记录一下学习anomaly detection的学习过程以及每日计划。
领域背景知识
确定异常检测任务:MVTec AD数据集。图像级别或者像素级别的检测任务。数据集的背景比较单一,但是检测的缺陷一般都是比较小的缺陷。
现阶段常用的三种检测方法:
1、基于重建的异常异常检测:自动编码器和生成对抗网络(GANS)
自编码器关注的是样本的重构能力,而GAN关注的是样本的生成能力。
2、基于合成的方法(synthesizing-based method)
3、基于编码的方法(embedding-based method)。这类方法使用ImageNet的预训练特征。例如SimpleNet。它将ImageNet特征映射到目标域上,然后在特征图上加入高斯噪声模拟缺陷,两个特征图一起在判别器中进行判断和生成loss。
4、zero/few-shot检测
基于zero/few-shot检测最大的好处就是,我只通过一个模型就可以完成对所有缺陷的检测。不需要对每个类别设置一个分类器。但是需要注意的是,不是所有的模型都遵循上面的定义。像是PatchCore,它也有few-shot实现,但是是指所用的数据量是n(way)×k(shot)张图片,实际上还是对每个类别设置一个单类的classifier。考虑到项目需求,还是挑着一个模型检测所有缺陷的看。
具体算法(zero/few-shot)
RegAD:RegAD是冷启动(只使用正常样本),基于MVTecAD数据集的话,有两种训练setting。第一种是leave-one-setting,首先在target类别之外的正常图片上进行训练,然后根据target的support数据集进行正态分布估计,最后对target的测试集进行推理。另一种setting就是对每一类的support数据进行训练,也是训练一个单类的分类器。github源码提供的训练方式是针对setting(i)的,我们关注的也是这个方法。如果本项目的welded_seam可以和MVTecAD一个规模的话是可以做的。这个算法虽然不是针对每个类别的单类分类器。但也需要一个正态分布的估计过程,在MVTecAD上是4秒。
有个问题:工程上怎么应用呢?输入若干张图片,四秒生成一种缺陷的模型,然后进行推理。这样本质上不还是一种单类检测器吗。刚刚又有个问题,对于本项目来说,所有的support数据集都是一样的啊。可以这样!现在目前提供的垂直焊缝数据集上进行训练,然后把水平焊缝里的正常样本做support,异常样本做infer。这样support数据集就是不同的。
WinCLIP:这是基于CLIP的多模态模型,采用无监督的形式。输入N个图片-文字对,其中N*N-N个都是负样本,只有N个文字-图片对是正样本。我猜:它使用CLIP的预训练模型,然后在MVTec AD数据集上做微调,文字指示划分为四个。但是这个没有开源,不过后面这个竞赛第一名的论文是基于WinCLIP修改的,它有源码。
算法部署(项目)
1、数据集。首先把上次老师给的垂直气焊图像(不过实际用的时候应该是要检测水平焊缝)做一下裁剪。把焊缝部分提取出来,然后裁剪出一个个小格子。没有异常的小格子就是正样本,有缺陷的就是负样本。目前做了good和bubble两类。但是good中可能有咬边图像,bubble中的图像也不确定就是甲方所说的气泡,这部分还需要和老师进一步敲定。
2、目前只有一种缺陷,所以可以先用单类classifier的方法来做一下测试。选用的openvino下的anomalib框架。目前在等显卡。
3、如果上一步验证成功,可以再试试RegAD,这可能需要再标注一个咬边缺陷数据集,然后用leave-one-setting训练。
4、April GAN的论文还没看,它是这个竞赛的zero-shot冠军,另个few-shot赛道的冠军好像没开源,不过也可以关注一下其他排名的算法。
每日计划
6.29
- 看完April GAN的论文
- 显卡如果腾出地方,用anomalib跑一下自制的welded_seam数据集
- 搭建April GAN或者RegAD的环境
小结:
April GAN论文没看完,不过去李沐那里把CLIP(Contrastive Language-Image Pre-Training)的知识补了一下。用anomalib的padim和patchcore跑了一下自制数据集,两个的图像级别检测精度都在90%以上,但是patchcore的测试结果要好一些,但是特征热度图中缺陷位置不是特别准确,估计不好进行像素级别的检测。通过在github上的issue知道了他的max_epoch为1就行,(因为CNN只在特征提取中出现,epoch多了也和第一次一样)。这句话没懂,明天再看吧。
6.30
- 弄懂anomalib中的这些参数,尤其是train和val数据集的划分
- 在anomalib中推理结果
- 看完April GAN的论文
- 搭建April GAN或者RegAD的环境
小结:
