深度学习论文: PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
PDF: https://arxiv.org/pdf/2011.08785.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
PaDiM 在单类学习中同时检测和定位图像中的异常,PaDiM利用一个预先训练好的卷积神经网络(CNN)进行patch嵌入,利用多元高斯分布得到正态类的概率表示。同时利用了CNN的不同语义级别之间的相关性来更好地定位异常。

2 Patch Distribution Modeling(PaDiM)
PaDiM是一种基于图像Patch的算法。它依赖于预先训练好的CNN功能提取器。 将图像分解为多个面片,并使用不同的特征提取层从每个面片中提取嵌入。 将不同层次的激活向量串联起来,得到包含不同语义层次和分辨率信息的嵌入向量。这有助于对细粒度和全局上下文进行编码。 然而,由于生成的嵌入向量可能携带冗余信息,因此使用随机选择来降低维数。 在整个训练批次中,为每个面片嵌入生成一个多元高斯分布。因此,对于训练图像集的每个面片,我们有不同的多元高斯分布。这些高斯分布表示为高斯参数矩阵。 在推理过程中,使用马氏距离对测试图像的每个面片位置进行评分。它使用训练期间为面片计算的协方差矩阵的逆矩阵。 马氏距离矩阵形成了异常图,分数越高表示异常区域。
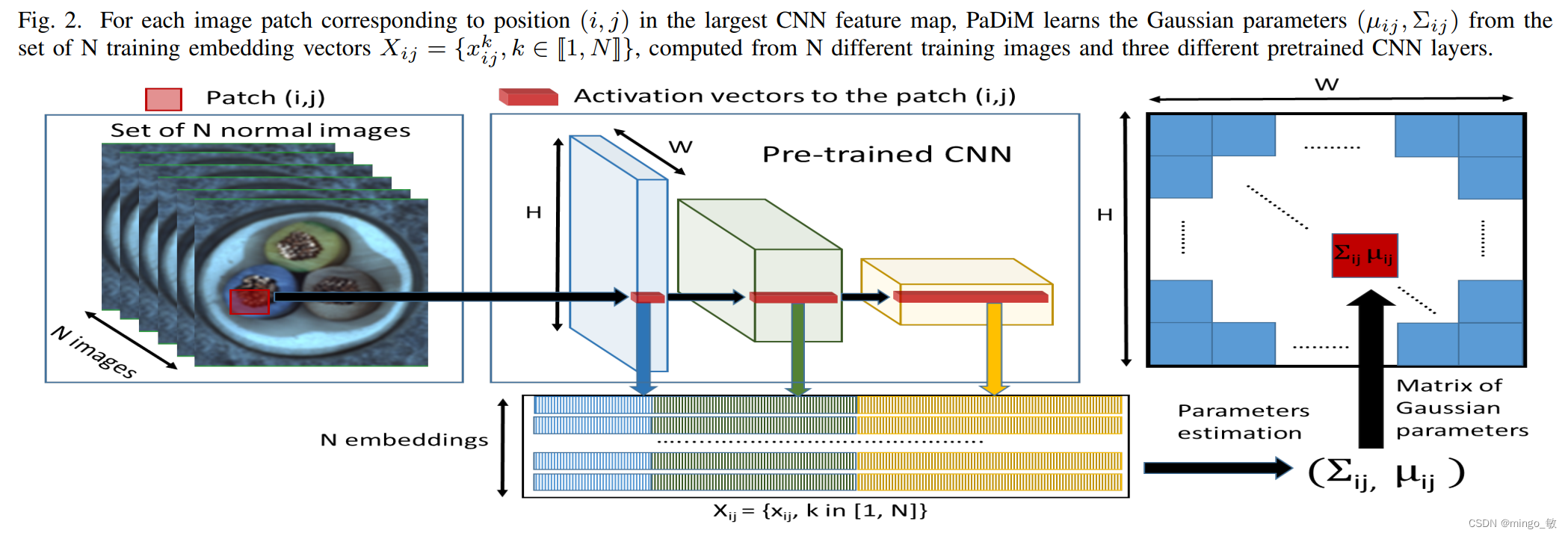
3 PyTorch代码
# !/usr/bin/env python
# -- coding: utf-8 --
# @Time : 2023/6/2 15:07
# @Author : liumin
# @File : run_PaDiM.py
import random
from random import sample
import argparse
import numpy as np
import os
import pickle
from tqdm import tqdm
from collections import OrderedDict
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
from sklearn.metrics import precision_recall_curve
from sklearn.covariance import LedoitWolf
from scipy.spatial.distance import mahalanobis
from scipy.ndimage import gaussian_filter
from skimage import morphology
from skimage.segmentation import mark_boundaries
import matplotlib.pyplot as plt
import matplotlib
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision.models import wide_resnet50_2, resnet18
import os
# import tarfile
from PIL import Image
from tqdm import tqdm
# import urllib.request
import torch
from torch.utils.data import Dataset
from torchvision import transforms as T
random.seed(1024)
torch.manual_seed(1024)
torch.cuda.manual_seed_all(1024)
# URL = 'ftp://guest:[email protected]/mvtec_anomaly_detection/mvtec_anomaly_detection.tar.xz'
CLASS_NAMES = ['bottle', 'cable', 'capsule', 'carpet', 'grid',
'hazelnut', 'leather', 'metal_nut', 'pill', 'screw',
'tile', 'toothbrush', 'transistor', 'wood', 'zipper']
class MVTecDataset(Dataset):
def __init__(self, dataset_path='/home/liumin/data/mvtec_ad/', class_name='bottle', is_train=True,
resize=256, cropsize=224):
assert class_name in CLASS_NAMES, 'class_name: {}, should be in {}'.format(class_name, CLASS_NAMES)
self.dataset_path = dataset_path
self.class_name = class_name
self.is_train = is_train
self.resize = resize
self.cropsize = cropsize
