介绍
-
首先要知道为什么要聚类?
- 简来说:就是没有目标值,自己创造目标值
- 复杂说:通常聚类是做在分类之前的,当数据集没有目标值的时候,就只能通过聚类的方式,将一定量的样本化为一类,另外一部分样本再化为一类,然后这些样本所属于的类别就作为其样本的目标值,之后便在做常规的分类预测。
-
聚类算法之Kmeans的步骤(过程):
ps:先假设此时有1000个样本(点),要将其划分为3个类别(k=3)- 1、首先,就可以随机的在数据集中抽取三个点,当作三个类别的中心点(k1,k2,k3)
- 2、然后,计算出其余的点分别到这三个中心点的距离(欧式距离),即:每一个样本有了三个距离(a,b,c),从中选出距离最近的一个点作为自己的标记,如此便会形成三个族群。
- 3、分别计算这三个族群的平均值点。即:设族群单个点的坐标为(x,y),那么平均值点为((x1+…+xn)/n,y1+…+yn)/n),
- 4、然后拿三个平均值点和之前拟定的三个中心点做比较,如果全部相同,结束聚类,确定每个样本所属类别;如果不是全部相同,那么就把三个平均值点当作新的中心点,然后重复第二步。
- 补充:有关“距离(欧氏距离)”、“点”的概念可以参考:易懂:k-近邻算法
-
那样怎样才能说明聚类算法给样本划分类别划分的好?
- 聚类算法的性能评估指标(轮廓系数):
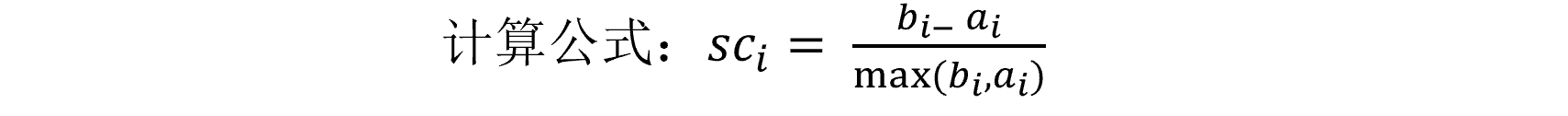
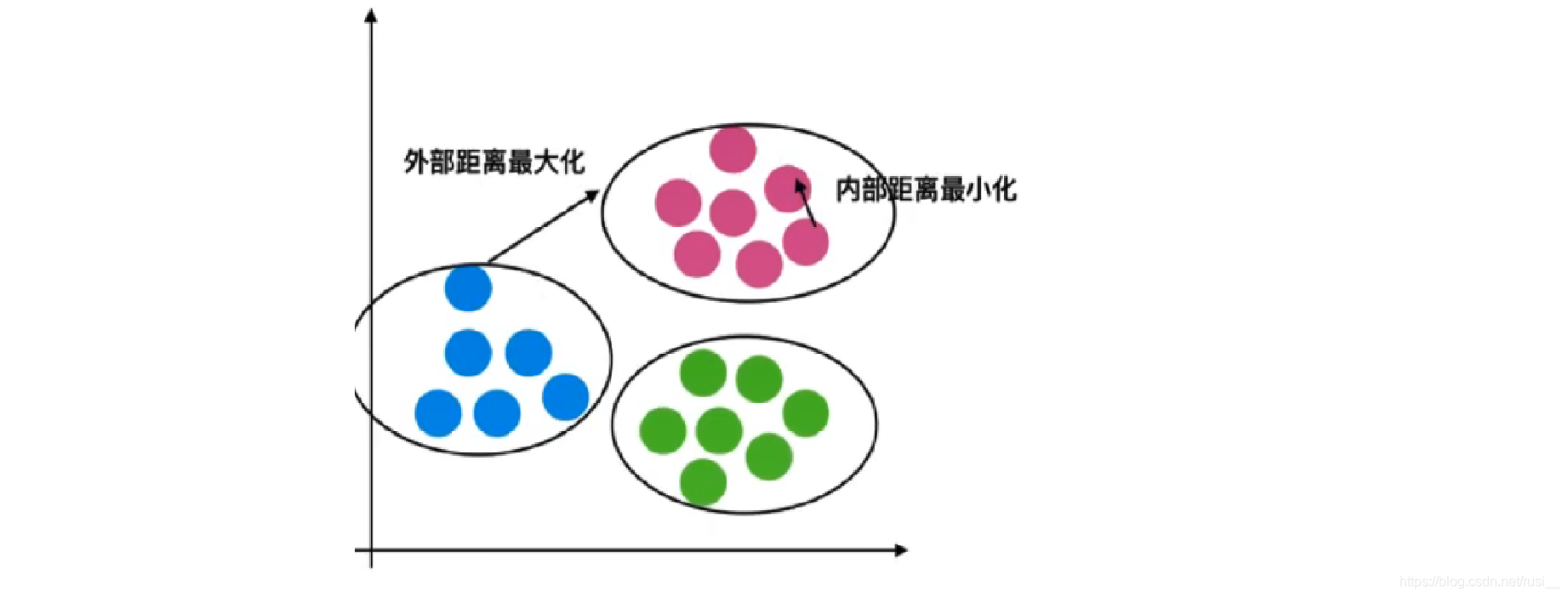
- 在公示介绍之前,先看一个图(抽象的性能评估指标示意图):
1、所谓外部距离最大化:指的是分类与分类之间相隔的距离(bi)越大越好。
2、所谓内部距离最小化:指的是每个分类中每个样本间的聚距离(ai)越小越好。
- 公式介绍:
0、假设分为了3类:A、B、C
1、每一个样本都有自己的轮廓系数。
2、A类中的某一个样本(a)到其它A的所有样本的距离的平均值记作 ai。
3、分别计算a到B类和C类所有样本的距离的平均值b1和b2,取两者最小的值bi。
4、此时即可:计算a的轮廓系数。
5、结合上图,从最优情况考虑:当bi >> ai 时 sci=1;如果最差情况考虑:当 bi << ai 时 sci = -1。
6、所以每个样本的轮廓系数都应该在-1到1之间。
7、于是乎:所有样本的轮廓系数的平均值越接近1的时候说明聚类的越好(其实只要超过了0,即使是0.1都已经很不错了,而且基本上超过不了0.7)。
8、可以通过调整所要分的类别数量的改变,来提高轮廓系数的平均值。
- 聚类算法的性能评估指标(轮廓系数):
关于聚类算法-KMeans算法的小总结:
- Kmeans优点:采用迭代式算法,直观易懂,非常实用。
- Kmeans缺点:选点可能选的不具有普遍性(3个点选的离太近了)(sklearn已经把这个问题解决了,使用的是多次随机选点聚类,取最优解(轮廓系数平均值最优)的方案)
相关API介绍:
- python实现聚类算法之Kmeans算法API:sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
- 重要参数介绍:n_clusters:开始的聚类中心数量(就是多少个类别);init:初始化方法,默认为’k-means ++’。
- python实现聚类算法的评估指标轮廓系数API: sklearn.metrics.silhouette_score(X, labels)
- 重要参数介绍:X:特征值(也就是参与聚类的所有样本(不可去掉某个特征值传入));labels:被聚类标记的目标值(也就是每个样本属于那个分类簇的标记值)。