April GAN的论文看完了,这是一个基于CLIP,或者说Win-CLIP改进的模型。可以进行zero-shot任务。image和text的encoder都是采用CLIP的,然后提供一些图片-文字对训练用于特征转换的线性层,这样就可以进行zero-shot推理了。如果要用few-shot,将support图像特征存储到memory bank中,各个阶段的memory bank特征与zero-shot中的特征图进行预先相似度比较,获得异常图,最终得到异常分数。
关于数据集的划分,目前在自制数据集上,normal中的20%和bubble中的50%用作val,val和test的内容是一样的。
最后是推理。anomalib是在train的最后一个阶段顺便做了inference。工程上调用模型检测数据集肯定要通过test.py。明天看一下它是做test还是做infer的,因为如果是做test,那么给定的数据的类别必须要是确定的才行,infer就是未知类别的待检测数据。
7.2
- 做anomalib的推理部署
- 搭建April GAN的环境
- 跑April GAN
小结:
anomalib的推理是用tools/inference/lightning_inference.py这个py文件。推理时间是400ms(3060),服务器上的推理时间是350ms。虽然有openvino的推理文件,但需要将模型转换一下,目前还没有对推理时间有要求,所以暂时就不用考虑这个了。
April GAN环境搭建没有啥难度,目前在服务器上搭建好了。但是服务器有个问题,基于conda的命令,除了激活虚拟环境以外,都会报错没有pip,找不到原因。这个项目的环境是新建了一个3.8的虚拟环境,然后安装requirement.txt里的包。(好吧话说早了,这样虽然可以创建一个虚拟环境,但是在装包时会有各种问题,所以明天还是需要再试一下能不能创建conda环境,或者解决使用conda时出现的pip问题)
April GAN明天具体看一下代码,首先是它对MVTecAD数据集做了啥,可以用在目录结构相同的welded_seam数据集上吗?
7.4
- 创建April GAN的conda环境并装包
- 看April GAN的数据读取代码
- 制作welded_seam的分割标签,并从json转png
- 试试可不可以直接做few-shot的infer,借用zero-shot的各阶段特征,与memory bank中的support特征进行对比
- 跑April GAN网络
小结:
April GAN的环境配好了,conda环境还是不行,用的python自带的虚拟环境通过 source April_GAN/bin/activate 启动环境。但有一个隐患是horvod包安装失败,这个是用于分布式训练的,不知道会不会对后面训练有影响,之前是按照这个horvod教程走的。后面确实需要的话,换个教程,然后直接新建一个虚拟环境,安装除了horvod以外的所有包,最后单独安装horvod。
png形式的分割标签做好了。但是目录结构和April GAN要求的mvtec的格式不同。需要在各个缺陷下面设置train和test目录。其中train中需要包含200+正常样本,test中则包含正常样本和各类缺陷样本各20张。目前还是缺乏正常样本。
数据集改好了,放到服务器上等卡。
7.6
- 更改切割block的思路,进行有重合地切割,搭建infer集
- 做汇报ppt
- April GAN等卡训练
小结:
one-classier的anomaly-detection算法可以不用看了,只看基于zero/few-shot的算法。
这次block是按照stride=100进行切割(焊缝的平均宽高为320*3200),infer集和test集怎么设计呢?test中放入不重样的图片,infer中放入数据增强的图片?还是test中放入原图及增强后的图片,infer中放入没见过的图片及其增强图片?我觉得应该是后者。下午做完汇报ppt摘一下。
7.7
现在汇报完了,把数据集在April-GAN上跑一下基于mvtecAD和VISA的zero-shot和few-shot,看一下热度图就行。如果甲方还给数据集的话,可以基于几个种类的焊缝缺陷,跑few-shot的其他种类缺陷。
基于April-GAN在welded_seam上跑一下zero和few shot,结果如下:
zero-shot
基于visa数据集训练映射

基于mvtec数据集训练映射

few-shot
基于visa数据集训练映射,在welded_seam采用
5shot

10shot

20shot

基于mvtec数据集训练映射,在welded_seam采用
5shot

10shot

20shot

现在看不是shot越高效果越好,5shot时推理时间大概是1.4s一张图片,10shot需要2s一张,zero-shot是0.5s一张。然后现在看存在的问题是:
有一定误判,或者会将其他缺陷检测为气泡。现在使用mvtec或者visa做得特征映射,如果是用本项目的正常样本或者咬边做特征映射,然后在bubble上做推理效果会不会好一点呢?