# self.mvtec_folder_path = os.path.join(root_path, 'mvtec_anomaly_detection')
# download dataset if not exist
# self.download()
# load dataset
self.x, self.y, self.mask = self.load_dataset_folder()
# set transforms
self.transform_x = T.Compose([T.Resize(resize, Image.ANTIALIAS),
T.CenterCrop(cropsize),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
self.transform_mask = T.Compose([T.Resize(resize, Image.NEAREST),
T.CenterCrop(cropsize),
T.ToTensor()])
def __getitem__(self, idx):
x, y, mask = self.x[idx], self.y[idx], self.mask[idx]
x = Image.open(x).convert('RGB')
x = self.transform_x(x)
if y == 0:
mask = torch.zeros([1, self.cropsize, self.cropsize])
else:
mask = Image.open(mask)
mask = self.transform_mask(mask)
return x, y, mask
def __len__(self):
return len(self.x)
def load_dataset_folder(self):
phase = 'train' if self.is_train else 'test'
x, y, mask = [], [], []
img_dir = os.path.join(self.dataset_path, self.class_name, phase)
gt_dir = os.path.join(self.dataset_path, self.class_name, 'ground_truth')
img_types = sorted(os.listdir(img_dir))
for img_type in img_types:
# load images
img_type_dir = os.path.join(img_dir, img_type)
if not os.path.isdir(img_type_dir):
continue
img_fpath_list = sorted([os.path.join(img_type_dir, f)
for f in os.listdir(img_type_dir)
if f.endswith('.png')])
x.extend(img_fpath_list)
# load gt labels
if img_type == 'good':
y.extend([0] * len(img_fpath_list))
mask.extend([None] * len(img_fpath_list))
else:
y.extend([1] * len(img_fpath_list))
gt_type_dir = os.path.join(gt_dir, img_type)
img_fname_list = [os.path.splitext(os.path.basename(f))[0] for f in img_fpath_list]
gt_fpath_list = [os.path.join(gt_type_dir, img_fname + '_mask.png')
for img_fname in img_fname_list]
mask.extend(gt_fpath_list)
assert len(x) == len(y), 'number of x and y should be same'
return list(x), list(y), list(mask)
def denormalization(x):
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
x = (((x.transpose(1, 2, 0) * std) + mean) * 255.).astype(np.uint8)
return x
def embedding_concat(x, y):
B, C1, H1, W1 = x.size()
_, C2, H2, W2 = y.size()
s = int(H1 / H2)
x = F.unfold(x, kernel_size=s, dilation=1, stride=s)
x = x.view(B, C1, -1, H2, W2)
z = torch.zeros(B, C1 + C2, x.size(2), H2, W2)
for i in range(x.size(2)):
z[:, :, i, :, :] = torch.cat((x[:, :, i, :, :], y), 1)
z = z.view(B, -1, H2 * W2)
z = F.fold(z, kernel_size=s, output_size=(H1, W1), stride=s)
return z
def plot_fig(test_img, scores, gts, threshold, save_dir, class_name):
num = len(scores)
vmax = scores.max() * 255.
