我们准备使用python的requests和lxml库,直接安装完之后开始操作
目标爬取肖申克救赎信息->传送门
导入库
import requests
from lxml import etree
给出链接
url=‘https://movie.douban.com/subject/1292052/?tag=%E7%BB%8F%E5%85%B8&from=gaia_video’
获取网页html前端代码一行搞定,在requests中已经封装好了
data = requests.get(url).text
lxml库中封装了解析下载页面数据的函数
s = etree.HTML(data)
然后我们到豆瓣中获取需要爬取数据的xpath
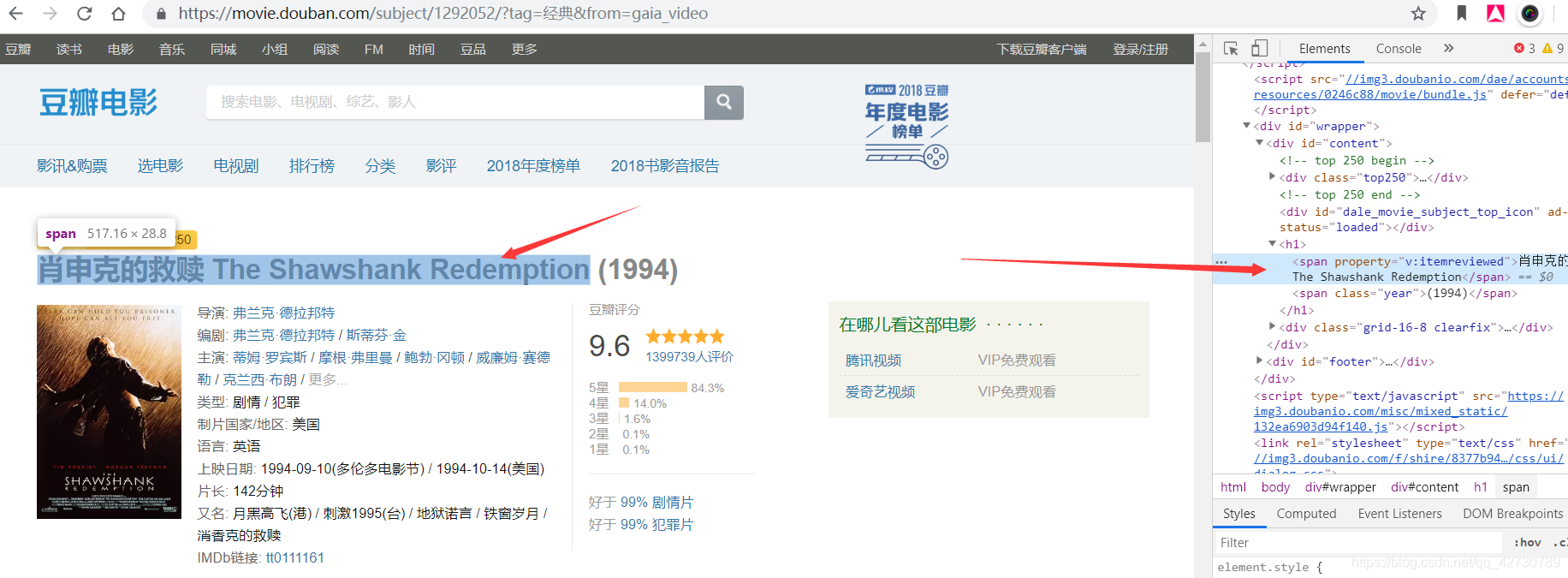
右键->copy->xpath我们就拿到了这样的一串数据
//*[@id="content"]/h1/span[1]
然后我们获取数据内容
film = s.xpath('//*[@id="content"]/h1/span[1]/text()')
注意最后面的/text()是获取文本类型的数据不然会出错
最后直接print(film)即可
完整代码如下
import requests
from lxml import etree
url = 'https://movie.douban.com/subject/1292052/?tag=%E7%BB%8F%E5%85%B8&from=gaia_video' # 定义url
data = requests.get(url).text # 获取全部html
s = etree.HTML(data)
film = s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
进阶
接下来我们想爬取主演
在演员上右键copy -> copy xpath
我们会有这样一串xpath
//*[@id="info"]/span[3]/span[2]/span[1]/a
//*[@id="info"]/span[3]/span[2]/span[2]/a
//*[@id="info"]/span[3]/span[2]/span[3]/a
……
我们发现这一组xpath似乎是封装在一个大的span标签之中,所以我们直接取拿span[2]里面的a/text()
actor = s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
我们获得了以下的运行结果,直接可以获取列表中的全部标签