再是这些指标都是啥意思?
老师给了些新数据,提取一些气泡和正常样本出来。
7.14&7.15
好歹也算是个项目,虽然做不到底,但是也是可以拿来说的。所以好好干!
- 看论文和代码的train部分,思考如何用welded_seam数据集来跑train
- 完善可视化,将缺陷图映射回原图
- 还有一些新图片,再提取出气泡和正常样本
- 搞懂各个指标的含义
跑了下mvtec数据集,这个模型其实是一个二分类模型,不会分辨出这个缺陷具体是什么。
又看了遍论文,其实关键在于zero-shot的训练部分,如果想提高模型精度,我觉得最直接的就是用welded-seam的咬边数据集去做zero-shot部分的特征映射,然后在bubble上做few-shot推理。这个埋个坑,先把异常图到分割结果的可视化做出来。
说一下各个指标的特点,对于分类来说,AUROC,F1-max和AP都很高。分割多了PRO(交并比),该任务的F1-max和AP很低,AUROC,F1-max和PRO很高。我目前还是不清楚,这些指标的高低会对分割结果有什么具体的影响。
7.17
- 实现半透明的可视化
- 做个咬边数据集,标注以后再进行格式转换(json-png)
- 生成meta.json
- 训练特征映射,然后重新进行zero-shot推理
妥协了,在可视化方面用的黄色线圈出来,半透明的不会弄。
咬边数据集做出来了,命名为welded_1,明天用它跑一下train
7.18
- 用咬边数据集训练特征映射,做zero-shot推理
- 做基于mvtec数据集权重的5shot推理,生成mask,再进行可视化
- 还是试试半透明的可视化怎么实现
第一步的训练做完了,训练效果很差,思考原因我觉得是因为尽管train中包含的缺陷样本种类太单一了,导致模型学到的特征只针对咬边。从缺陷图也可以发现,识别到的缺陷区域都是在咬边的位置上。所以除非是把本数据集做大,否则不会采取使用自制数据集训练特征映射。另外,可以把自制的咬边数据集也放进welded_seam的test里做few-shot推理。需要注意的是,模型是单分类的,智慧检测是否有缺陷,不会返回缺陷类别。
第二步除了bubble以外,还在其中加入了undercut类,发现检测效果非常差。
第三个半透明的可视化实现了,加入了一个红色的掩码,通过cv2.addWeight函数设置了img和mask的透明度,实现了两者的结合。
明天把bubble的推理结果发给老师,然后告诉他undercut的结果很差(两种方法都试过了)
7.20
- 先看April GAN的分割头,损失函数
- 能不能将分割头换成检测头
- 或者是看其他的few-shot目标检测算法能不能做这个数据集
放弃掉分割算法的原因一个是最后的缺陷区域太细碎,无法通过一个边界框框出来;再一个是分割算法的速度太慢了。嗷对,虽然分割不用了,但是可视化方面,老师建议还是用外轮廓的形式,不套透明掩码,看不清。
7.23
- 能不能将分割头换成检测头
上午看完留了两个问题:
为什么加入了文本提示会提升精度?
这个可以看WinCLIP的论文。这部分工作比较固定。就是输入一个batch的图像类别,然后生成245个句子,最后经过tokenizer得到(768,2)的文本特征。
这是因为模型的特征来自于CLIP,这是一种对比学习的方式。以图像特征为x,文本特征为y,定义代理任务为对角线的x-y对是正样本,其余的都是负样本,以此进行训练。这里引入文本信息,其实是用一种更准确的描述方法,通过文本来定义什么是有缺陷样本,什么是误差在允许范围内的正样本。
模型最终输出的image_feature有什么用?