vmin = scores.min() * 255.
for i in range(num):
img = test_img[i]
img = denormalization(img)
gt = gts[i].transpose(1, 2, 0).squeeze()
heat_map = scores[i] * 255
mask = scores[i]
mask[mask > threshold] = 1
mask[mask <= threshold] = 0
kernel = morphology.disk(4)
mask = morphology.opening(mask, kernel)
mask *= 255
vis_img = mark_boundaries(img, mask, color=(1, 0, 0), mode='thick')
fig_img, ax_img = plt.subplots(1, 5, figsize=(12, 3))
fig_img.subplots_adjust(right=0.9)
norm = matplotlib.colors.Normalize(vmin=vmin, vmax=vmax)
for ax_i in ax_img:
ax_i.axes.xaxis.set_visible(False)
ax_i.axes.yaxis.set_visible(False)
ax_img[0].imshow(img)
ax_img[0].title.set_text('Image')
ax_img[1].imshow(gt, cmap='gray')
ax_img[1].title.set_text('GroundTruth')
ax = ax_img[2].imshow(heat_map, cmap='jet', norm=norm)
ax_img[2].imshow(img, cmap='gray', interpolation='none')
ax_img[2].imshow(heat_map, cmap='jet', alpha=0.5, interpolation='none')
ax_img[2].title.set_text('Predicted heat map')
ax_img[3].imshow(mask, cmap='gray')
ax_img[3].title.set_text('Predicted mask')
ax_img[4].imshow(vis_img)
ax_img[4].title.set_text('Segmentation result')
left = 0.92
bottom = 0.15
width = 0.015
height = 1 - 2 * bottom
rect = [left, bottom, width, height]
cbar_ax = fig_img.add_axes(rect)
cb = plt.colorbar(ax, shrink=0.6, cax=cbar_ax, fraction=0.046)
cb.ax.tick_params(labelsize=8)
font = {
'family': 'serif',
'color': 'black',
'weight': 'normal',
'size': 8,
}
cb.set_label('Anomaly Score', fontdict=font)
fig_img.savefig(os.path.join(save_dir, class_name + '_{}'.format(i)), dpi=100)
plt.close()
def load_model(args, device):
# load model
if args.arch == 'resnet18':
model = resnet18(pretrained=True, progress=False)
t_d = 448
d = 100
elif args.arch == 'wide_resnet50_2':
model = wide_resnet50_2(pretrained=True, progress=False)
t_d = 1792
d = 550
model.to(device)
model.eval()
return model, t_d, d
def train(args, model, device, idx):
# set model's intermediate outputs
outputs = []
def hook(module, input, output):
outputs.append(output)
model.layer1[-1].register_forward_hook(hook)
model.layer2[-1].register_forward_hook(hook)
model.layer3[-1].register_forward_hook(hook)
os.makedirs(os.path.join(args.save_path, 'temp_%s' % args.arch), exist_ok=True)
for class_name in CLASS_NAMES:
train_dataset = MVTecDataset(args.data_path, class_name=class_name, is_train=True)
train_dataloader = DataLoader(train_dataset, batch_size=32, pin_memory=True)
