Windows\\Fonts\\simsun.ttc",
# font_path=path.join(d,'simsun.ttc'),
# 设置背景色
background_color='white',
# 词云形状
mask=color_mask,
# 允许最大词汇
max_words=2000,
# 最大号字体
max_font_size=40
)
wCloud = cloud.generate(cut_text)
wCloud.to_file('cloud.jpg')
plt.imshow(wCloud, interpolation='bilinear')
plt.axis('off')
plt.show()