看April GAN的流程示意图,我猜这个是用来做图像级别的缺陷检测,可以在test.py中看一下有没有做这个。
7.31
- 定下语义分割改目标检测需要修改的地方
- 看下yolo的检测头是如何设计的
- 看一些既支持语义分割,又支持目标检测的网络(mask-RCNN?不用,yolov5就支持)
从train.py文件来看,基于缺陷图的语义分割其实并不复杂,将4个(8,1369,2)的特征图经过view和差值变成了4个(8,2,imgsize,imgsize)特征图,在2这个特征通道上做softmax就是各个像素点对应的异常值,从而得到缺陷图。如果要做目标检测的话,除了类别信息,还需要回归出坐标,这个特征形式可以转化为坐标吗?然后是数据读取上,不能读入mask,需要读入检测框才可以。最后是loss函数修改。
yolo是三个尺度上的特征图,但是CLIP提取出的四个阶段是同一尺度,试验时可以只取最后一个阶段的特征做检测。
问题是在yolov5的检测头上,输出的特征图需要经过最后一个卷积层,然后再拆解为(bs,nl,x,y,no*na)。现在需要知道卷积层前后的特征图形状,需要编译看看。 最小特征图的输出为x(bs,255,20,20)。April-GAN是(bs,1369,2),理论上应该变成(bs,2+xywh+conf,w,h)。yolo面向多尺度问题,April可以将四个阶段的特征图输出变成多尺度的特征图。(其实会不会将yolo的backbone变成CLIP会好一些呢???)
8.1
- 跑一下yolov5的train.py,看一下特征图尺寸变化
- 将bubble换成坑洞这类的词,看看对于检测结果有没有改善
- 编译一下,看文字的编码特征中第一个维度究竟代表什么信息
- 浅看一下基于CLIP的目标检测论文
1、明确了yolov5中检测头是将x(bs,255,20,20) 变为 x(bs,3,20,20,85)。其中关键就是255所代表的anchor×(xywh+conf+80类),是由更高维度的特征降维来的,但是在CLIP中需要中2中升至255。这是不合理的。
2、因为CLIP借用了语言提示词做对比学习,所以对于特征描述是否准确也对模型检测有一定的影响。验证完了,有影响但不多,说明不管是原来的bubble还是welding_pits,对于CLIP都足以准确描述焊缝上的坑洞。精度有增有减,缺陷图上的变化也不大。
3、text_feature的shape是(768,2)。在1维度上,依次是normal和abnormal经过文字编码器生成的特征向量(768,)。
4、看了一篇ViLD,他是用RPN生成proposal,经过conv生成图像编码,文本则通过CLIP的文字编码器进行编码,两者通过对比学习进行学习。其中,proposal是使用CLIP作为teacher指导backbone+RPN+RoIAlign生成的。哎,其实这么看基于CLIP也可以生成有位置信息的proposal啊,怎么做到的呢?