train_outputs = OrderedDict([('layer1', []), ('layer2', []), ('layer3', [])])
# extract train set features
train_feature_filepath = os.path.join(args.save_path, 'temp_%s' % args.arch, 'train_%s.pkl' % class_name)
for (x, _, _) in tqdm(train_dataloader, '| feature extraction | train | %s |' % class_name):
# model prediction
with torch.no_grad():
_ = model(x.to(device))
# get intermediate layer outputs
for k, v in zip(train_outputs.keys(), outputs):
train_outputs[k].append(v.cpu().detach())
# initialize hook outputs
outputs = []
for k, v in train_outputs.items():
train_outputs[k] = torch.cat(v, 0)
# Embedding concat
embedding_vectors = train_outputs['layer1']
for layer_name in ['layer2', 'layer3']:
embedding_vectors = embedding_concat(embedding_vectors, train_outputs[layer_name])
# randomly select d dimension
embedding_vectors = torch.index_select(embedding_vectors, 1, idx)
# calculate multivariate Gaussian distribution
B, C, H, W = embedding_vectors.size()
embedding_vectors = embedding_vectors.view(B, C, H * W)
mean = torch.mean(embedding_vectors, dim=0).numpy()
cov = torch.zeros(C, C, H * W).numpy()
I = np.identity(C)
for i in range(H * W):
# cov[:, :, i] = LedoitWolf().fit(embedding_vectors[:, :, i].numpy()).covariance_
cov[:, :, i] = np.cov(embedding_vectors[:, :, i].numpy(), rowvar=False) + 0.01 * I
# save learned distribution
train_outputs = [mean, cov]
with open(train_feature_filepath, 'wb') as f:
pickle.dump(train_outputs, f)
def val(args, model, device, idx):
# set model's intermediate outputs
outputs = []
def hook(module, input, output):
outputs.append(output)
model.layer1[-1].register_forward_hook(hook)
model.layer2[-1].register_forward_hook(hook)
model.layer3[-1].register_forward_hook(hook)
total_roc_auc = []
total_pixel_roc_auc = []
fig, ax = plt.subplots(1, 2, figsize=(20, 10))
fig_img_rocauc = ax[0]
fig_pixel_rocauc = ax[1]
for class_name in CLASS_NAMES:
test_dataset = MVTecDataset(args.data_path, class_name=class_name, is_train=False)
test_dataloader = DataLoader(test_dataset, batch_size=32, pin_memory=True)
test_outputs = OrderedDict([('layer1', []), ('layer2', []), ('layer3', [])])
train_feature_filepath = os.path.join(args.save_path, 'temp_%s' % args.arch, 'train_%s.pkl' % class_name)
print('load train set feature from: %s' % train_feature_filepath)
with open(train_feature_filepath, 'rb') as f:
train_outputs = pickle.load(f)