8.2
- 观察April-GAN的few-shot输出
- 搜集few-shot目标检测算法
1、现在April-GAN在few-shot时的输出是zero-shot与few-shot的和,现在我只想看few-shot的输出结果。目前的输出里,在normal样本中误检过多会不会是因为zero-shot的结果很差呢?如果few-shot的结果好,可以调整两幅相加缺陷图的权值或者只输出few-shot。
单看few-shot的话,其实很容易对无缺陷部分产生异常值,模型还是不知道正常图像是什么样子,对于缺陷“气泡”,“焊洞”缺乏认识。CLIP的模型推理速度还是太慢了,先放一放。最后如果想启用的话,最好还是用较大的welding_seam数据集来训练映射层。
8.9
- 在anomalib上跑一下bubble数据集,看看精度和推理速度
- 试一下anomalib跑efficient_ad
1、跑出来看分割的精度依然不高,不过误检比April-GAN要小很多,可以再制一个数据集看看效果
2、现在是卡在自制数据集上了。不过有个问题,就是当我要训练mvtec时,下载了很多数据集,明天要不就先把这几个数据集下完,把mvtec的代码跑起来,再试试自制的welded_seam能不能跑
8.13
- 跑通efficient_ad
- 看下efficient_ad的论文
- 针对这次采集的数据,制作一个数据集
- 在新数据集上使用April GAN再试一下
1、跑mvtec时精度很高,自制的welded_seam精度很低。有可能是数据集的组成形式不一样,改成mvtec一样的再试试。要是精度还低,就补充一些正常图像进去。efficient_ad的效果很差,不予采用了就。patchcore的效果还挺不错的,目前F1-score是0.44,AUROC是0.99。F1低的原因我觉得是召回率比较低,这个和阈值也有一定关系,在热度图里可以看到,尽管有些缺陷没有检测出来,但是还是有一定热度的,所以我想把8月数据集里的bubble提出来,做个test看看结果。
2、没用,不看了,去看patchcore
3、制作了一个normal数据集,一共是436张正常的block,补充到welded_seam数据集中了。
4、可试可不试了,因为太慢了。
8.14
- 用anomalib做pathcore的predict,改变阈值看看效果
- 把上次采集数据中的bubble,飞溅,焊瘤提取出来,用作predict
- 看patchcore论文
1、predict跑通了,现在是在热度图上放分割结果。单独跑一下1689的block10和11,因为这个问题是关乎焊瘤的检测效果。因为方案设计的关系,所以截取的焊瘤大多分布在两个block中,在block10中尚且有焊瘤的特征,但在block11中可能就难以观测到了。阈值根据官方手册的说明进行修改。
当前阈值下,bubble的效果还好,其他两种效果就比较差了,是因为没有给这两种数据做test?明天看看论文吧,需要的话就补充上。
2、不做咬边数据集,因为现在采集的图片放大以后,很多看起来都像是有咬边的。如果要加入咬边数据,需要对normal数据进行大规模清洗,可能满足要求的也不会很多,所以就先试试其他四种缺陷的检测效果。
spatter和beading提取好了,bubble中只把“微信图片”的block分好了,其他IMG开头的block没分。
跑predict可以在分好的bubble等四个文件夹中跑,也可以直接在各个图片的文件夹下跑。
3、明天一定要看了,因为这个模型的效果还不错。
8.16
- 修改阈值跑跑这几个数据集的predict
- 一定看patchcore的论文。为什么训练一个epoch就够了,还有什么可以优化的参数吗?
1、我认为这个阈值应该是anomaly map里大于这个最近邻距离就判定为异常。但是现在我不知道这个值应该是多少,正常来说应该是0-255之间?0.1,1,100,200都试过没有效果。这个最后再试吧,先调整其他的参数
2、论文看完了看懂了。训练阶段还需要调整的参数是coreset生成时,最近邻的数量以及采样的比例。两个调整方向就是增大num_neighbors和coreset_sampling_ratio。必然会导致推理速度变慢,不过可以试着看看效果如果。最后再看看有没有办法有效地改阈值。后面如果要调试别的缺陷数据集,由于数据很少嘛,memory bank里的东西少,所以这两个值可以适当加大,牺牲训练和推理速度换一点精度。
8.17
- 增大num_neighbors和coreset_sampling_ratio,看看patchcore的训练结果
- 这个anomalib能不能调试整个训练过程啊,如果在lighting_net里加点应该可以
- 最后可以试试怎么改阈值
1、coreset_sampling_ratio修改为0.2和0.3均无法训练,neighbor改了对于模型也没有很大的变化,所以这两个因子有影响但不多,可以在最终确定了patchcore后再进行调参。现在转而去看看改阈值(改验证集)。
2、确实是的
3、在github的issue里找到的:Anomalib目前有一个自适应阈值机制,旨在解决阈值问题。自适应阈值机制为一系列阈值计算验证集上的F1分数。最终的阈值是导致F1得分最高的阈值。这种方法的一个主要缺点是验证集需要包含异常样本,这在现实世界的异常检测问题中可能并不总是可用的。所以这个阈值应该是在val时确定的,修改val集也会修改这个阈值,目前的阈值感觉偏高了,应该把val集变简单(或者和predict相近)会使得阈值降低一点。
现在把8月采集的一部分bubble换成val了,借此来改变阈值,同时扩充了train,明天跑一下看看有没有好一些。
8.18
- 跑一下拓充后的welded_seam_2数据集
- 试试reverse distillation网络(有2022和2023CVPR两版)
- 试试dream网络(分割的F1比较高)
1、在autodl的anomalib服务器上跑了下新数据集,果然在val换成比较简单的数据以后,阈值明显提升了,用这个模型和阈值再在原来welded_seam_1上的val上跑,效果也不错。目前在welded_seam_2的val上F1-score是0.69。后续试试另外两个,如果效果一般,就继续研究该模型的可视化(在原图上标注缺陷区域)和openvino部署。
2、anomalib上的是2022版本的,跑起来效果不好。还有个2023CVPR的reverse distillation++,官方强调得是与patchcore相近的精度和更少的推理速度。现在offical代码也出来了,如果patchcore推理速度不满意可以再试试这个。
3、也不高。除了patchcore都不太好,为啥呢?
8.19
- 修改可视化
- openvino推理加速
1、调试的时候找到welded_seam_2对应的pixel_threshold了:51.8008。位置在
src/anomalib/models/components/base/anomaly_module.py的94行
可视化现在已经修改为原图+mask。位置在
src/anomalib/post_processing/visualizer.py的203行
注意:只修改了segmentation的visualization,classification暂时没有修改
2、不用openvino推理加速,2080Ti的infer速度1秒3张。如果要使用openvino的话,查了下官方的github issue,其实说是解决了这个bug。可能需要把整个工程重新替换成最新版的。
April GAN总结
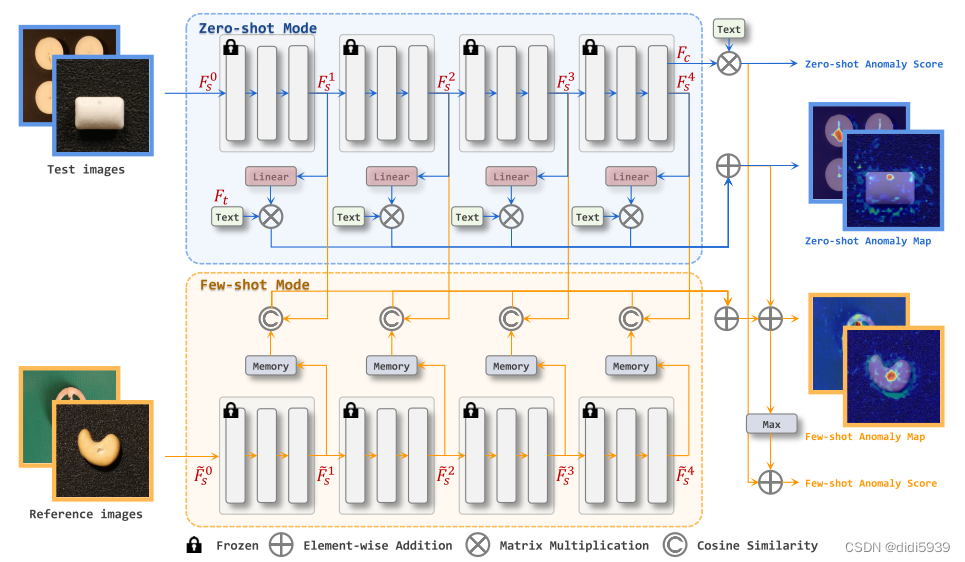 输入:518×518图像
输入:518×518图像
网络结构:
1、图像经过CLIP编码器生成四个阶段的特征图(1369,1024),再经过一个线性层将特征映射成可以和文字特征耦合的形状(1369,768)
2、文字以模板+类别+状态的形式组成句子,经过编码生成(768,2)的文字特征。这是由normal的sentence和abnormal经过文字编码器生成的两个(768,)特征向量stack形成的。
3、图像特征矩阵和文字特征矩阵相乘得到(1369,2)的特征,对于语义分割任务可以直接输出(2,w,h)的缺陷图
小结:
对于目标检测任务来说,(1369,2)的特征需要经过1×1的卷积变成(anchor×(xywh+conf+2类别), w,h),然后view为(anchor, xywh+conf+2类别, w,h)。卷积的这个步骤不合理。我认为不适合直接后接检测头。根本上来说,CLIP是对整个图像进行特征提取,缺乏图像区域特征,因此不适用于单阶段的目标检测任务。
试验了更换缺陷名称(bubble->welding_pits),效果不明显;将分割问题变成检测问题不可行,其一是受限于文字特征的shape,不能做升维,或者说CLIP是对整幅图像提特征,不是对图像的个别区域;其二是基于CLIP的目标检测多为双阶段的,不如直接去找few-shot算法;最后,检测速度很慢很慢,不满足实际的工程需要。如果想启用的话,最好还是用较大的welding_seam数据集来训练映射层。