gt_list = []
gt_mask_list = []
test_imgs = []
# extract test set features
for (x, y, mask) in tqdm(test_dataloader, '| feature extraction | test | %s |' % class_name):
test_imgs.extend(x.cpu().detach().numpy())
gt_list.extend(y.cpu().detach().numpy())
gt_mask_list.extend(mask.cpu().detach().numpy())
# model prediction
with torch.no_grad():
_ = model(x.to(device))
# get intermediate layer outputs
for k, v in zip(test_outputs.keys(), outputs):
test_outputs[k].append(v.cpu().detach())
# initialize hook outputs
outputs = []
for k, v in test_outputs.items():
test_outputs[k] = torch.cat(v, 0)
# Embedding concat
embedding_vectors = test_outputs['layer1']
for layer_name in ['layer2', 'layer3']:
embedding_vectors = embedding_concat(embedding_vectors, test_outputs[layer_name])
# randomly select d dimension
embedding_vectors = torch.index_select(embedding_vectors, 1, idx)
# calculate distance matrix
B, C, H, W = embedding_vectors.size()
embedding_vectors = embedding_vectors.view(B, C, H * W).numpy()
dist_list = []
for i in range(H * W):
mean = train_outputs[0][:, i]
conv_inv = np.linalg.inv(train_outputs[1][:, :, i])
dist = [mahalanobis(sample[:, i], mean, conv_inv) for sample in embedding_vectors]
dist_list.append(dist)
dist_list = np.array(dist_list).transpose(1, 0).reshape(B, H, W)
# upsample
dist_list = torch.tensor(dist_list)
score_map = F.interpolate(dist_list.unsqueeze(1), size=x.size(2), mode='bilinear',
align_corners=False).squeeze().numpy()
# apply gaussian smoothing on the score map
for i in range(score_map.shape[0]):
score_map[i] = gaussian_filter(score_map[i], sigma=4)
# Normalization
max_score = score_map.max()
min_score = score_map.min()
scores = (score_map - min_score) / (max_score - min_score)
# calculate image-level ROC AUC score
img_scores = scores.reshape(scores.shape[0], -1).max(axis=1)
gt_list = np.asarray(gt_list)
fpr, tpr, _ = roc_curve(gt_list, img_scores)
img_roc_auc = roc_auc_score(gt_list, img_scores)
total_roc_auc.append(img_roc_auc)
print('image ROCAUC: %.3f' % (img_roc_auc))
fig_img_rocauc.plot(fpr, tpr, label='%s img_ROCAUC: %.3f' % (class_name, img_roc_auc))
# get optimal threshold
gt_mask = np.asarray(gt_mask_list)
precision, recall, thresholds = precision_recall_curve(gt_mask.flatten(), scores.flatten())
a = 2 * precision * recall
b = precision + recall
f1 = np.divide(a, b, out=np.zeros_like(a), where=b != 0)
threshold = thresholds[np.argmax(f1)]