PatchCore总结
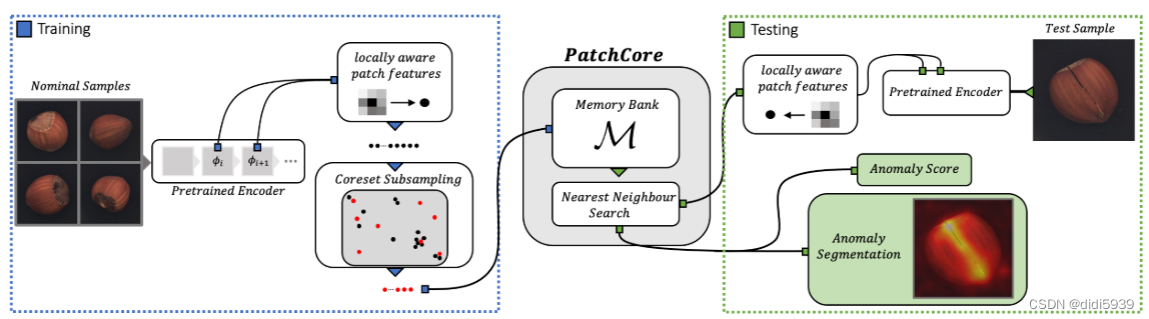 训练阶段:送入无缺陷的Xtrain生成特征存入memory bank
训练阶段:送入无缺陷的Xtrain生成特征存入memory bank
测试阶段:Xtest生成特征后与memory bank中的特征进行最近邻查找,返回的最近邻距离矩阵经过reshape可以变成缺陷图和缺陷分数
网络有三个创新点:
1、Locally aware patch features
将训练图片输入进一个基于ImageNet的backbone中,获取中层的特征,存入memory bank。为了提高中层特征的感受野,保留分辨率以及不加深特征,以每个点为中心,以p为半径,将该patch的特征进行聚合,替代原本该点处特征。
2、Coreset-reduced patch-feature memory bank
不能把整个memory bank拿来用,本文方法是从中将coreset,也即核心子集拿出来,这个子集可以充分代表整个bank的信息。提取的方法是minmax facility location,目标是使提取的mc与原来的m尽可能地接近。这也就是整个模型所谓的训练过程,让coreset和原set尽可能的接近。
3、Anomaly Detection with PatchCore
训练图片先经过pre-train的backbone,获取中间特征存入memory-bank;这个特征太大了,因此经过coreset采集进行降维;test图片则经过网络获取中间特征,在memory bank中寻找最近邻,返回与最近邻的距离,最后reshape为(batch_size, h*, w*),逐通道相加可以获得异常分数,插值扩大为(batch_size, h, w)可以获得异常图。
小结:
更具体的可以回小绿鲸的笔记里去看。这里还有个源码解读。
这个模型的推理速度是可以用于实际的。这里有两个选择,其一是train中输入没有任何缺陷的block,然后val中放五个类别的缺陷。这样其实就只是生成一个模型。好处是推理速度快,缺点是需要对五种缺陷生成一个统一的缺陷阈值,这会导致精度较低。另外一种是生成五个模型,以bubble为例,train的block是没有block,其他缺陷都有,val中的则是只有bubble这种缺陷的图片。好处是每种缺陷对应一个模型,对应一个阈值,坏处就是慢。