# calculate per-pixel level ROCAUC
fpr, tpr, _ = roc_curve(gt_mask.flatten(), scores.flatten())
per_pixel_rocauc = roc_auc_score(gt_mask.flatten(), scores.flatten())
total_pixel_roc_auc.append(per_pixel_rocauc)
print('pixel ROCAUC: %.3f' % (per_pixel_rocauc))
fig_pixel_rocauc.plot(fpr, tpr, label='%s ROCAUC: %.3f' % (class_name, per_pixel_rocauc))
save_dir = args.save_path + '/' + f'pictures_{
args.arch}'
os.makedirs(save_dir, exist_ok=True)
plot_fig(test_imgs, scores, gt_mask_list, threshold, save_dir, class_name)
print('Average ROCAUC: %.3f' % np.mean(total_roc_auc))
fig_img_rocauc.title.set_text('Average image ROCAUC: %.3f' % np.mean(total_roc_auc))
fig_img_rocauc.legend(loc="lower right")
print('Average pixel ROCUAC: %.3f' % np.mean(total_pixel_roc_auc))
fig_pixel_rocauc.title.set_text('Average pixel ROCAUC: %.3f' % np.mean(total_pixel_roc_auc))
fig_pixel_rocauc.legend(loc="lower right")
fig.tight_layout()
fig.savefig(os.path.join(args.save_path, 'roc_curve.png'), dpi=100)
def parse_args():
parser = argparse.ArgumentParser('PaDiM')
parser.add_argument('--data_path', type=str, default='/home/liumin/data/mvtec_ad')
parser.add_argument('--save_path', type=str, default='./result')
parser.add_argument('--arch', type=str, choices=['resnet18', 'wide_resnet50_2'], default='wide_resnet50_2')
return parser.parse_args()
if __name__ == '__main__':
args = parse_args()
# device setup
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model, t_d, d = load_model(args, device)
idx = torch.tensor(sample(range(0, t_d), d))
train(args, model, device, idx)
val(args, model, device, idx)
深度学习论文: WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
PDF: https://arxiv.org/pdf/2303.14814.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述

2
深度学习论文: A Zero-/Few-Shot Anomaly Classification and Segmentation Method for CVPR 2023 VAND Workshop Challenge Tracks 1&2: 1st Place on Zero-shot AD and 4th Place on Few-shot AD
A Zero-/Few-Shot Anomaly Classification and Segmentation Method for CVPR 2023 VAND Workshop Challenge Tracks 1&2: 1st Place on Zero-shot AD and 4th Place on Few-shot AD
PDF: https://arxiv.org/pdf/2305.17382.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
为了解决工业视觉检测中产品类型的广泛多样性,我们构建一个可以快速适应众多类别且不需要或只需要很少的正常参考图像的单一模型,为工业视觉检测提供更加高效的解决方案。提出了针对2023年VAND挑战的零/少样本跟踪的解决方案。
1) 在zero-shot任务中,所提解决方案在CLIP模型上加入额外的线形层,使图像特征映射到联合嵌入空间,从而使其能够与文本特征进行比较并生成异anomaly maps。
2)当有参考图像可用时(few-shot),所提解决方案利用多个memory banks存储参考图像特征,并在测试时与查询图像进行比较。
在这个挑战中,我们的方法在零样本跟踪中取得了第一名,并在分割方面表现出色,F1得分比第二名参赛者提高了0.0489。在少样本跟踪中,我们在总体排名中获得了第四名,在分类F1得分方面排名第一。
核心要点:
- 使用状态(state)和模板(template)的提示集成来制作文本提示。
- 为了定位异常区域,引入了额外的线性层,将从CLIP图像编码器提取的图像特征映射到文本特征所在的线性空间。
- 将映射的图像特征与文本特征进行相似度比较,从而得到相应的anomaly maps。
- few-shot中,保留zero-shot阶段的额外线性层并保持它们的权重。此外,在测试阶段使用图像编码器提取参考图像的特征并保存到memory banks中,以便与测试图像的特征进行比较。
- 为了充分利用浅层和深层特征,同时利用了图像编码器不同stage的特征。
2 Methodology
总的来说,我们采用了CLIP的整体框架进行零样本分类,并使用状态和模板集合的组合来构建我们的文本提示。为了定位图像中的异常区域,我们引入了额外的线性层,将从CLIP图像编码器中提取的图像特征映射到文本特征所在的线性空间中。然后,我们对映射后的图像特征和文本特征进行相似性比较,以获取相应的异常图。对于少样本情况,我们保留零样本阶段的额外线性层并保持它们的权重。此外,我们使用图像编码器提取参考图像的特征并将其保存到内存库中,在测试阶段将其与测试图像的特征进行比较。需要注意的是,为了充分利用浅层和深层特征,我们在零本和少样本设置中都使用来自不同阶段的特征。
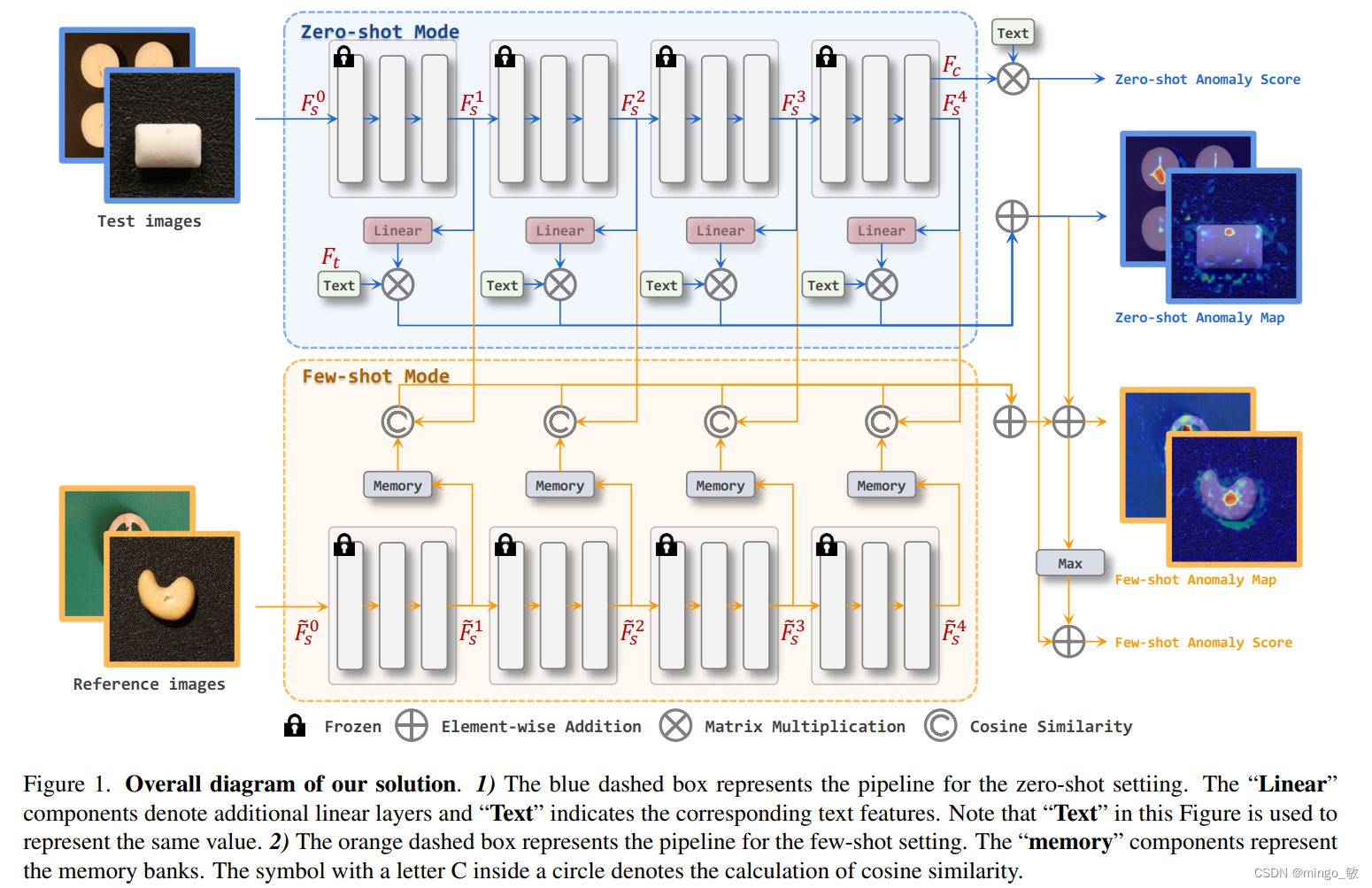
2-1 Zero-shot AD
Anomaly Classification
基于WinCLIP 异常分类框架,我们提出了一种文本提示集成策略,在不使用复杂的多尺度窗口策略的基础上显著提升了Baseline的异常分类精度。具体地,该集成策略包含template-level和state-level两部分:
1)state-level文本提示是使用通用的文本描述正常或异常的目标(比如flawless,damaged),而不会使用“chip around edge and corner”这种过于细节的描述;
2)template-level文本提示,所提方案在CLIP中为ImageNet筛选了85个模板,并移除了“a photo of the weird [obj.]”等不适用于异常检测任务的模板。
这两种文本提示将通过CLIP的文本编码器提取为最终的文本特征: F t ∈ R 2 × C F_{t} \in R^{2 \times C} Ft∈R2×C。
对应的图像特征经图像编码器为: F c ∈ R 1 × C F_{c} \in R^{1 \times C} Fc∈R1×C。
state-level和template-level的集成实现, 使用CLIP文本编码器提取文本特征,并对正常和异常特征分别求平均值。最终,将正常与异常特征各自的平均值与图像特征进行对比,经过softmax后得到异常类别概率作为分类得分
s = s o f t m a x ( F c F t T ) s = softmax(F_{c}F_{t}^{T}) s=softmax(FcFtT)
最后选择 s s s 的第二维度作为异常检测分类问题的结果。
Anomaly Segmentation
类比图像级别的异常分类方法到异常分割,一个自然而然的想法是将Backbone提取到的不同层级特征与文本特征进行相似度度量。然而,CLIP模型是基于分类的方案进行设计的,即除了用于分类的抽象图像特征外,没有将其它图像特征映射到统一的图像/文本空间。因此我们提出了一个简单但有效的方案来解决这个问题:使用额外的线性层将不同层级的图像特征映射到图像/文本联合嵌入空间中,即linear layer去映射patch_tokens,然后基于每个patch_token去和文本特征做相似度计算,从而得到anomaly map。,见上图中蓝色Zero-shot Anomaly Map流程。具体地,不同层级的特征分别经由一个线性层进行联合嵌入特征空间变换,将得到的变换后的特征与文本特征进行对比,得到不同层级的异常图。最后,将不同层级的异常图简单加和求得最终结果。
Linear Layer的训练(CLIP部分的参数是冻结的)使用了focal loss和dice loss。
2-2 Few-shot AD
Anomaly Classification
对于few-shot设置,图像的异常预测来自两部分。第一部分与zero-shot设置相同。第二部分遵循许多AD方法中使用的常规方法,考虑anomaly map的最大值。所提方案将这两部分相加作为最终的异常得分。
Anomaly Segmentation
few-shot分割任务使用了memory bank,如图1中的黄色背景部分。
直白来说,就是查询样本和memory bank中的支持样本去做余弦相似度,再通过reshape得到anomaly map,最后再加到zero-shot得到的anomaly map上得到最后的分割预测。
另外在few-shot任务中没有再去fine-tune上文提到的linear layer,而是直接使用了zero-shot任务中训练好的权重。
3 Experiments

简单来说,在简单一些的图像中zero-shot和few-shot上效果差不多,但面对困难任务时,few-shot会改善一些。